过去 1.5 年以来,我一直在使用 Java 编程。最近,我在尝试对 Java 数据结构进行性能分析。为了亲自体验一下,我决定玩一下我最喜欢的数据结构,即 HashSet。HashSet 提供 O(1) 查找和插入时间。我测量并比较了在 HashSet 中查找具有不同大小的随机字符串所需的时间。
以下是我编写的代码片段:-
public class HashCodePerformance {
public static void main(String[] args) {
Set<String> stringHashSet = new HashSet<>();
stringHashSet.add("London");
stringHashSet.add("Mumbai");
stringHashSet.add("NewYork");
List<String> stringsToSearch = Arrays.asList("f5a5a608", "48abre7a6 i8a5r507",
"7e50bc488 pl43fvf1p 65", "e843r6f1p vfvdfv vdvdg vgbgd ", "38aeaf9a6");
for (String string : stringsToSearch) {
Stopwatch timer = Stopwatch.createStarted();
for (int index=0; index < 10000000; ++index) {
stringHashSet.contains(string);
}
System.out.println("Search String \"" + string + "\" time taken " + timer.stop());
}
}
}
//输出
Search String "f5a5a608" time taken 94.51 ms
Search String "48abre7a6 i8a5r507" time taken 37.79 ms
Search String "7e50bc488 pl43fvf1p 65" time taken 28.29 ms
Search String "e843r6f1p vfvdfv vdvdg vgbgd " time taken 26.46 ms
Search String "38aeaf9a6" time taken 80.07 ms
从输出结果我们发现了一个有趣的现象。第一个和最后一个字符串查找所花的时间几乎是中间三个字符串的 3 到 4 倍。即使中间三个字符串的长度更长,
我们发现了一个有趣的现象。第一个和最后一个字符串查找(以红色突出显示)所花的时间几乎是中间三个字符串的 3 到 4 倍。即使中间三个字符串的长度更长,但查找效率却更高。这意味着HashSet查找与字符串的长度无关。
为了理解 HashSet 的这种不寻常的行为,让我们回到基础并了解基本原理。
HashSet 内部工作原理
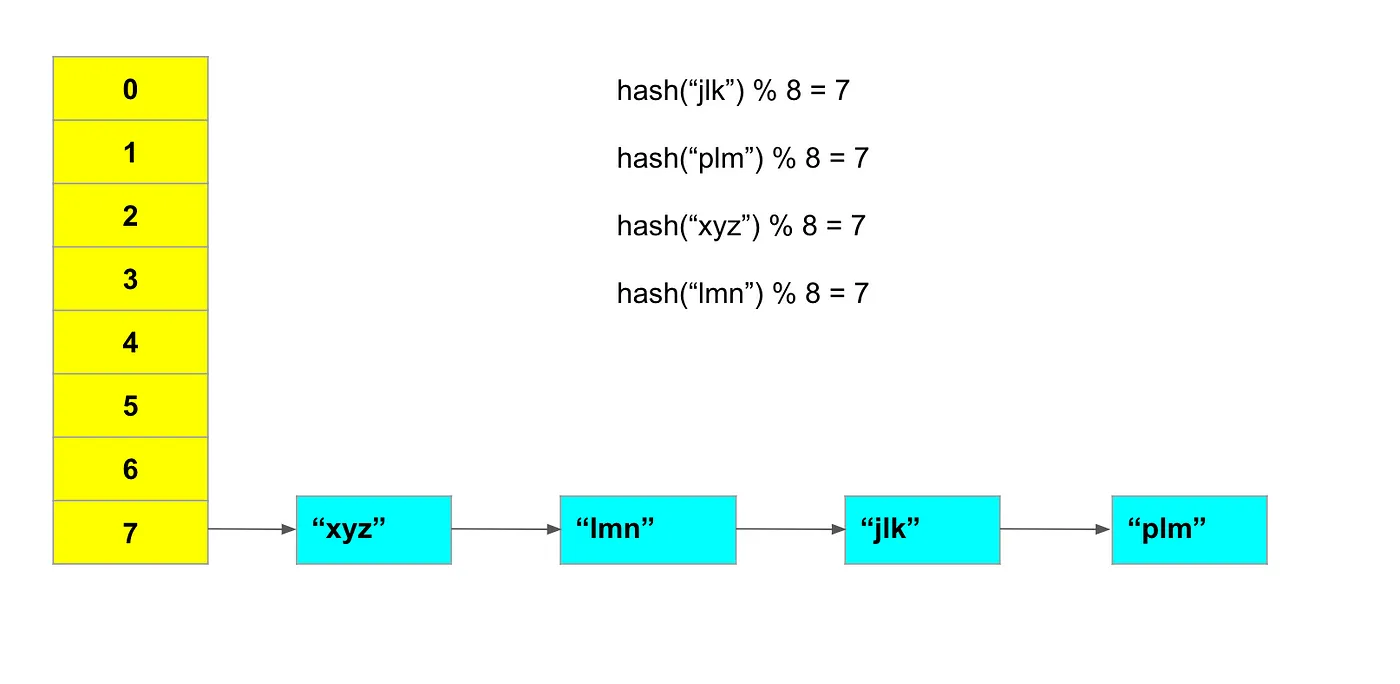
Java HashSet 内部使用链表数组来执行 O(1) 插入、查找和删除。HashSet 首先计算对象的哈希值,以确定对象将存储在数组的哪个索引处。然后,将对象存储在计算出的索引处。同样的原理适用于查找和删除。
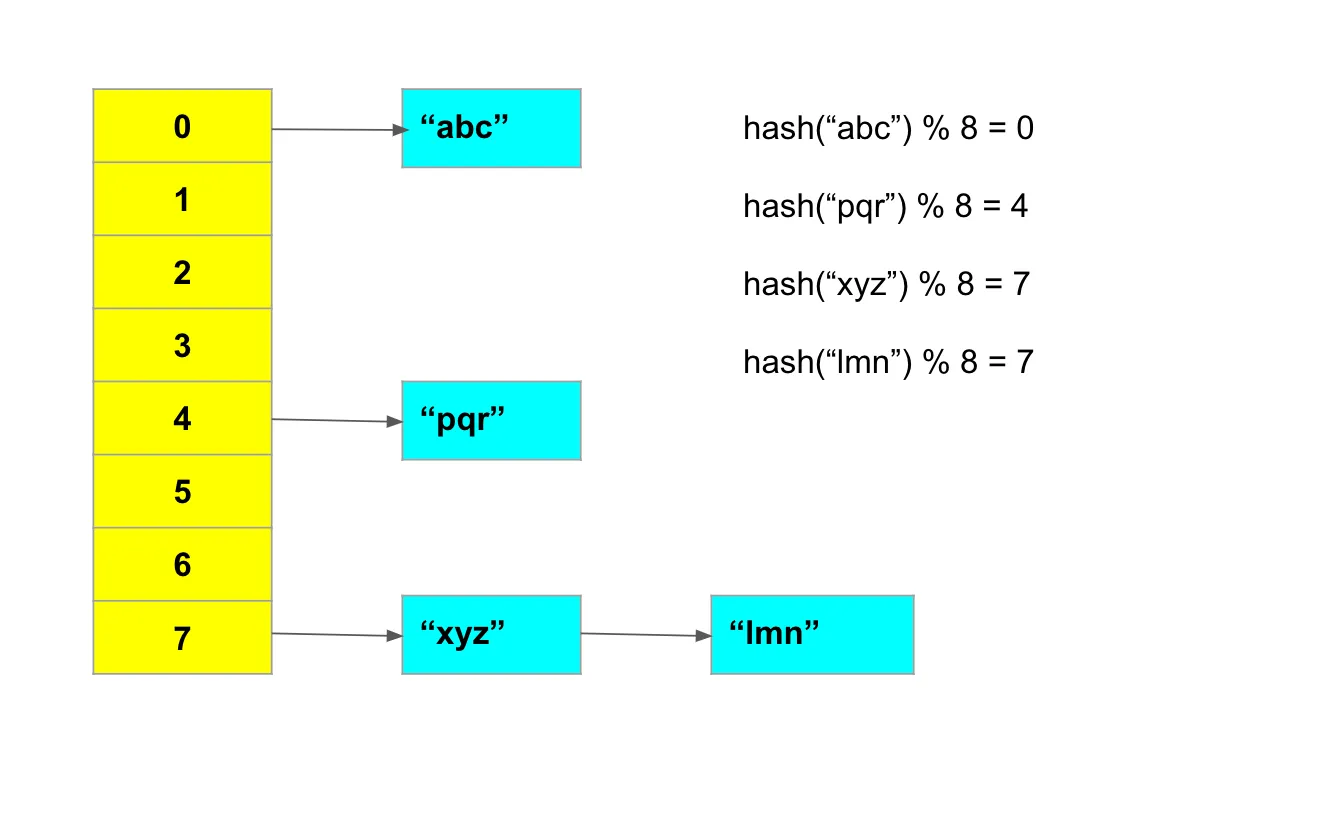
访问数组元素是 O(1)时间复杂度,所以唯一的开销是计算对象的哈希值。因此,哈希函数需要是最佳的,以避免任何性能影响。
此外,哈希函数的输出应该具有均匀分布。如果发生冲突,给定索引处的链表长度将不断增长,最坏情况复杂度将变为 O(n)。
HashCode 设计
在 Java 中,每个对象都有一个 hashCode() 函数。HashSet 调用此函数来确定对象索引。让我们回顾一下我们分析字符串查找性能的示例,看看随机字符串的hashCode值。
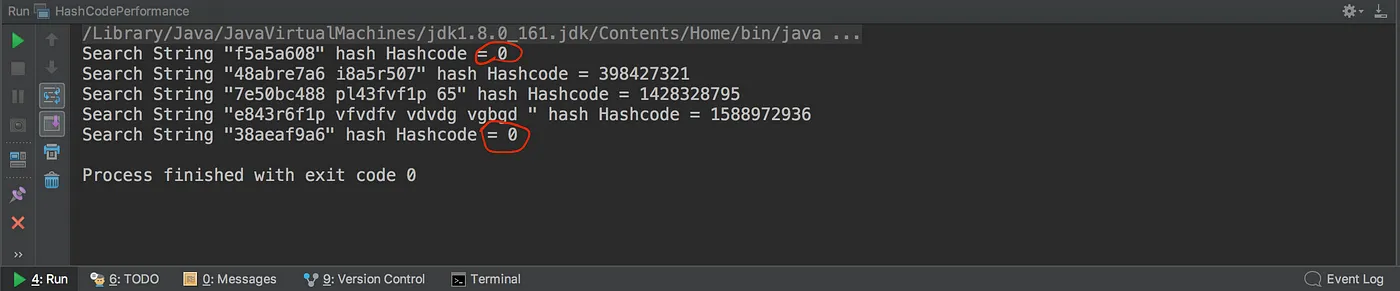
我们可以看到异常字符串的 hashCode 为 0。现在,是时候深入研究一些代码并查看实现情况了。
在旧版本的JDK 1.0+和1.1+中,字符串的hashCode函数对每个第n个字符进行采样。这种方法的缺点是许多字符串映射到相同的哈希,导致冲突。
在 Java 1.2 中,使用下面的算法。这个算法有点慢,但有助于避免碰撞。
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
从上述代码可以看出,第一次调用 hashCode 时,变量hash的默认值为 0,并执行第 3-9 行。后续调用 hashCode() 时,如果 hash 非零,则不会执行第 3-9 行。
可以推断,hashCode() 函数使用了一种缓存方法,其中仅在第一次调用时计算哈希值,之后的调用将获得相同的计算值。
如果字符串的哈希值为 0,则每次调用该函数时都会进行哈希计算。现在,就应该清楚为什么查找一些字符串比其他字符串花费更多时间了。
克服性能损失
对于哈希值为 0 的字符串,上述 HashCode 计算性能较差。我们如何优化它?
任何从事计算机软件开发的程序员都应该知道使用布尔标志,该标志将在第一次计算后设置,并会在后续调用中跳过计算。
public int hashCode() {
int h = hash;
if (!computed && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
computed = true;
}
return h;
}
可以看出优化并不难,那为什么 Java 开发人员一开始没有想到这种优化,或者为什么在 Java 的后续版本中没有修补这个问题?
为什么不修复HashCode?
根据实现,以下是任何具有“n”个字符的字符串的哈希公式。
hash = s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1]
这里 s[n] 是字符串中的第 n 个字符
这个哈希函数在整数范围内提供了均匀分布。这意味着字符串哈希为0的概率是1/2^32。
我们可以想到以下情况,其中字符串的哈希为零:
- 字符串仅包含 0(Unicode 字符)
- 空字符串
- 由于整数溢出,哈希码为 0
目前,只有哈希值为 0 的字符串会受到影响。而在实际应用中,这几种字符串出现的概率很小。假设我们通过添加布尔值来修复 hashCode。总体而言,我们不会看到对实际系统性能产生任何巨大提升。它可能会导致速度提高 0.000010%。这类似于说我们将一个可以在1小时完成的任务优化为59分钟59秒7毫秒。
因此,这就是为什么在 Java 的后续版本中没有修补这个问题的原因。
哈希值为 0 的英文字符串
我拿了一个包含20k英文单词的词典列表,并尝试组合这些单词以检查它们的哈希是否为零。当我考虑单个有意义的英文单词时,没有一个哈希为零。两个或多个单词的组合会产生零哈希值。
以下是一些哈希为零的句子(有意义的单词)的例子:
- carcinomas motorists high
- zipped daydreams thunderflashes
- where inattentive agronomy
- drumwood boulderhead



![[网鼎杯 2020 朱雀组]Nmap(详细解读版)](https://i-blog.csdnimg.cn/direct/f8c1ed139c0f405f844029529c49cf4d.png)