目录
- 一:背景
- 二:排查过程
- 2.1: SQL慢查询定位
- 2.2: Python层面分析将String翻译成Int类型的原因
- 2.3: Python进行SQL执行时间检测出现的问题
- 三:总结
一:背景
- 新的业务上线后, 合作部门发现我们引擎执行完, 回调他们的时间明显增大了, 让我们排查一下原因。
二:排查过程
2.1: SQL慢查询定位
-
首先追查日志, 发现有一个SQL的执行时间大概3分钟, 因此判断是慢查询的原因导致的。
-
执行SQL如下:
select overdue_total from nc_cases where status=0 and uid = 12345678990; -
检查SQL执行使用的索引, 发现没有用到 uid索引, 而是其使用了其他索引, 且扫描行数为500多万行。

-
查看uid的类型, 发现uid类型为varchar类型, 而自己使用的是数字, 因此导致索引失效。
-
将sql改成字符串类型, 再次查看是否使用索引, 以及扫描行数, 发现使用到了uid索引 且扫描行数为7行。

-
因此, 结果应该是自己写的sql中的uid类型不对, 导致的慢查询。
2.2: Python层面分析将String翻译成Int类型的原因
- 当前编写代码的方式, 发现即使自己%后面用的是str类型, 传进去也会变成int类型。
sql = "select overdue_total from nc_cases where status=0 and uid = %s" % str(uid) rows = db.collection.select(sql) - 调整编写代码的方式, 给%s 外层再套一层单引号, 测试后发现, 运行速度大大提升了。
sql = "select overdue_total from nc_cases where status=0 and uid = '%s'" % str(uid) rows = db.collection.select(sql) - 由于我使用的是DButils工具, 因此查询了一下官方写法
- 官方写法中, select语句不仅仅可以传递sql, 还可以传递一个values, 这个values中传递的是什么类型, 就会自动的将什么类型写入到SQL中。
- 例如下面的SQL, 列表中如果是字符串, 就会将这个字符串自动解析到sql语句中。这样类型不会发生改变。
sql = "select overdue_total from nc_cases where status=0 and uid = %s" rows = db.collection.select(sql, ["12345678990"])
2.3: Python进行SQL执行时间检测出现的问题
- 分析完问题后, 我们需要用python语句验证SQL执行的时间, 因子我写了一个脚本测试, 两个SQL的执行效率。
sql_3 = "select overdue_total from nc_cases where status=0 and xiaoying_uid = %s " % str(12345678990) sql_4 = "select overdue_total from nc_cases where status=0 and xiaoying_uid = '%s' " % str(12345678990) start_time3 = time.time() rows_3 = db.collection.select(sql_3) end_time3 = time.time() print(sql_3 + " use time is {}".format(end_time3 - start_time3)) start_time4 = time.time() rows_4 = db.collection.select(sql_4) end_time4 = time.time() print(sql_4 + " use time is {}".format(end_time4 - start_time4)) - 当我运行发现, 执行的时间差别并不大, 这是为什么呢?
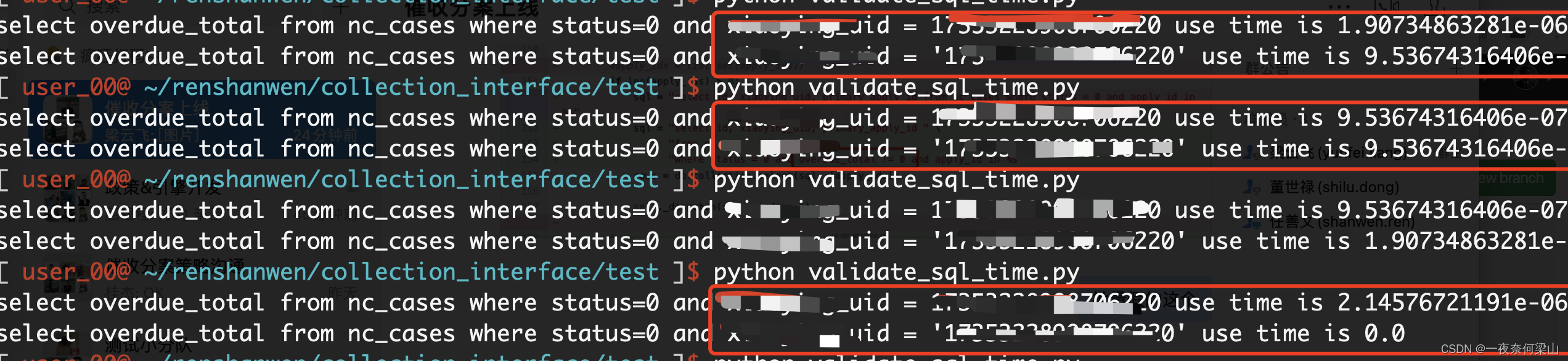
- 追查SQL工具的底层代码, 发现select()语句返回的是一个生成器对象, 在不遍历结果的条件下, 根本不会触发查询。

- 因此测试代码增加遍历语句
start_time3 = time.time() rows_3 = db.collection.select(sql_3) for row in rows_3: overdue_total = row[0] print(overdue_total) end_time3 = time.time() print(sql_3 + " use time is {}".format(end_time3 - start_time3)) start_time4 = time.time() rows_4 = db.collection.select(sql_4) for row in rows_4: overdue_total = row[0] print(overdue_total) end_time4 = time.time() print(sql_4 + " use time is {}".format(end_time4 - start_time4)) - 最终发现时间差别很大。

三:总结
- SQL慢查询问题, 首先使用explain定位使用的索引和扫描行数。
- python操作SQL语句的时候, 推荐使用官方标准格式。
- pyhton调用select语句的时候, 未必SQL就一定执行了, 如果select底层封装的是返回生成器对象, 则遍历的时候真正去数据库查询数据。