零、前情提要
最近需要分析全球范围多变量的数值预报数据,将grb格式的数据下载下来经过一通处理后需要将预处理数据先保存一遍,方便后续操作,处理完发现此时的数据维度很多,数据量巨大,使用不同的保存策略的解析难度和储存大小可以相差很大,在此分享下不同存储方式的差异
对比发现,使用ZARR储存高维度大型气象矩阵的储存成本最低,相比于使用pkl存储字典数据小近十倍!
一、两种数据存储策略
1.1 预处理成字典存储
按日期读取各个模式数据,依次提取出各个变量,一个变量一个数组
{
'20240701': {
'ec': {
'T': [],
'rh': [],
},
'necp': {
'T': [],
'rh': [],
}
},
'20240702': {
'ec': {
'T': [],
'rh': [],
},
'necp': {
'T': [],
'rh': [],
}
},
}
1.2 预处理为数组存储
预报数据维度
F
(
T
,
m
o
d
e
l
s
,
v
a
r
i
a
b
l
s
,
p
r
e
s
s
u
r
e
s
,
l
a
t
,
l
o
n
)
F(T, models, variabls, pressures, lat, lon)
F(T,models,variabls,pressures,lat,lon)
观测场数据维度
O
(
T
,
m
o
d
e
l
s
,
p
r
e
s
s
u
r
e
s
,
l
a
t
,
l
o
n
)
O(T, models, pressures, lat, lon)
O(T,models,pressures,lat,lon)
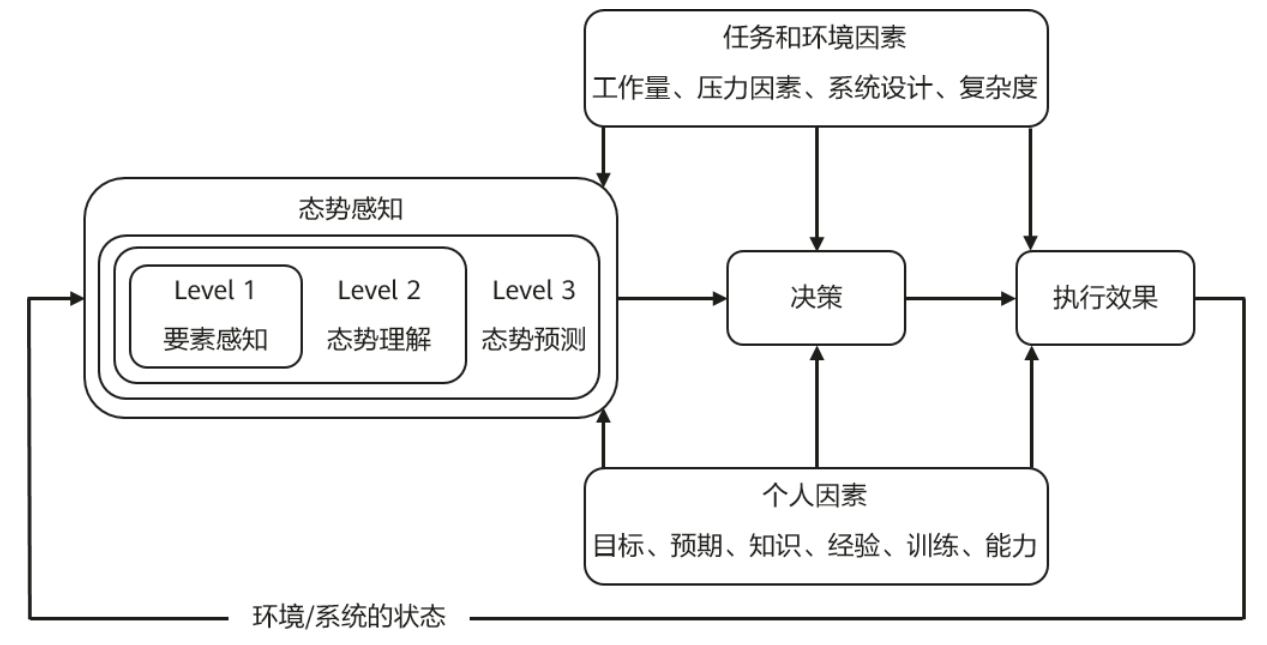
T为时间数,models为模型数量,variables为变量,pressures为气压层,后面两者为经纬度,使用的0.25度分辨率的全球数据,数据量是相当大的
二、pkl储存
- pkl的特点是可以直接储存python的字典,读取和存储都非常方便
- 但是占用的文件大小相对很大
2.1 储存策略
pkl擅长储存python字典数据
res = {
'20240701': {
'ec': {
'T': [],
'rh': [],
},
'necp': {
'T': [],
'rh': [],
}
},
'20240702': {
'ec': {
'T': [],
'rh': [],
},
'necp': {
'T': [],
'rh': [],
}
},
}
2.2 储存和读取方式
import pickle as pkl
# 存储pkl
def save2pkl(data, save_filepath):
with open(save_filepath, 'wb') as file:
pickle.dump(data, file)
print('finish saving')
def read_pkl(filepath):
with open(filepath, 'rb') as file:
data = pkl.load(file)
return data
2.3 储存大小
结果是使用pkl储存出来的数据量巨大,两个时段的数据量达到3G,是无法接受的

三、HDF5存储
HDF5既可以通过group的形式储存字典,也可以直接存储numpy数组
3.1 储存策略1(存储大数组)
def save2hdf5(save_filepath, data, compression='gzip'):
with h5py.File(save_filepath + '.hdf5', 'w') as hf:
hf.create_dataset('data_name', data=data, compression=compression)
print('finish saving')
3.2 储存策略2(存储字典)
以上面这个字典为例,通过遍历这个字典的k,v循环存储,需要不断创建group来形成字典的树状结构
data= {
'20240701': {
'ec': {
'T': [],
'rh': [],
},
'necp': {
'T': [],
'rh': [],
}
},
'20240702': {
'ec': {
'T': [],
'rh': [],
},
'necp': {
'T': [],
'rh': [],
}
},
}
def save2hdf5(save_filepath, data, compression='gzip'):
with h5py.File(save_filepath , 'w') as file:
for date, models in data.items():
date_group = file.create_group(date)
for model, variables in models.items():
model_group = date_group.create_group(model)
for var_name, var_data in variables.items():
model_group.create_dataset(var_name, data=var_data, compression=compression)
print('finish saving')
这样是针对当前字典写死的代码,还可以用递归解决
def save_dict_to_hdf5(group, data_dict, compression):
for key, value in data_dict.items():
if isinstance(value, dict):
# 创建一个新的 HDF5 组
subgroup = group.create_group(key)
# 递归调用
DataReaderDict.save_dict_to_hdf5(subgroup, value, compression)
else:
# 直接保存数据到 HDF5 数据集中
group.create_dataset(key, data=value, compression=compression)
def save2hdf5(data, save_filepath , compression='gzip'):
with h5py.File(save_filepath + 'hdf5', 'w') as hdf5_file:
root_group = hdf5_file.create_group('root')
save_dict_to_hdf5(root_group, data, compression)
3.3 设置压缩策略
在 HDF5 中,压缩策略有几种常见的方法,可以用来减少数据存储空间的需求,通过compression参数设置(来自GPT):
-
gzip: 这是最常用的压缩方法,它使用 DEFLATE 算法进行压缩。Gzip 在压缩率和压缩速度之间提供了一个良好的平衡。可以通过设置压缩级别来调整压缩的强度。
-
szip: 这是 HDF5 提供的另一种压缩方法,特别适用于具有大的数据块的情况。Szip 能够提供更高的压缩比,但可能会比 Gzip 更慢。
-
lzf: 这种压缩算法提供了更快的压缩和解压缩速度,但压缩比通常不如 Gzip 或 Szip 高。它适用于需要快速访问压缩数据的场景。
-
None: 不进行任何压缩。这种策略适用于当压缩不必要或影响性能时的情况
3.4 读取HDF5返回字典
读取方式:通过递归遍历group形成一个dict
def read_hdf5_group(group):
"""
递归读取 HDF5 组及其所有子组和数据集
"""
result = {}
for key, item in group.items():
if isinstance(item, h5py.Group):
# 如果是组,递归调用
result[key] = read_hdf5_group(item)
elif isinstance(item, h5py.Dataset):
# 如果是数据集,直接读取数据
result[key] = item[:]
return result
def read_hdf5(file_path):
"""
读取 HDF5 文件,返回字典表示的数据结构
"""
try:
with h5py.File(file_path, 'r') as file:
# 从根组开始递归读取数据
data = read_hdf5_group(file)
return data
except FileNotFoundError as e:
print(e)
return None
filepath = r'E:\pythonProject\superensemble\data\combined_data\20240721-20240722-00-24_dict.hdf5'
data = read_hdf5(filepath)
print("a")
3.5 储存大小
-
使用gzip默认的压缩等级4进行存储,存储字典的大小为1.04GB

-
储存数组的大小为777MB

-
在相同的压缩方式下,直接存储数组的数据大小更小
四、ZARR存储
4.1 储存策略1(储存字典)
递归调用储存
import zarr
def save2zarr(data, save_filepath ):
zarr_store = zarr.DirectoryStore(save_filepath)
root = zarr.open(zarr_store, mode='w')
self.store_dict_to_zarr(root, data)
def store_dict_to_zarr(root, data_dict):
for key, value in data_dict.items():
if isinstance(value, dict):
# 如果值是字典,则创建一个组
if key not in root:
root.create_group(key)
DataReaderDict.store_dict_to_zarr(root[key], value) # 递归处理子字典
else:
# 否则,假设值是数组,创建数据集
root.create_dataset(key, data=value)
4.2 储存策略2(储存大数组)
直接保存一个数组的方式如下
import zarr
import numpy as np
# 创建一个新的 Zarr 数组
zarr_array = zarr.open('data.zarr', mode='w',
shape=(100, 100), dtype='f4', chunks=(10, 10))
# 填充数据
data = np.random.random((100, 100))
zarr_array[:] = data
在参数中需要填写数组的维度,存储的数据类型以及分块,压缩策略等等
4.3 设置数据分块以及压缩
Zarr 支持多种压缩算法,如 zlib, gzip, bzip2, lz4, 和 zstd,可以在创建 Zarr 数组时指定压缩方式和参数
import zarr
import numpy as np
# 创建一个带有分块和压缩的 Zarr 数组
compressor = zarr.Blosc(cname='zstd', clevel=3, shuffle=2) # 使用 zstd 压缩
zarr_array = zarr.open('compressed_data.zarr', mode='w', shape=(100, 100, 100), dtype='f4',
chunks=(10, 10, 10), compressor=compressor)
# 填充数据
data = np.random.random((100, 100, 100))
zarr_array[:] = data
4.4 读取zarr返回字典
与读取hdf5类似,通过递归遍历group返回字典
import zarr
def read_zarr_group(group):
"""
递归读取 Zarr 组及其所有子组和数据集
"""
result = {}
for key, item in group.items():
if isinstance(item, zarr.Group):
# 如果是组,递归调用
result[key] = read_zarr_group(item)
elif isinstance(item, zarr.Array):
# 如果是数组,直接读取数据
result[key] = item[:]
return result
def read_zarr(file_path):
"""
读取 Zarr 文件,返回字典表示的数据结构
"""
try:
store = zarr.DirectoryStore(file_path)
root_group = zarr.open(store, mode='r')
# 从根组开始递归读取数据
data = read_zarr_group(root_group)
return data
except FileNotFoundError as e:
print(e)
return None
filepath = 'your filepath'
data = read_zarr(filepath)
4.5 储存大小
相同的数据,如果以字典存储,即使用zarr,也有882MB

但如果合理读取成一个大数组,则只有378MB,远远小于存储字典

五、小节
- 对比发现使用zarr存储高纬度的网格数据占用的空间最小,容量为用pkl存储字典的1/10,一旦时间维度拉长使用字典存储的占用可能会大大增加
- 对于时间序列的气象数据,预处理阶段处理成矩阵数组比处理成字典更加省空间且在下一阶段的操作更方便
- 在下一阶段的计算方面,使用多维矩阵也可以方便选出各种数据,同时使用矩阵运算运用numpy的一些方法可以大大减少各种循环,非常高校
- 因此,数据维度较为规整的情况下,尽量读取储存成矩阵数组的形式我认为更优