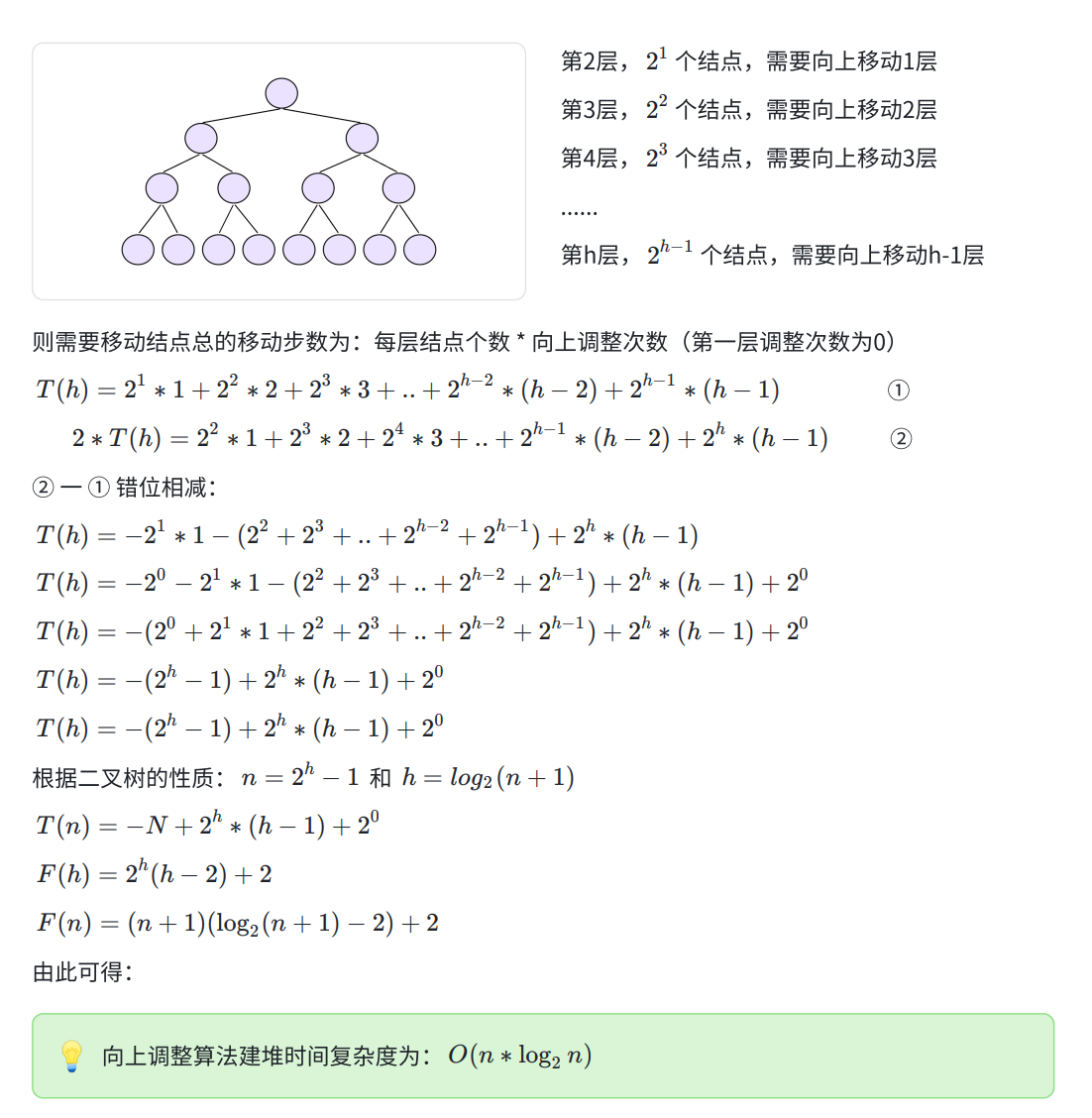
多表联查
多表联查可以通过连接运算实现,即将多张表通过主外键关系关联在一起进行查询。下图提供了多表联查 时用到的数据库表之间的关系。

等值查询和非等值查询
非等值查询:SELECT * FROM 表1,表2
等值查询:SELECT * FROM 表1,表2 WHERE 表1.字段1 = 表2.字段2...
其中:
- 与单表查询类似,都是SELECT语句;
- 把多个表放到FROM后,并用逗号隔开;
- 可使用AS关键字取别名,便于引用;
- 如无重名查询字段则可省略数据表的指定。
-- 等值联查
-- 适合表的个数多但各个表数据量不大的情况,吃内存,IO小
-- 查询出学生和班级信息 student class
SELECT * FROM student,class WHERE student.classid=class.classid
SELECT * FROM student,course,class,sc,teacher
WHERE teacher.tid=course.tid AND
student.classid=class.classid AND
sc.cid=course.cid AND
student.sid=sc.sid;
-- 查询出学过张三老师课程的学生信息
SELECT student.* FROM student,sc,course,teacher
WHERE student.sid=sc.sid AND
sc.cid=course.cid AND
course.tid=teacher.tid AND
teacher.tname='张三';
-- 查询每个学生的平均成绩 学生姓名,班级名称,平均成绩
SELECT student.sname,class.classname,avg(sc.score) FROM student,sc,class
WHERE student.sid=sc.sid and class.classid=student.classid
GROUP BY student.sid连接查询(1)
SELECT * FROM 表1 LEFT|right|INNER JOIN 表2 ON 条件
LEFT JOIN
从左表(表1)中返回所有的记录,即便在右 (表2)中没有匹配的行。
RIGHT JOIN
从右表(table_2)中返回所有的记录,即便 在左(table_1)中没有匹配的行。
INNER JOIN
在表中至少一个匹配时,则返回记录。
-- inner join on
-- 表少,每张表的数据大,内存占用小,IO高
-- 通过第一张表的结果进行on条件匹配
SELECT * FROM student
INNER JOIN class on student.classid = class.classid
WHERE ssex='男'
-- 五表联查
SELECT * FROM student
INNER JOIN sc ON sc.sid=student.sid
INNER JOIN course ON course.cid = sc.cid
INNER JOIN teacher ON teacher.tid=course.tid
INNER JOIN class ON class.classid=student.classid
-- 查询每门课程的平均成绩 课程名称 代课老师姓名 平均成绩
SELECT course.cname,teacher.tname,AVG(sc.score) FROM sc
INNER JOIN course ON course.cid = sc.cid
INNER JOIN teacher ON teacher.tid=course.tid
GROUP BY course.cid
-- 外联查询
-- 首先确定主查
-- 尽量先写较小的表,可以使循环量下降,优化
-- 所有学生的数据和对应的班级信息
-- left join on 左外联 主查在left
SELECT * FROM student
LEFT JOIN class ON student.classid = class.classid
-- right join on 右外联 主查在right
SELECT * FROM class
RIGHT JOIN student ON student.classid = class.classid
-- 查询出所有的学生学过多少门课程 学生姓名 课程数
SELECT sname,COUNT(cname) FROM student
LEFT JOIN sc ON student.sid = sc.sid
LEFT JOIN course ON sc.cid = course.cid
GROUP BY student.sid
-- 利用主键不能为空查询
-- 没有班级的学生
SELECT * FROM student
LEFT JOIN class on student.classid=class.classid
WHERE class.classid is NULL
-- 没有学生的班级
SELECT * FROM class
LEFT JOIN student on student.classid=class.classid
WHERE student.sid is NULL连接查询(2)
左表独有的数据:
select * from t1 left join t2 on t1.id = t2.id where t2.id is null;
右表独有的数据:
select * from t1 right join t2 on t1.id = t2.id where t1.id is null;
UNION
union是求两个查询的并集。 union合并的是结果集,不区分来自于哪一张表,所以可以合并多张表查询出来的数据。
语法:
select A.field1 as f1, A.field2 as f2 from A
union
(select B.field3 as f1, field4 as f2 from B) order by 字段 desc/asc
注意:
- 列名不一致时,会以第一张表的表头为准,并对其栏目。
- 会将重复的行过滤掉。
- 如果查询的表的列数量不相等时,会报错。
- 在每个子句中的排序是没有意义的,mysql在进行合并的时候会忽略掉。
- 如果子句中的排序和limit进行结合是有意义的。
- 可以对合并后的整表进行排序
UNION ALL
语法:
select A.field1 as f1, A.field2 as f2 from A
union all
(select B.field3 as f1, field4 as f2 from B) order by 字段 desc/asc
union all 是求两个查询的并集,但是不会把重复的过滤掉,而是全部显示出来。
-- UNION 两个结果集的并集,两个集合没有任何关系也能合并
-- UNION 会去重 和 DISTINCT一样
-- 内容相同但不同类型的字段可以在同一个表里并集
-- 不同列的数量的结果集不允许合并
-- 起别名给第一个结果集才有用
-- 表头
-- 库中所有人的名字(老师、学生)
SELECT sname 姓名,classid 班级 FROM student
UNION
SELECT tname,temail FROM teacher
-- 获取没有班级的学生和没有学生的班级
SELECT * FROM student
LEFT JOIN class on student.classid=class.classid
WHERE class.classid is NULL
UNION
SELECT * FROM student
RIGHT JOIN class on student.classid=class.classid
WHERE student.sid is NULL
-- 我全都要
-- 全连接
-- 左右主表(主查)不同位置相反
SELECT * FROM student
LEFT JOIN class on student.classid=class.classid
UNION
SELECT * FROM student
RIGHT JOIN class on student.classid=class.classid
-- 不去重的并集
SELECT * FROM student
LEFT JOIN class on student.classid=class.classid
UNION ALL
SELECT * FROM student
RIGHT JOIN class on student.classid=class.classid子查询
子查询,又叫内部查询
where 型子查询
查询id最大的一个学生(使用排序+分页实现)
-- 查询id最大的学生
SELECT * FROM student ORDER BY sid DESC LIMIT 0,1查询id最大的一个学生(使用where子查询实现)
-- 子查询
-- 所有子查询必须用括号圈起来,执行子句,再执行括号外
-- 效率低,特殊情况下考虑,需求最优先
SELECT * FROM student WHERE sid = (
SELECT MAX(sid) FROM student
)
查询每个班下id最大的学生(使用where子查询实现)
-- 查询每个班下id最大的学生(子查询)
SELECT sid,sname,classid FROM student WHERE sid IN(
SELECT MAX(sid) FROM student GROUP BY classid
)查询学过张三课程的学生
-- 查询学过张三课程的学生
SELECT * FROM student WHERE sid in(
SELECT sid FROM sc WHERE cid=(
SELECT cid FROM course WHERE tid=(
SELECT tid FROM teacher WHERE tname = '张三'
)
)
)
查询没有学过张三课程的学生
-- 查询没有学过张三课程的学生
SELECT * FROM student WHERE sid not in(
SELECT sid FROM sc WHERE cid=(
SELECT cid FROM course WHERE tid=(
SELECT tid FROM teacher WHERE tname = '张三'
)
)
)from型子查询
把内层的查询结果当成临时表,供外层sql再次查询。查询结果集可以当成表看待。 临时表要使用一个别名。
查询大于5人的班级名称和人数(不使用子查询)
-- 查询大于5个人的班级名称和人数(不使用子查询)
SELECT classname,COUNT(*) from class
LEFT JOIN student on class.classid = student.classid
GROUP BY class.classid HAVING COUNT(*) > 5查询大于5个人的班级名称和人数(使用子查询)
-- 查询大于5个人的班级名称和人数(使用子查询)
SELECT classname,人数 FROM class LEFT JOIN(
SELECT classid,COUNT(*) 人数 FROM student GROUP BY classid) t1
on class.classid = t1.classid
WHERE 人数 > 5exists型子查询
把外层sql的结果,拿到内层sql去测试,如果内层的sql成立,则该行取出。内层查询是exists后的查询。
-- exist 子查询 子句有结果,父句执行,子句无结果,父句不执行
SELECT * FROM teacher
WHERE EXISTS (SELECT * FROM student WHERE classid = 1)
any, some, all子查询
any子查询
表示满足其中任意一个条件 假设any内部的查询语句返回的结果个数是三个, 如:result1,result2,result3,那么,
select ...from ... where a > any(...);
->相当于:
select ...from ... where a > result1 or a > result2 or a > result3;
some 是 any的别名,所以用法是一样的,可以替代使用
查询出一班成绩比二班最低成绩高的学生
SELECT DISTINCT student.* from sc
LEFT JOIN student on sc.sid = student.sid
WHERE student.classid=1 AND score > ANY(
SELECT score FROM sc
LEFT JOIN student on sc.sid = student.sid
WHERE student.classid=2
)all 子查询
表示满足其中所有条件条件,ALL关键字与any关键字类似,只不过上面的or改成and。 假设any内部的查询语句返回的结果个数是三个,
select ...from ... where a > all(...);
->
select ...from ... where a > result1 and a > result2 and a > result3;
查询出一班成绩比二班最高成绩高的学生
SELECT DISTINCT student.* from sc
LEFT JOIN student on sc.sid = student.sid
WHERE student.classid=1 AND score > ALL(
SELECT score FROM sc
LEFT JOIN student on sc.sid = student.sid
WHERE student.classid=2
)
流程控制函数,语句
流程处理函数可以根据不同的条件,执行不同的处理流程,可以再SQL语句中实现不同的条件选择。MySQL中的流程处理函数主要包括IF()、IFNULL()和CASE()函数。
| 函数 | 用法 |
| IF(value,value1,value2) | 如果value的值为TRUE,返回value1,否则返回value2 |
| IFNULL(value,value1,value2) | 如果value的值不为NULL,返回value1,否则返回value2 |
| CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2…… [ELSE result] END | 相当于Java的if...else...if...else |
| CASE expr WHEN 常量值1 THEN 值1 WHEN 常量2 THEN 值2…… [ELSE 值n] END | 相当于Java的switch……case... |
# 结果集的控制
-- IF(expr1,expr2,expr3) -- 三元运算符
-- expr1 条件
-- expr2 条件成立 显示的数据
-- expr3 条件不成立 显示的数据
SELECT * FROM teacher;
-- 0 女
-- 1 男
SELECT tid,tname,if(tsex=1,'男','女') tsex ,tbirthday,taddress FROM teacher
-- IFNULL(expr1,expr2)
-- expr1 字段名
-- expr2 如果数据为null显示的内容
SELECT sid,sname,IFNULL(birthday,'该生未填写生日') birthday ,ssex FROM student
-- CASE WHEN THEN END 类似switch 如果没有else值,则不在when内的选项的默认值为null
-- 用法1
SELECT tid,tname,
CASE tsex
WHEN 0 THEN '男'
WHEN 1 THEN '女'
ELSE '保密'
END tsex,tbirthday FROM teacher
-- 用法二
SELECT tid,tname,
CASE
WHEN tsex > 1 THEN '男'
WHEN tsex = 1 THEN '女'
WHEN tsex < 1 THEN '保密'
END tsex,tbirthday FROM teacher
-- 查询学生的成绩,
-- 并将大于90分的用A显示,
-- 大于80分的用B显示,
-- 大于70分的用C显示,
-- 大于60分的用D显示,
-- 小于60分的显示不及格
SELECT sid,
CASE
WHEN sc.score >= 90 THEN 'A'
WHEN sc.score >= 80 THEN 'B'
WHEN sc.score >= 70 THEN 'C'
WHEN sc.score >= 60 THEN 'D'
WHEN sc.score < 60 THEN '不及格'
END '成绩' FROM sc
-- 统计各个分数段的人数
/*
分数段 人数
100-90 5
90-70 10
70-60 2
不及格 3
*/
select '100-90' 分数段, count(*) 人数 from sc where score <=100 and score >=90
union
select '90-70', count(*) from sc where score <90 and score >=70
/*
分数段 100-90 90-70 70-60 不及格
人数 5 10 2 3
*/
-- case when then end
select '人数' 分数段,
count(case when score <= 100 and score >=90 then score end) '100-90',
count(case when score < 90 and score >=70 then score end) '90-70',
count(case when score < 70 and score >=60 then score end) '70-60',
count(case when score < 60 then score end) '不及格'
from sc sql执行顺序
Sql语句在数据库中的执行流程

- 系统(客户端)访问 MySQL 服务器前,做 的第一件事就是建立 TCP 连接。
- Caches & Buffers: 查询缓存组件
- SQL Interface: SQL接口 接收用户的SQL命 令,并且返回用户需要查询的结果。比如 SELECT ... FROM就是调用SQL Interface MySQL支持DML(数据操作语言)、DDL (数据定义语言)、存储过程、视图、触发器、 自定 义函数等多种SQL语言接口
- Parser: 解析器:在解析器中对 SQL 语句进行 语法分析、语义分析。
- Optimizer: 查询优化器
- 存储引擎
- 文件系统
- 日志系统
Sql查询语句的执行顺序

总结
- 连接查询的分类
- 右连接: 从右表(table_2)中返回所有的记录,即便在左(table_1)中没有匹配的行 ;
- 左连接: 从左表(表1)中返回所有的记录,即便在右(表2)中没有匹配的行;
- 内连接: 在表中至少一个匹配时,则返回记录 。
- 子查询等特殊查询
- where子查询
- from 子查询
- exists 子查询
- any,some (or),all (and)子查询
- 特殊查询
课后作业
-- 课后作业
学生表:Student(编号sid,姓名sname,生日birthday,性别ssex,班级 classid)
课程表:Course(课程编号cid,课程名称cname,教师编号tid)
成绩表:Sc(学生编号sid,课程编号cid,成绩score)
教师表:Teacher(教师编号tid,姓名tname)
班级表:Class (班级编号 classid,班级名称 classname)
学生表 Student
create table Student(Sid int primary key, Sname varchar(10), birthday datetime, Ssex varchar(10), classid int);
insert into Student values('1' , '赵雷' , '1990-01-01' , '男', '1');
insert into Student values('2' , '钱电' , '1990-12-21' , '男', '2');
insert into Student values('3' , '孙风' , '1990-05-20' , '男', '1');
insert into Student values('4' , '李云' , '1990-08-06' , '男', '2');
insert into Student values('5' , '周梅' , '1991-12-01' , '女', '1');
insert into Student values('6' , '吴兰' , '1992-03-01' , '女', '2');
insert into Student values('7' , '郑竹' , '1989-07-01' , '女', '1');
insert into Student values('8' , '王菊' , '1990-01-20' , '女', '2');
成绩表 SC
create table SC(Sid int, Cid int, score decimal(18,1));
insert into SC values('1' , '1' , 80);
insert into SC values('1' , '2' , 90);
insert into SC values('1' , '3' , 99);
insert into SC values('2' , '1' , 70);
insert into SC values('2' , '2' , 60);
insert into SC values('2' , '3' , 80);
insert into SC values('3' , '1' , 80);
insert into SC values('3' , '2' , 80);
insert into SC values('3' , '3' , 80);
insert into SC values('4' , '1' , 50);
insert into SC values('4' , '2' , 30);
insert into SC values('4' , '3' , 20);
insert into SC values('5' , '1' , 76);
insert into SC values('5' , '2' , 87);
insert into SC values('6' , '1' , 31);
insert into SC values('6' , '3' , 34);
insert into SC values('7' , '2' , 89);
insert into SC values('7' , '3' , 98);
课程表 Course
create table Course(Cid int primary key,Cname varchar(10),Tid varchar(10));
insert into Course values('1' , '语文' , '2');
insert into Course values('2' , '数学' , '1');
insert into Course values('3' , '英语' , '3');
教师表 Teacher
create table Teacher(
Tid int primary key auto_increment,
Tname varchar(10),
Tsex TINYINT default 1,
Tbirthday date,
Taddress varchar(255),
Temail varchar(255),
Tmoney DECIMAL(20,2)
);
insert into Teacher values('1' , '张三',1,'1988-1-15','陕西咸阳','zhangsan@qq.com',3000.00);
insert into Teacher values('2' , '李四',0,'1992-5-9','陕西宝鸡','lisi@qq.com',4000.00);
insert into Teacher values('3' , '王五',1,'1977-7-1','山西太原','wangwu@qq.com',5000.00);
班级表 Class
create table Class(classid int primary key, classname varchar(20));
insert into Class values('1', '一班');
insert into Class values('2', '二班');
1. 查询” 01 “课程比” 02 “课程成绩高的学生的信息及课程分数
select * from student
inner join
(select * from sc where cid = 1) t1
on student.sid = t1.sid
inner join
(select * from sc where cid = 2) t2
on t1.sid = t2.sid
where t1.score > t2.score
2. 查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
select sc.sid,sname,avg(score) from sc,student
where sc.sid = student.sid
group by sc.sid having avg(score) >= 60
3. 查询在 SC 表存在成绩的学生信息
select * from student where sid in(
select sid from sc
)
select distinct student.* from student
inner join sc on student.sid = sc.sid
4. 查询所有同学的学生编号、学生姓名、选课总数、
所有课程的总成绩(没成绩的显示为 null )
select student.sid,sname,count(cid),sum(score)
from student
left join sc on student.sid = sc.sid
group by student.sid
5. 查询「李」姓老师的数量
select count(*) from teacher where tname like '李%'
6. 查询学过「张三」老师授课的同学的信息
7. 查询没有学全所有课程的同学的信息
select student.* from student
left join sc on student.sid = sc.sid
group by student.sid
having count(cid) < (select count(*) from course)
8. 查询至少有一门课与学号为” 01 “的同学所学相同的同学的信息
select DISTINCT student.* from student
left join sc on student.sid = sc.sid
where cid in (
select cid from sc where sid = 1
) and student.sid <> 1
9. 查询和” 01 “号的同学学习的课程完全相同的其他同学的
1. 范围相同 2. 个数相同
select student.* from student
inner join sc on student.sid = sc.sid
where
student.sid not in(
select sid from sc where cid not in(
select cid from sc where sid = 1
)
)
group by student.sid
having count(cid) = (select count(*) from sc where sid = 1)
10. 查询没学过”张三”老师讲授的任一门课程的学生姓名
11. 查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
select student.sid,sname,avg(score) from sc,student
where score < 60 and sc.sid = student.sid
group by student.sid having count(cid) >=2
12. 检索” 01 “课程分数小于 60,按分数降序排列的学生信息
select * from student, sc
where student.sid = sc.sid and cid = 1 and score < 60
order by score desc
13. 查询各科成绩最高分、最低分和平均分,
以如下形式显示:课程 ID,课程 name,最高分,最低分,平均分,
及格率,中等率,优良率,优秀率(及格为>=60,中等为:70-80,
优良为:80-90,优秀为:>=90)。
select sc.cid,cname,max(score),min(score),avg(score),
count(case when score >=60 then score end)/count(*) * 100,
count(case when score >=70 and score <80 then score end)/count(*) * 100,
count(case when score >=80 and score <90 then score end)/count(*) * 100,
count(case when score >=90 then score end)/count(*) * 100
from course,sc
where course.cid = sc.cid
group by course.cid
select cid,
count(case when score >=60 then score end)/count(*) * 100,
count(case when score >=70 and score <80 then score end)/count(*) * 100,
count(case when score >=80 and score <90 then score end)/count(*) * 100,
count(case when score >=90 then score end)/count(*) * 100
from sc
group by cid