最近这一两周看到不少互联网公司都已经开始秋招提前批了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
《大模型面试宝典》(2024版) 发布!
《AIGC 面试宝典》圈粉无数!
喜欢本文记得收藏、关注、点赞。更多实战和面试交流,欢迎交流
近日,Meta 公开发布了 Llama 3.1 405B,为这是目前世界上最大、功能最强的开源基础模型。到目前为止,Llama的所有版本的下载量已超过3亿次。
介绍 Llama 3.1
Llama 3.1 405B 是第一个在通用知识、操控性、数学、工具使用和多语言翻译等方面达到当前先进水平的 AI 模型。随着 405B 模型的发布,我们将全力推动创新,带来前所未有的增长和探索机会。我们相信,新一代拉玛将引发新的应用和建模范式,包括合成数据生成,以帮助改进和训练较小的模型,以及模型蒸馏——这是在开源领域从未实现过的能力。
在此次最新版本中,我们推出了升级版的8B和70B模型。这些模型支持多种语言,上下文长度大幅提升至128K,具备最先进的工具使用能力和整体更强的推理能力。这使得我们的最新模型能够支持高级用例,如长篇文本摘要、多语言对话代理和编程助手等。我们还对许可证进行了更改,允许开发者使用Llama模型(包括405B)来改进其他模型。正如我们对开源的承诺,从今天起,我们将在llama.meta.com和Hugging Face上向社区开放这些模型的下载,并在我们的广泛合作伙伴平台生态系统上供立即开发使用。
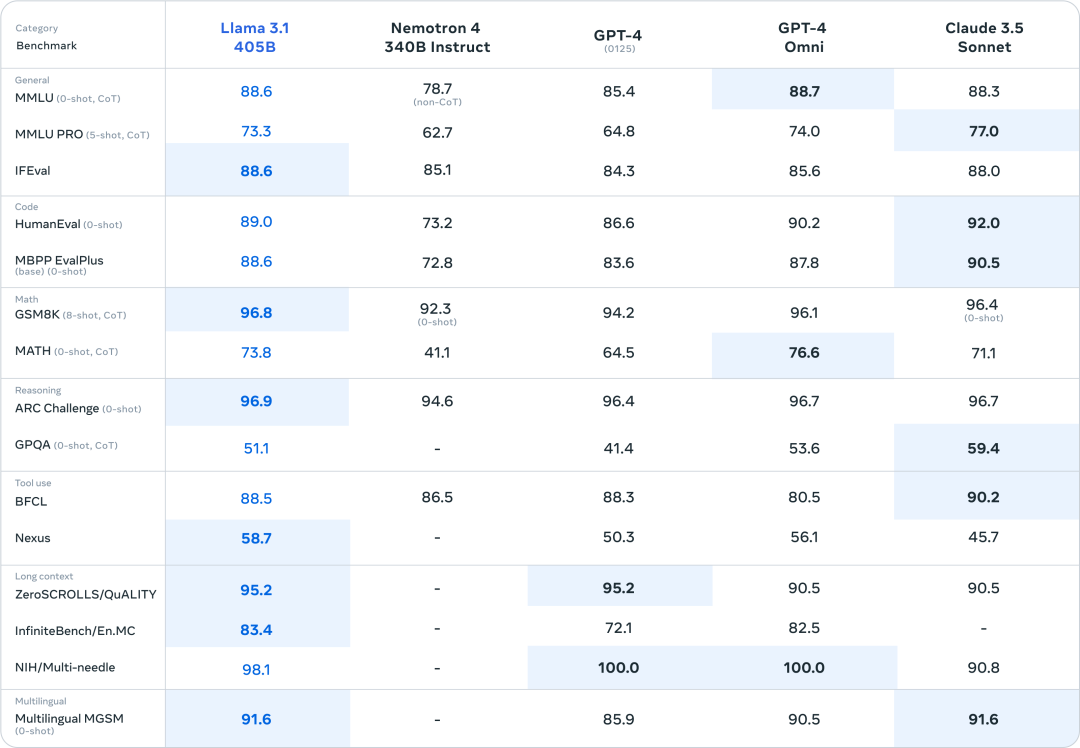
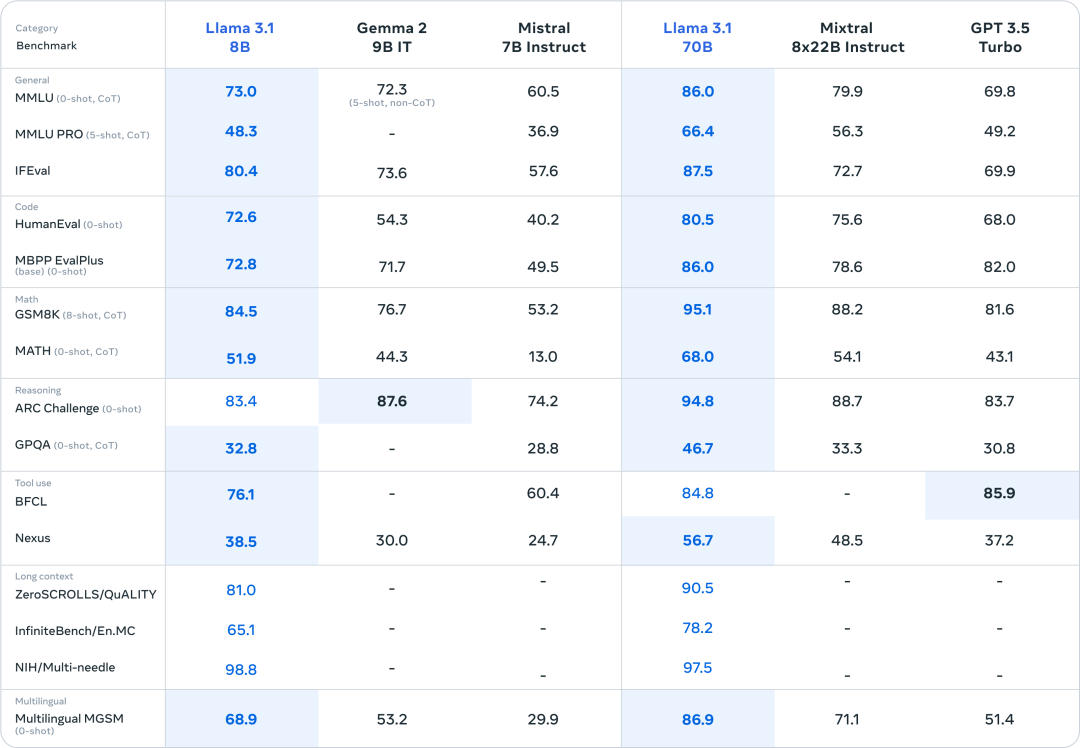
模型的评测
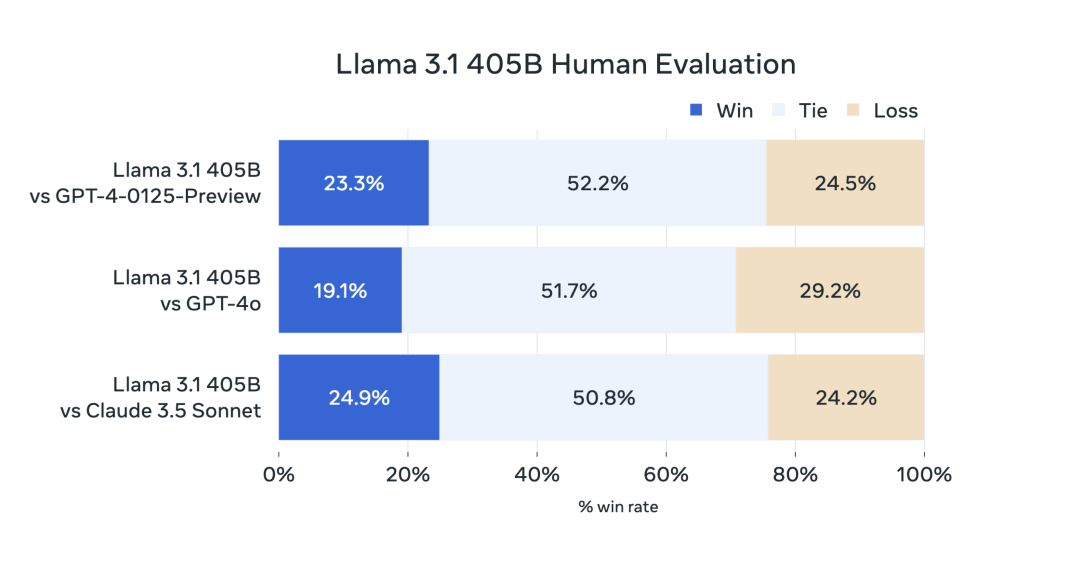
对于此次发布,我们对150多个涵盖多种语言的基准数据集进行了性能评估。此外,我们还进行了广泛的人工评估,在现实世界场景中比较Llama 3.1与竞争对手模型的表现。我们的实验评估表明,我们的旗舰模型在包括GPT-4、GPT-4o和Claude 3.5 Sonnet在内的多种任务上与领先的基础模型具有竞争力。此外,我们的较小模型与具有相似参数数的封闭和开放模型具有竞争力。
Model Architecture
As our largest model yet, training Llama 3.1 405B on over 15 trillion tokens was a major challenge. To enable training runs at this scale and achieve the results we have in a reasonable amount of time, we significantly optimized our full training stack and pushed our model training to over 16 thousand H100 GPUs, making the 405B the first Llama model trained at this scale.
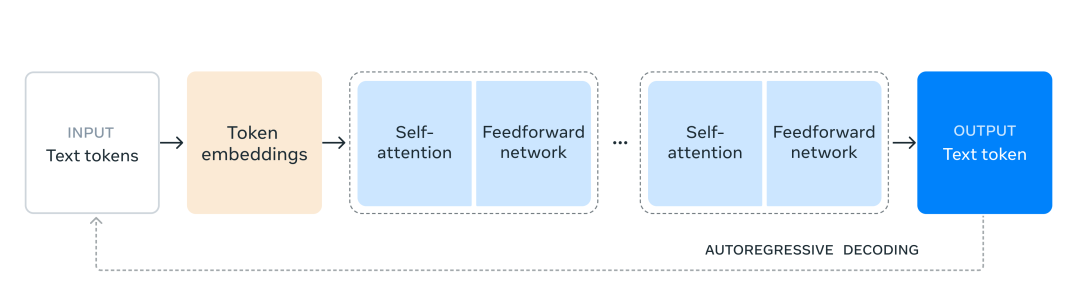
为了解决这个问题,我们做出了一些设计决策,旨在确保模型开发过程具有可扩展性和直观性。
-
我们选择了一种标准的仅包含解码器的变换器模型架构,并对其进行了一些微小的调整,以最大限度地提高训练的稳定性。
-
我们采用了迭代的后训练流程,每一轮都采用监督微调和直接偏好优化。这使我们能够为每一轮生成最高质量的合成数据,并提高每个能力的性能。
与之前的版本相比,我们在预训练和后训练的数据使用方面都提高了数据的数量和质量。这些改进包括开发更仔细的预处理和数据整理流程,以及更严格的质量保证和数据过滤方法。
正如预期的语言模型缩放定律那样,我们的新旗舰模型在性能上优于使用相同程序训练的较小模型。我们还使用405B参数模型来提升我们较小模型的后训练质量。
Instruction and chat fine-tuning
在Llama 3.1 405B版本中,我们致力于提高模型对用户指令的响应速度、质量和详细指令遵循能力,同时确保高水平的安全性。我们面临的最大挑战是支持更多的功能、128K上下文窗口和模型尺寸的增加。
在后训练阶段,我们通过在预训练模型之上进行多轮对齐来生成最终的聊天模型。每一轮都包括监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO)。我们使用合成数据生成来产生大多数的SFT示例,并多次迭代以生成所有功能的更高质量的合成数据。此外,我们还投资于多种数据处理技术,以过滤出最高质量的合成数据。这使我们能够在功能上扩展微调数据的数量。
我们仔细平衡数据,以在所有能力方面生成高质量的模型。例如,即使将上下文扩展到128K,我们仍会保持短上下文基准上的模型质量。同样,即使我们添加了安全缓解措施,我们的模型仍将继续提供最有帮助的答案。
The Llama system
羊驼模型(Llama models)的设计初衷是作为整体系统的一部分,以协调包括调用外部工具在内的多个组件。我们的愿景是超越基础模型,为开发人员提供更广泛的系统访问权限,使他们能够根据自己的愿景设计和创建定制化产品。这种思维始于去年,当时我们首次将核心LLM之外的组件纳入其中。
作为我们持续致力于在模型层之外负责任地开发人工智能并帮助他人这样做的一部分,我们正在发布一套完整的参考系统,其中包括几个示例应用程序和新的组件,如多语言安全模型“Llama Guard 3”和提示注入过滤器“Prompt Guard”。这些示例应用程序是开源的,社区可以基于它们进行构建。
这个Llama系统愿景中的组件实现仍然比较分散。因此,我们已经开始与行业、初创企业和更广泛的社区合作,以更好地定义这些组件的接口。为此,我们在GitHub上发布了一份“Llama栈”的征求意见稿。Llama栈是一套标准化且有倾向性的接口,用于构建标准的工具链组件(微调、合成数据生成)和有主动性的应用程序。我们的希望是这些接口能够在生态系统中得到采用,从而促进更便捷的互操作性。
我们欢迎反馈和改进提案的方法。我们很高兴能够促进Llama生态系统的发展,并降低开发者和平台提供商的进入门槛。
Openness drives innovation开放推动创新。
Unlike closed models, Llama model weights are available to download. Developers can fully customize the models for their needs and applications, train on new datasets, and conduct additional fine-tuning. This enables the broader developer community and the world to more fully realize the power of generative AI. Developers can fully customize for their applications and run in any environment, including on prem, in the cloud, or even locally on a laptop—all without sharing data with Meta.
While many may argue that closed models are more cost effective, Llama models offer some of the lowest cost per token in the industry, according to testing by Artificial Analysis. And as Mark Zuckerberg noted, open source will ensure that more people around the world have access to the benefits and opportunities of AI, that power isn’t concentrated in the hands of a small few, and that the technology can be deployed more evenly and safely across society. That’s why we continue to take steps on the path for open access AI to become the industry standard.
We’ve seen the community build amazing things with past Llama models including an AI study buddy built with Llama and deployed in WhatsApp and Messenger, an LLM tailored to the medical field designed to help guide clinical decision-making, and a healthcare non-profit startup in Brazil that makes it easier for the healthcare system to organize and communicate patients’ information about their hospitalization, all in a data secure way. We can’t wait to see what they build with our latest models thanks to the power of open source.
Building with Llama 3.1 405B
对于普通开发者来说,在405B这种规模上使用模型是具有挑战性的。尽管它是一个非常强大的模型,但我们认识到它需要大量的计算资源和专业知识才能使用。我们与社区进行了交流,并意识到生成式AI开发不仅仅是简单的模型提示。我们希望让每个人都能充分利用405B,包括:
-
实时和批量推理
-
Supervised fine-tuning 监督微调
-
针对您特定应用场景对模型进行评估
-
Continual pre-training 持续预训练
-
Retrieval-Augmented Generation (RAG)检索增强生成(RAG)
-
Function calling 函数调用
-
Synthetic data generation
这就是Llama生态系统所能提供的帮助。从第一天开始,开发者就可以利用405B模型的所有高级功能并立即开始开发。开发者还可以探索诸如易于使用的合成数据生成等高级工作流程,遵循现成的指导来进行模型精简,并通过合作伙伴提供的解决方案实现无缝RAG(推理加速),包括AWS、NVIDIA和Databricks。此外,Groq已针对云部署优化了低延迟推理,戴尔也在本地系统上实现了类似的优化。
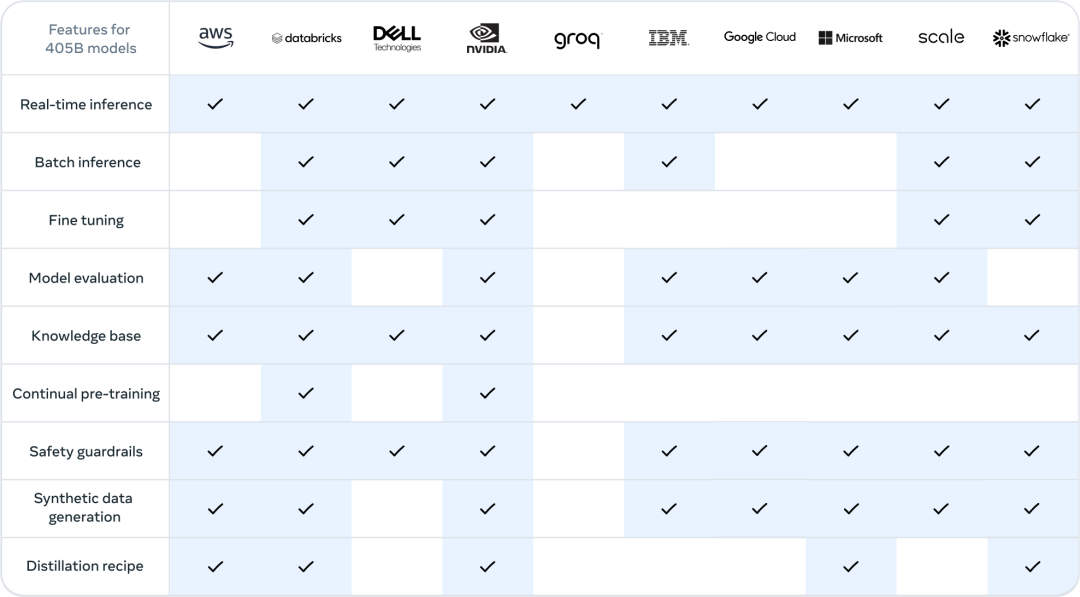
我们与诸如vLLM、TensorRT和PyTorch等关键社区项目合作,从一开始就为社区做好支持工作,确保社区做好了生产部署的准备。
我们希望405B的发布也能激发整个社区的创新,使大规模模型的推理和微调变得更加容易,从而推动下一波模型压缩研究的发展。
今天就试试Llama 3.1系列模型吧!
我们迫不及待地想看看社区会如何利用这项工作。利用多语言性和增加的上下文长度,可以构建许多有用的新体验。有了Llama Stack和新的安全工具,我们期待与开放源码社区继续负责任地合作。在发布模型之前,我们会通过多种措施进行识别、评估和缓解潜在风险,包括通过红队进行预部署风险发现演练,以及进行安全微调。例如,我们与外部和内部专家进行了广泛的红队演练,以对模型进行压力测试,并找出它们可能被意外使用的方式。(有关我们在负责任地扩展Llama 3.1模型集方面的更多信息,请参阅此博文。)
虽然这是我们目前最大的模型,但我们相信未来仍有许多新的领域值得探索,包括更适合设备的尺寸、更多的模态以及在代理平台层上的更多投资。一如既往,我们期待看到社区利用这些模型构建的令人惊叹的产品和体验。
This work was supported by our partners across the AI community. We’d like to thank and acknowledge (in alphabetical order): Accenture, Amazon Web Services, AMD, Anyscale, CloudFlare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM WatsonX, Infosys, Intel, Kaggle, Microsoft Azure, NVIDIA DGX Cloud, OctoAI, Oracle Cloud, PwC, Replicate, Sarvam AI, Scale.AI, SNCF, Snowflake, Together AI, and UC Berkeley - vLLM Project.