大文件上传是个非常普遍的场景,在面试中也会经常被问到,大文件上传的实现思路和流程。在日常开发中,无论是云存储、视频分享平台还是企业级应用,大文件上传都是用户与服务器之间交互的重要环节。随着现代网络应用的日益复杂化,大文件上传已经成为前端开发中不可或缺的一部分。
然而,在实现大文件上传时,我们通常会面临以下几个挑战:
-
上传超时:一般前端请求都会限制最大请求时长,比如axios设置timeout,或者是 nginx(或其它代理/网关) 限制了最大请求时长。
-
服务器压力:大文件上传会给服务器带来较大的压力,甚至可能导致服务器崩溃。
-
文件大小超限:一般后端都会对上传文件的大小做限制,比如nginx和server都会限制。
-
用户体验:上传过程中用户需要等待较长时间,用户体验差。
-
网络波动:各种网络原因导致上传失败,比如网络不稳定可能导致上传过程中断,且失败之后需要从头开始。
对于前三点,虽说可以通过一定的配置来解决,但有时候也相当麻烦,或者服务器就规定不允许上传大型文件,需要兼顾实际场景。上传慢的话倒是无伤大雅,忍一忍是可以接受的,只是体验不好,但是失败后在重头开始上传,在网络环境差的时候简直就是灾难。为了应对以上挑战,我们就需要用到切片上传、断点续传等技术手段。
二、实现思路分析
整体流程图如下:
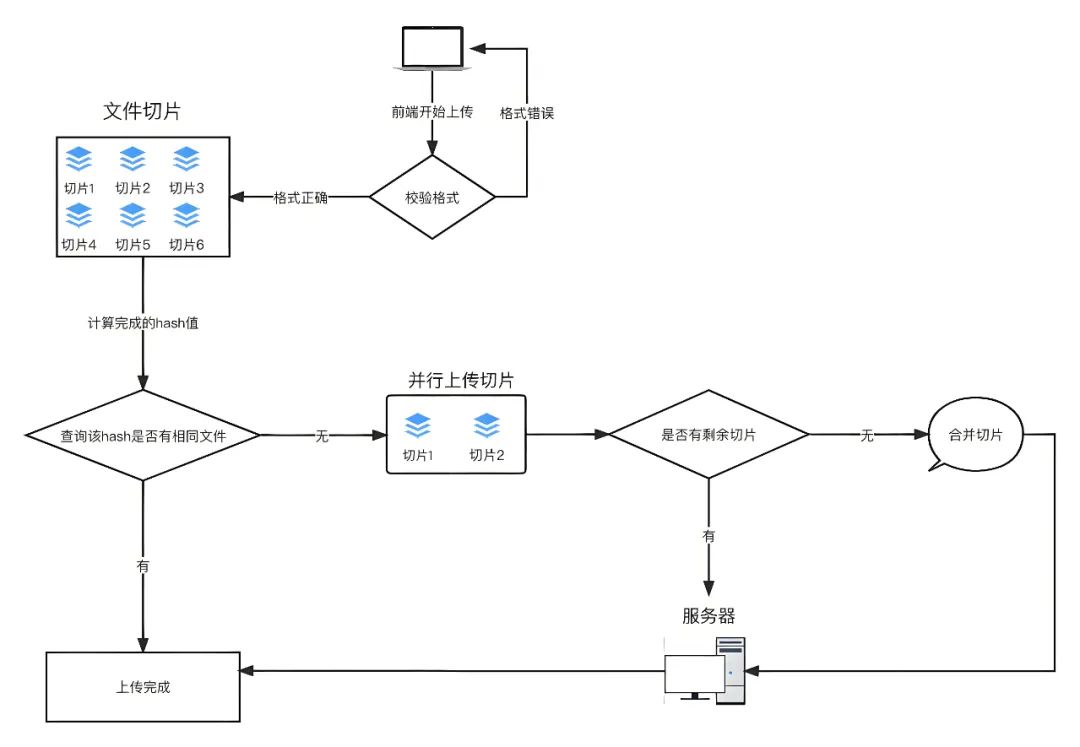
思路如下:
-
每个文件要有自己唯一的标识,因此在进行分片上传前,需要对整个文件进行MD5加密,生成MD5码,在后面上传文件每次调用接口时以formData格式上传给后端。可以使用spark-md5 计算文件的内容hash,以此来确定文件的唯一性将文件hash发送到服务端进行查询。以此来确定该文件在服务端的存储情况,这里可以分为三种:未上传、已上传、上传部分。
-
根据服务端返回的状态执行不同的上传策略。已上传:执行秒传策略,即快速上传,实际上没有对该文件进行上传,因为服务端已经有这份文件了。未上传、上传部分:执行计算待上传分块的策略并发上传还未上传的文件分块。当传完最后一个文件分块时,向服务端发送合并的指令,即完成整个大文件的分块合并,实现在服务端的存储。
上传过程:
-
分割文件:将要上传的文件切割成多个小文件片段。主要使用JavaScript的File API中的slice方法来实现。
-
上传文件分片:使用XMLHttpRequest或者Fetch API将分片信息以formData格式,并携带相关信息,如文件名、文件ID、当前片段序号等参数传给分片接口。
-
后端接收并保存文件片段:后端接收到每个文件片段后,将其保存在临时位置,并记录文件片段的序号、文件ID和文件MD5 hash值等信息。
-
续传处理:如果上传过程中断,下次继续上传时,通过查询后端已保存的文件片段信息,得知需要上传的文件片段,从断点处继续上传剩余的文件片段。
-
合并文件:当所有文件片段都上传完成后,后端根据文件ID将所有片段合并成完整的文件。
三、切片上传
切片上传原理:通过使用JavaScript的File API中的slice方法将大文件分割成多个小片段(chunk),然后逐个上传每个片段,在上传完切片后,前端通知后台再将文件片段拼接为一个完整的文件。
这样做的优点是可以并行多个请求一起上传文件,提高上传效率,并且在上传过程中如果某个片段因为某些原因上传失败,也不会影响其它文件切片,只需要重新上传该失败片段即可,不必重新上传整个文件。
实现思路:
在JavaScript中,文件File对象是Blob对象的子类,Blob对象包含了slice方法,通过这个方法,可以对二进制文件进行拆分。循环发送多个上传请求,然后返回结果后计数,当计数达到file片段长度后终止上传。
<input type="file" name="file" id="file" />const eleFile = document.getElementById('file');
eleFile.addEventListener('change', (event) => {
const file = event.target.files[0];
// 上传分块大小,单位Mb
const chunkSize = 1024 * 1024 * 1;
// 当前已执行分片数位置
let currentPosition = 0;
//初始化分片方法,兼容问题
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
while(currentPosition < file.size) {
const chunk = blobSlice.call(file, currentPosition, currentPosition + chunkSize);
uploadChunk(chunk);
currentPosition += chunkSize;
}
})
function uploadChunk(chunk) {
// 将分片信息以formData格式作为参数传给分片接口
let formData = new FormData();
formData.append('fileChunk', chunk);
// 根据项目实际情况
axios.post(
'/api/oss/upload/file',
formData,
{
headers: { 'Content-Type': 'multipart/form-data' },
timeout: 600000,
}
).then(res => {
// 上传成功
console.log('分片上传成功', res)
}).catch(error => {
// 上传失败
console.log('分片上传失败', error)
})
}四、并发上传
并发上传相对要优雅一下,将文件分割成小片段后,使用Promise.all()把所有请求都放到一个Promise.all里,它会自动判断所有请求都完成然后触发 resolve 方法。并发上传可以同时上传多个片段而不是依次上传,进一步提高效率。
实现思路:
1、使用slice方法对二进制文件进行拆分,并把拆分的片段放到chunkList里面。
2、使用map将chunkList里面的每个chunk映射到一个Promise上传方法。
3、把所有请求都放到一个Promise.all里,它会自动判断所有请求都完成然后触发 resolve 方法,上传成功后通知后端合并分片文件。
代码实现如下:
const eleFile = document.getElementById('file');
eleFile.addEventListener('change', (event) => {
const file = event.target.files[0];
// 上传分块大小,单位Mb
const chunkSize = 1024 * 1024 * 1;
// 当前已执行分片数位置
let currentPosition = 0;
// 存储文件的分片
let chunkList = [];
//初始化分片方法,兼容问题
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
while(currentPosition < file.size) {
const chunk = blobSlice.call(file, currentPosition, currentPosition + chunkSize);
chunkList.push(chunk);
currentPosition += chunkSize;
}
uploadChunk(chunkList, file.name)
})
function uploadChunk(chunkList, fileName) {
const uploadPromiseList = chunkList.map((chunk, index) => {
// 将分片信息以formData格式作为参数传给分片接口
let formData = new FormData();
formData.append('fileChunk', chunk);
// 可以根据实际的需要添加其它参数,比如切片的索引
formData.append('index', index);
// 根据项目实际情况
return axios.post(
'/api/oss/upload/file',
formData,
{
headers: { 'Content-Type': 'multipart/form-data' },
timeout: 600000,
}
)
})
Promise.all(uploadPromiseList).then(res => {
// 上传成功并通知后端合并分片文件
axios.post(
'/api/oss/file/merge',
{
message: fileName
},
{
headers: { 'Content-Type': 'application/json' },
timeout: 600000,
}
).then(data => {
console.log('文件合并成功', data)
})
}).catch(error => {
// 上传错误
console.log('上传失败', error)
})
}五、断点续传之1
断点续传允许在网络中断或其它原因导致上传失败时,从上次上传中断的位置继续上传,而不是重新从头上传整个文件。
实现断点续传需要后端配合记录上传的进度,并且在前端重新上传时,需要先查询已上传的进度,让后从断点处继续上传。
const eleFile = document.getElementById('file');
eleFile.addEventListener('change', (event) => {
const file = event.target.files[0];
// 上传分块大小,单位Mb
const chunkSize = 1024 * 1024 * 1;
// 当前已执行分片数位置
let currentPosition = 0;
// 存储文件的分片
let chunkList = [];
//初始化分片方法,兼容问题
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
while(currentPosition < file.size) {
const chunk = blobSlice.call(file, currentPosition, currentPosition + chunkSize);
chunkList.push(chunk);
currentPosition += chunkSize;
}
axios.post(
'/api/upload/file/history',
{
fileName: file.name
},
{
headers: { 'Content-Type': 'multipart/form-data' },
timeout: 600000,
}
).then(res => {
const historyChunks = res.uploadedChunks;
const remainChunks = chunkList.filter((item, index) => !historyChunks.includes(index));
// 并发上传剩余分片
uploadChunk(remainChunks, file.name)
})
})
function uploadChunk(chunkList, fileName) {
const uploadPromiseList = chunkList.map((chunk, index) => {
// 将分片信息以formData格式作为参数传给分片接口
let formData = new FormData();
formData.append('fileChunk', chunk);
// 可以根据实际的需要添加其它参数,比如切片的索引
formData.append('index', index);
// 根据项目实际情况
return axios.post(
'/api/oss/upload/file',
formData,
{
headers: { 'Content-Type': 'multipart/form-data' },
timeout: 600000,
}
)
})
Promise.all(uploadPromiseList).then(res => {
// 剩余分片上传成功并通知后端合并分片文件
axios.post(
'/api/oss/file/merge',
{
message: fileName
},
{
headers: { 'Content-Type': 'application/json' },
timeout: 600000,
}
).then(data => {
console.log('文件合并成功', data)
})
}).catch(error => {
// 上传错误
console.log('上传失败', error)
})
}以上是一个简易版的断点续传实现流程代码,但在实际场景应用中我们还需要更严谨的处理来实现断点续传功能。不如,上传文件前通常需要生成文件的唯一标识,比如文件名与文件大小的组合、文件的hash值或者文件hash值与文件大小的组合来支持断点续传的逻辑。请继续看下面的代码实现!!!
六、断点续传之2
已上传的执行秒传策略,即快速上传,实际上没有对该文件进行上传,因为服务端已经有这份文件了。
秒传的关键在于计算文件的唯一性标识。文件的不同不是命名的差异,而是内容的差异,所以我们将整个文件的二进制码作为入参,计算 Hash 值,将其作为文件的唯一性标识。一般而言,这样做就够了,但是摘要算法是存在碰撞概率的,我们如果想要再严谨点的话,可以将文件大小也作为衡量指标,只有文件摘要和文件大小同时相等,才认为是相同的文件。
<input type="file" name="file" id="file" @change="changeFile" />计算文件hash值可以使用spark-md5。
import SparkMD5 from 'spark-md5'通过input的change事件获取要上传的文件。
function changeFile(event) {
const file = event.target.files[0];
handleUploadFile(file, 1)
}接下来对文件进行分片和hash计算:
/**
* @param {File} file 目标上传文件
* @param {number} size 上传分块大小,单位Mb
* @returns {filelist:ArrayBuffer,fileHash:string}
*/
async function handleSliceFile(file, size = 1) {
return new Promise((resolve, reject) => {
// 上传分块大小,单位Mb
const chunkSize = 1024 * 1024 * size;
// 分片数
const totalChunkCount = file && Math.ceil(file.size / chunkSize);
// 当前已执行分片数位置
let currentChunkCount = 0;
// 存储文件的分片
let fileList = [];
//初始化分片方法,兼容问题
let blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
// 文件读取对象
const fileReader = new FileReader();
// spark-md5 计算文件hash值SparkMD5对象
const spark = new SparkMD5.ArrayBuffer();
// 存储计算后的文件hash值
let fileHash = "";
// 错误
fileReader.onerror = function () {
reject('Error reading file');
};
fileReader.onload = (e) => {
//当前读取的分块结果 ArrayBuffer
const curChunk = e.target.result;
//将当前分块追加到spark对象中
spark.append(curChunk);
currentChunkCount++;
fileList.push(curChunk);
//判断分块是否完成
if (currentChunkCount >= totalChunkCount) {
// 全部读取,获取文件hash
fileHash = spark.end();
resolve({ fileList, fileHash });
} else {
readNext();
}
};
//读取下一个分块
const readNext = () => {
//计算分片的起始位置和终止位置
const start = chunkSize * currentChunkCount;
let end = start + chunkSize;
if (end > file.size) {
end = file.size
}
//读取文件,触发onLoad
fileReader.readAsArrayBuffer(blobSlice.call(file, start, end))
}
readNext()
})
}文件上传,首选调用接口获取需要上传的文件index,返回的集合length等于0执行秒传,如果返回的集合length不等于0执行需要过滤得到需要上传的remainingChunks,使用map将remainingChunks里面的每个chunk映射为一个Promise上传方法,把所有请求都放到一个Promise.all里,上传成功后通知后端合并分片文件。
sync function handleUploadFile(file, chunkSize) {
const { fileList, fileHash } = await handleSliceFile(file, chunkSize);
// 存放切片
let chunkList = fileList;
// 显示上传的进度条
let process = 0;
// 获取文件上传状态
const { data } = await axios.post('/api/upload/file/history', {
fileHash,
totalCount: chunkList.length,
extname: file.name,
})
// 返回已经上传的
const { needUploadChunks } = data;
// 已上传,无待上传文件,秒传
if (!needUploadChunks.length) {
process = 100;
return;
}
// 此处包含了未上传和上传部分的情况
// 过滤剩余需要上传的分片序列
const remainingChunks = chunkList.filter((item, index) => needUploadChunks.includes(index + 1));
// 同步上传进度,断点续传情况下
progress = ((chunkList.length - needUploadChunks.length) / chunkList.length) * 100;
// 上传
if (remainingChunks.length) {
const uploadPromiseList = remainingChunks.map(async (chunk, index) => {
const response = await uploadChunk(chunk, index + 1, fileHash);
//更新进度
progress += Math.ceil(100 / allChunkList.length);
if (progress >= 100) progress = 100;
return response;
});
Promise.all(uploadPromiseList).then(() => {
// 清空已上传的切片
chunkList = [];
//发送请求,通知后端进行合并
axios.post(
'/api/file/merge',
{
fileHash,
extname: 'fileName.mp4'
},
{
headers: { 'Content-Type': 'multipart/form-data' },
timeout: 600000,
}
).then(res => {
console.log('合并完成', res)
}).catch(error => {
// 合并错误
console.log('合并错误', error)
})
}).catch(error => {
// 上传错误
console.log('上传错误', error)
})
}
}上传函数返回一个promise,参数为formData。
function uploadChunk(chunk, index, fileHash) {
// 将分片信息以formData格式作为参数传给分片接口
let formData = new FormData();
formData.append('fileChunk', new Blob([chunk]));
// 可以根据实际的需要添加其它参数,比如切片的索引
formData.append('index', index);
// 文件的标识hash值
formData.append('fileHash', fileHash);
// 根据项目实际情况
return axios.post(
'/api/upload/file',
formData,
{
headers: { 'Content-Type': 'multipart/form-data' },
timeout: 600000,
}
)
}我们在 fileReader 里面使用了 readAsArrayBuffer 方法做转换并分割,因此传入的chunk的类型是ArrayBuffer,而formData中文件的类型应该是Blob,所以需要时用new Blob() 将每一个chunk转为Blob类型。
七、总结
断点续传的重点是文件的切片与合并,整个上传流程需要前后端配合好,细节较多。
注意事项:
-
计算整个文件的 MD5 值,当大文件比较大时会比较慢,耗时,更好地做法是将这部分任务放在 Web Worker 中执行。Web Worker 是 HTML5 标准的一部分,它允许一段 JavaScript 程序运行在主线程之外的另外一个线程中。这样计算任务就不会影响到当前线程的渲染任务。可以和当前线程间使用 postMessage 的方式进行通讯。
-
可以根据文件切片的状态,发送上传请求,由于存在并发限制,需要限制 request 创建个数,避免页面卡死。
-
在上传大文件时,应提供适当的进度反馈和错误处理以确保良好的用户体验。
-
对于文件切片、并发上传和断点续传,后端需要能够接受文件片段,并能够处理并发请求和断点数据,因此需要合后端人员密切配合。



















