Transformer中的Multi-head Attention机制解析——从单一到多元的关注效益最大化
Multi-head Attention的核心作用
| 组件/步骤 | 描述 |
|---|---|
| 多头注意力机制(Multi-head Attention) | Transformer模型中的关键组件,用于处理序列数据 |
| 功能 | 允许模型同时关注到序列中不同位置的信息,提取更丰富和多样的特征 |
| 实现方式 | 1. 将原始输入数据分成多个头(子集) |
| 2. 对每个头分别进行注意力计算 | |
| 3. 将各个头的输出合并,得到最终输出结果 |
其基本公式如下:
MultiHead
(
Q
,
K
,
V
)
=
Concat
(
head
1
,
.
.
.
,
head
h
)
W
O
\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O
MultiHead(Q,K,V)=Concat(head1,...,headh)WO
where
head
i
=
Attention
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
\text{where } \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
where headi=Attention(QWiQ,KWiK,VWiV)
其中, Q , K , V Q, K, V Q,K,V 分别代表查询(Query)、键(Key)和值(Value)向量, W i Q , W i K , W i V W_i^Q, W_i^K, W_i^V WiQ,WiK,WiV 是各个头对应的权重矩阵, W O W^O WO 是输出时的权重矩阵, h h h 是头的数量。
| 项目 | 描述 |
|---|---|
| 查询向量 | Q Q Q,是我们想要关注的重点信息。 |
| 键向量 | K K K,是与查询向量进行匹配的信息。 |
| 值向量 | V V V,是与键向量相对应的实际信息内容。 |
| 多头 | h h h,表示将输入分成多少个头进行并行处理。 |

通俗解释与案例
-
Multi-head Attention的核心思想
- 想象一下,你在看一张照片,你想要同时关注到照片中的多个人或物。多头注意力机制就是让你能够同时关注到多个不同的部分,然后综合这些信息来做出判断。
- 比如,在处理一句话时,多头注意力机制可以同时关注到句子中的主语、谓语和宾语,从而更好地理解句子的意思。
-
Multi-head Attention的应用
- 在Transformer模型中,Multi-head Attention被用于编码器和解码器之间,以及编码器内部和解码器内部的信息交互。
- 通过多头注意力机制,Transformer能够捕捉到序列数据中的长距离依赖关系,从而提高模型的性能。
-
Multi-head Attention的优势
- 多头注意力机制允许模型同时关注到不同位置的信息,从而提高了模型的表达能力和泛化能力。
- 通过并行处理多个头,多头注意力机制还可以在一定程度上提高模型的计算效率。
-
Multi-head Attention的类比
- 你可以把多头注意力机制比作一个拥有多个眼睛的怪物。每个眼睛都可以独立地观察周围的世界,并将观察到的信息传递给大脑。大脑则综合这些信息来做出决策。
具体来说:
| 项目 | 描述 |
|---|---|
| 查询向量 | Q Q Q,就像是你想要了解的问题或关注点。 |
| 键向量 | K K K,就像是回答你问题的关键信息。 |
| 值向量 | V V V,就像是与关键信息相对应的实际内容。 |
| 多头 | h h h,就像是你同时用多个眼睛去观察世界。 |
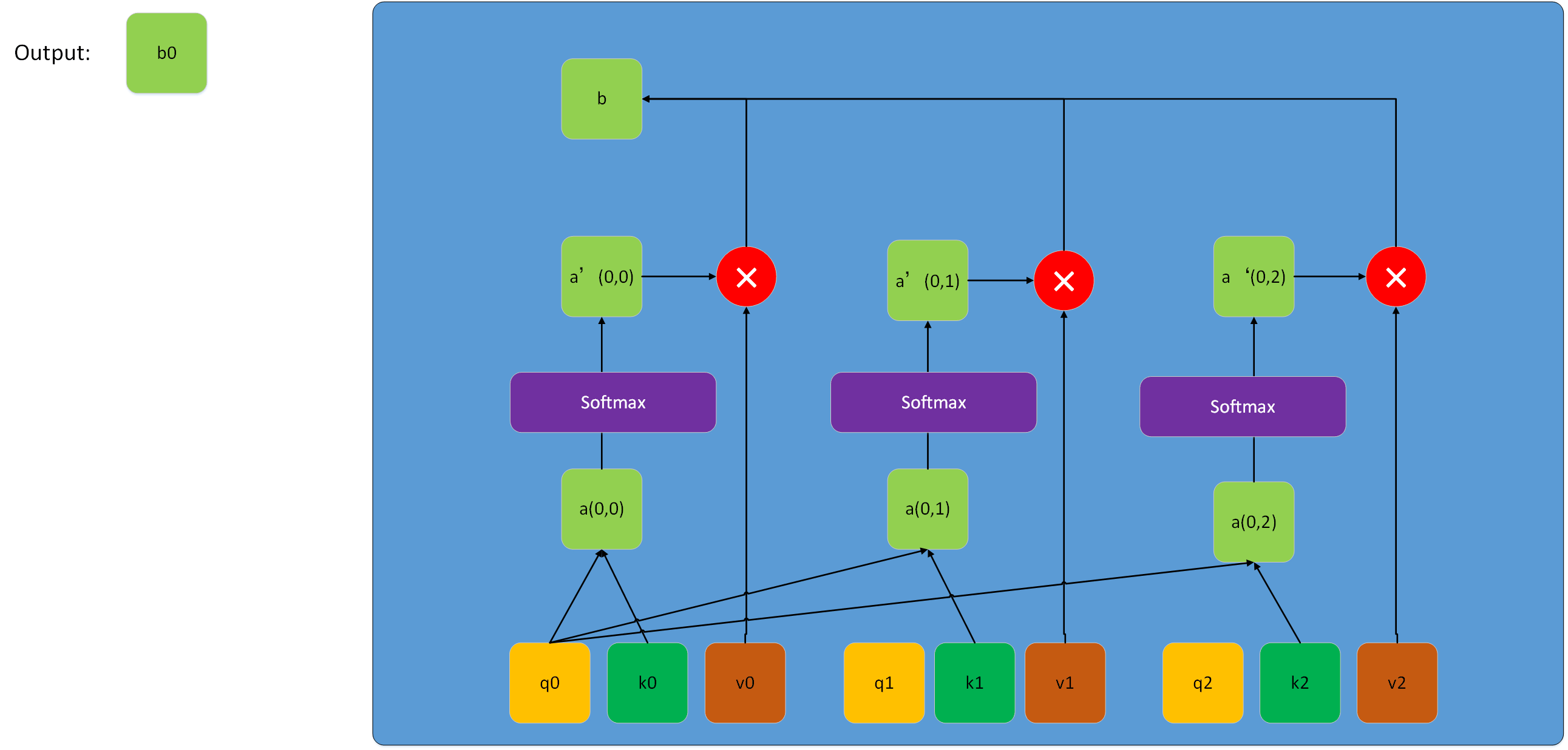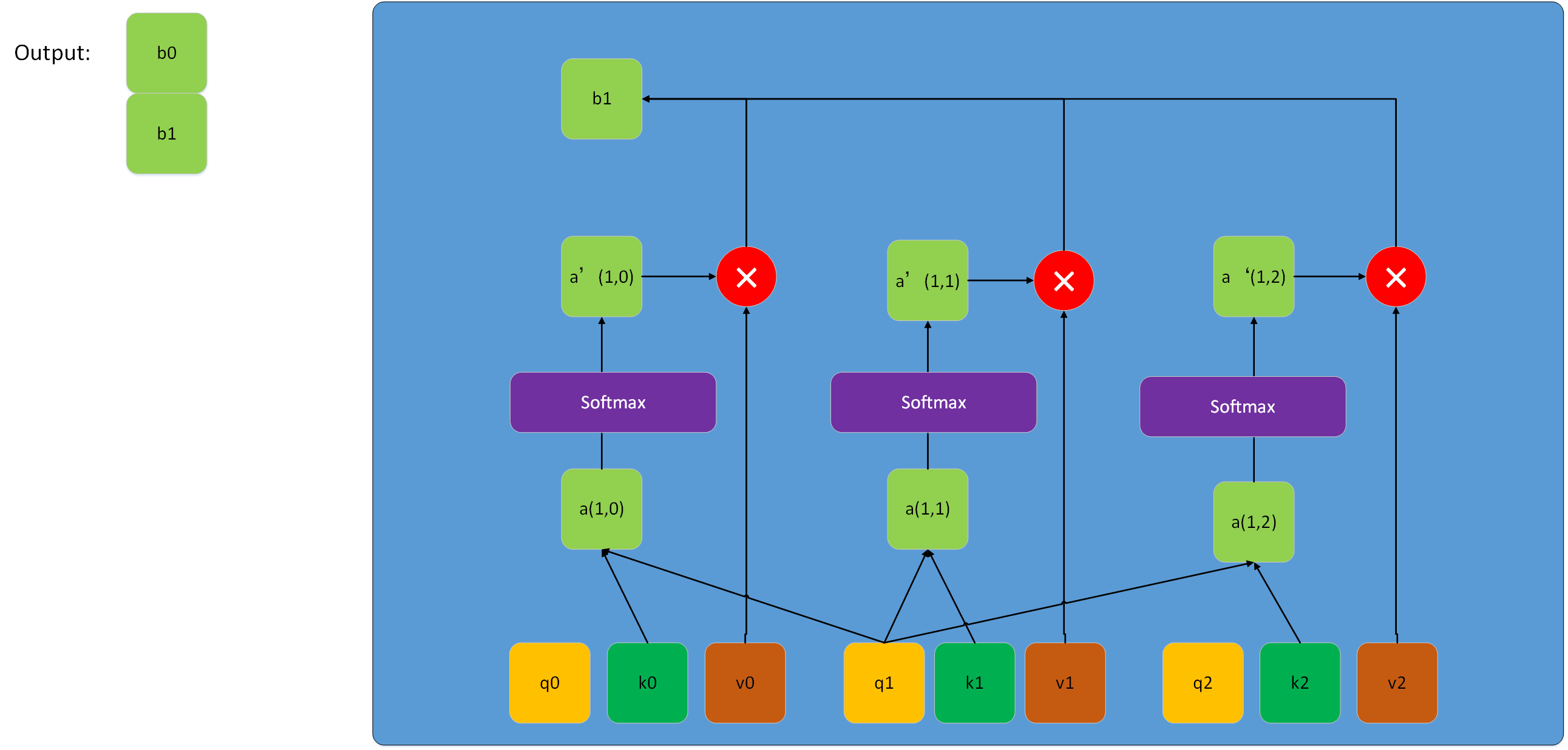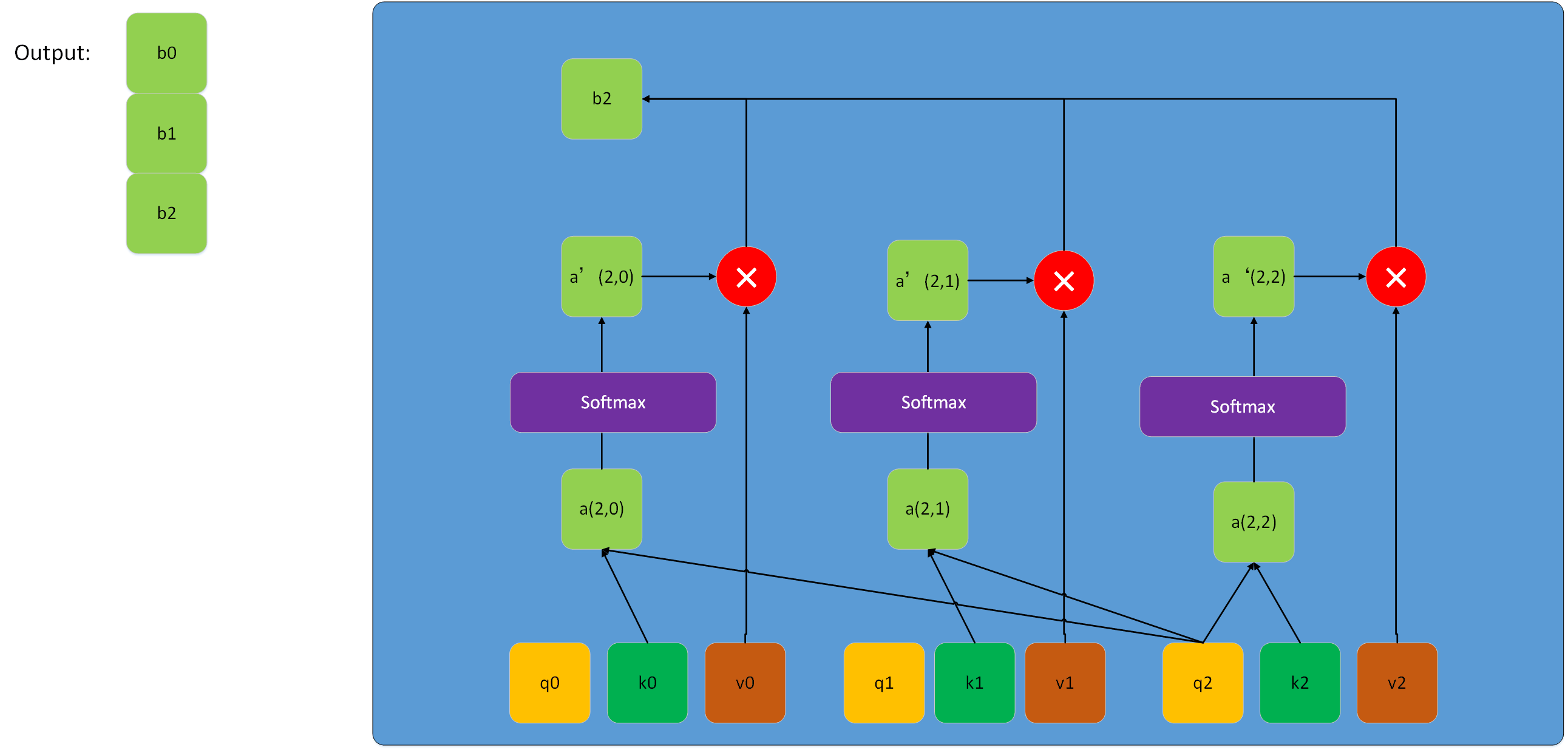
公式探索与推演运算
-
基本公式:
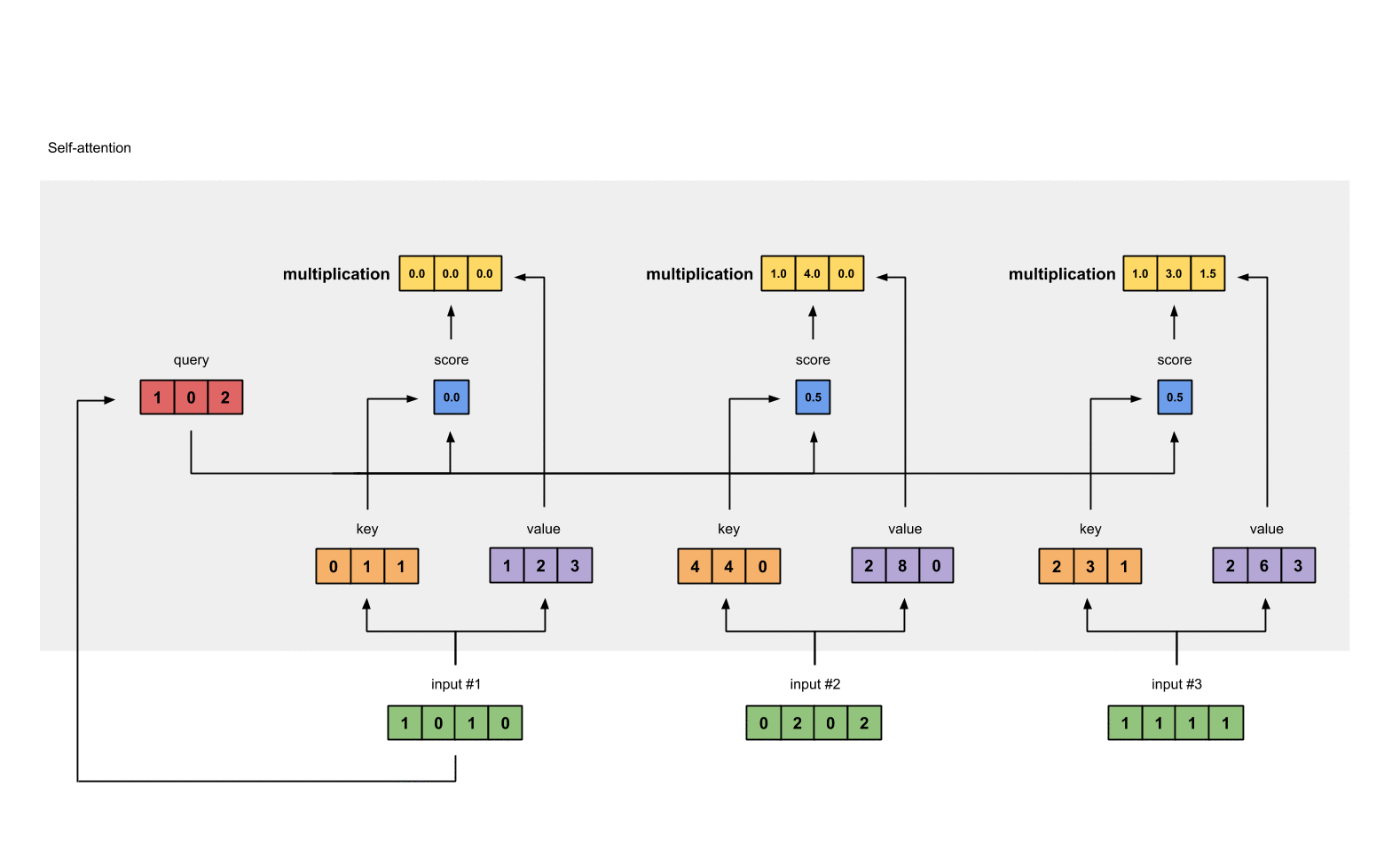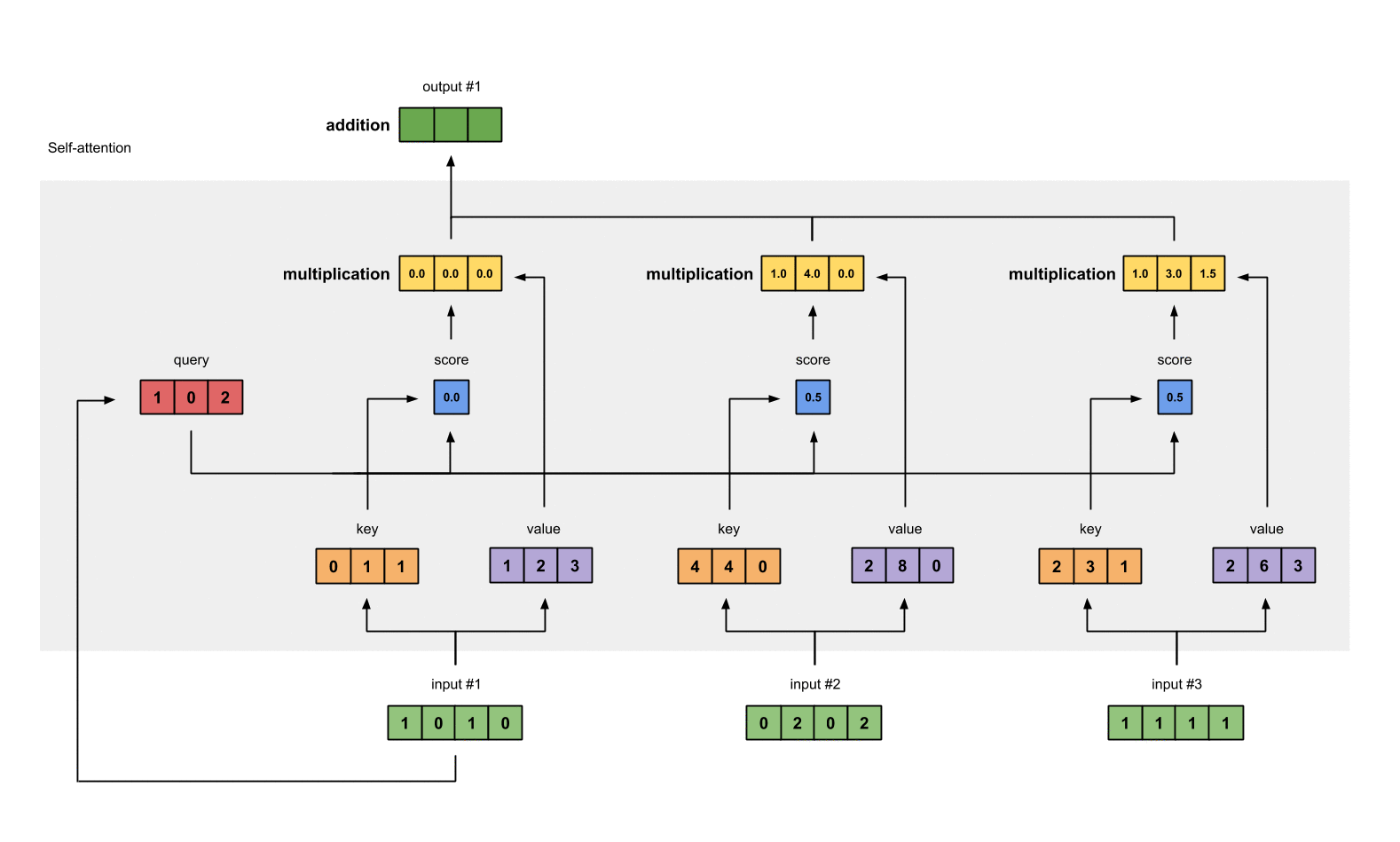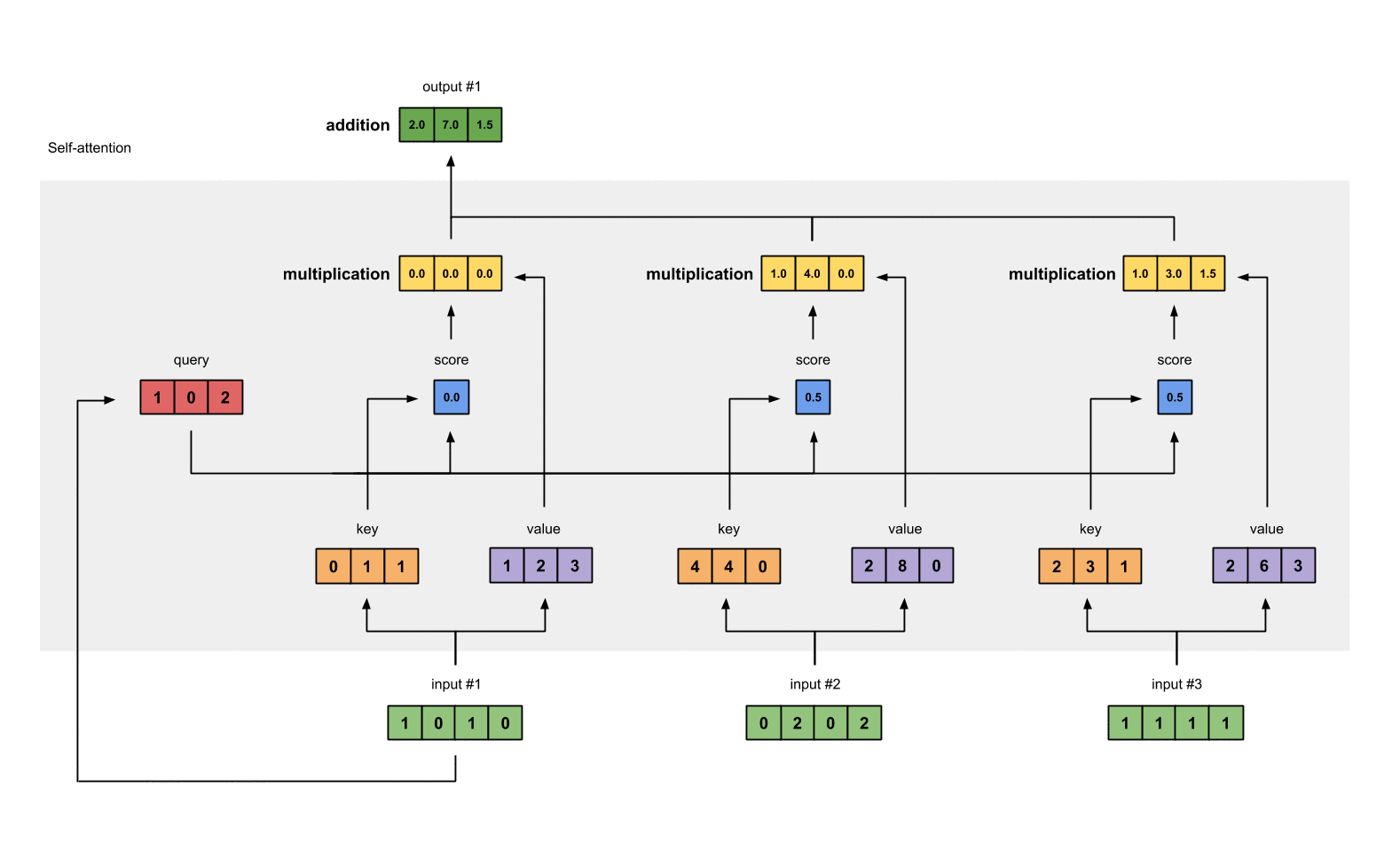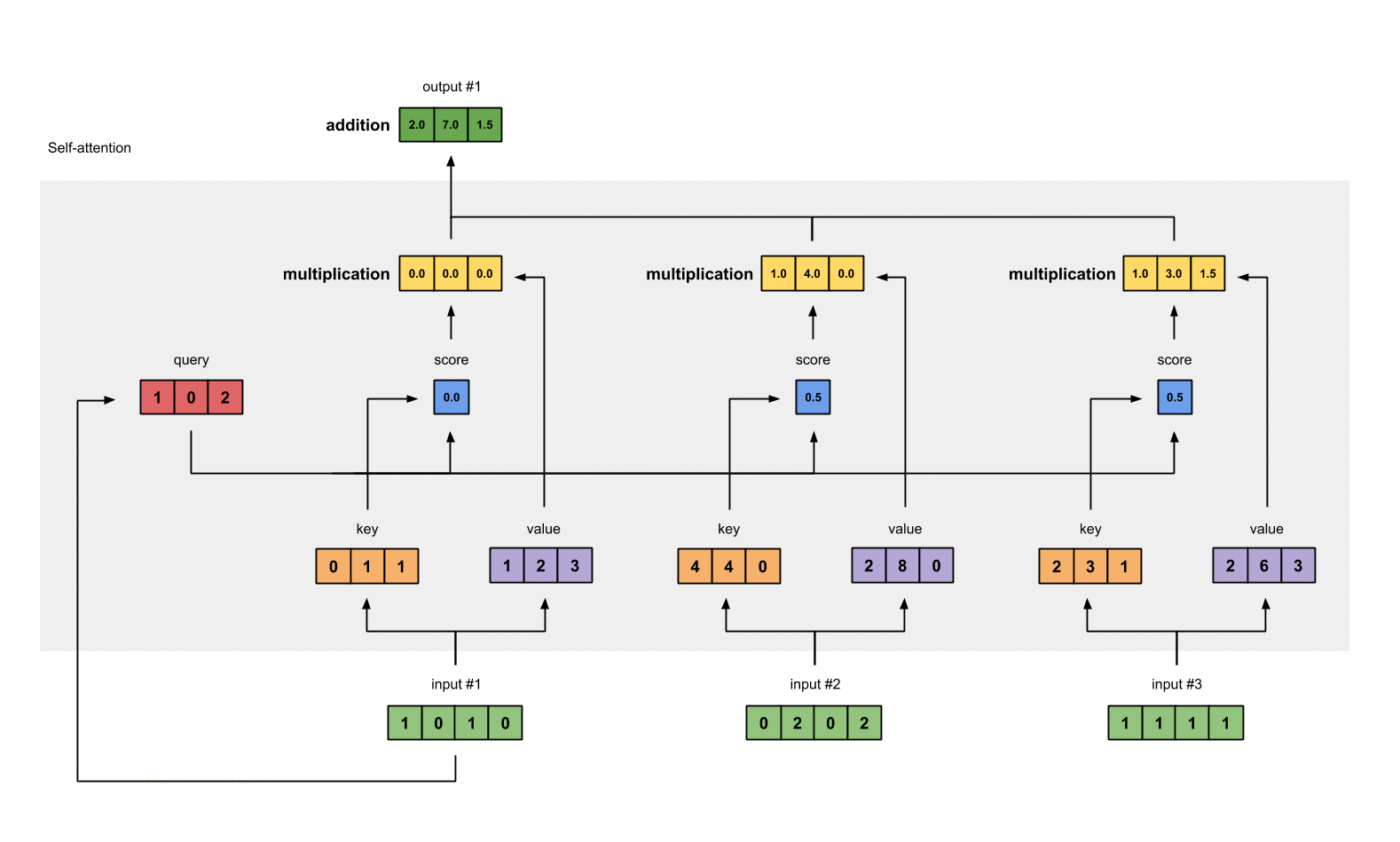
- Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V:这是单一的注意力头计算公式。
- MultiHead ( Q , K , V ) = Concat ( head 1 , . . . , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO:这是多头注意力机制的计算公式。
-
多头注意力的具体计算:
- 对于每个头 i i i,计算 head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)。
- 将所有头的输出进行拼接: Concat ( head 1 , . . . , head h ) \text{Concat}(\text{head}_1, ..., \text{head}_h) Concat(head1,...,headh)。
- 通过权重矩阵 W O W^O WO 进行线性变换,得到最终的输出结果。
-
与单一注意力头的关系:
- 多头注意力机制实际上是将单一的注意力头进行了扩展和并行化处理。
- 每个头都可以独立地进行注意力计算,然后将结果合并,从而得到更加丰富和多样的特征表示。
关键词提炼
#Multi-head Attention
#Transformer模型
#多头注意力机制
#序列数据处理
#长距离依赖关系