文章目录
- 引言
- 复习
- 堆
- 堆——前K个高频元素
- 个人实现
- 复习实现二
- 参考实现
- 新作
- 单词搜索
- 个人实现
- 参考实现
- 分割回文串
- 个人实现
- 参考实现
- 环形链表II
- 个人实现
- 参考实现
- 两个有序链表
- 个人实现
- 总结
引言
- 又是充满挑战性的一天,继续完成我们的任务吧!继续往下刷,一场面试三个构成:八股、项目和算法,都得抓住!加油
- 今天复习一下堆,然后把回溯剩下的题目全部做完,然后的继续往下做链表!
复习
堆
- 对顶堆——数据流的中位数
- front是大顶堆,back是小顶堆
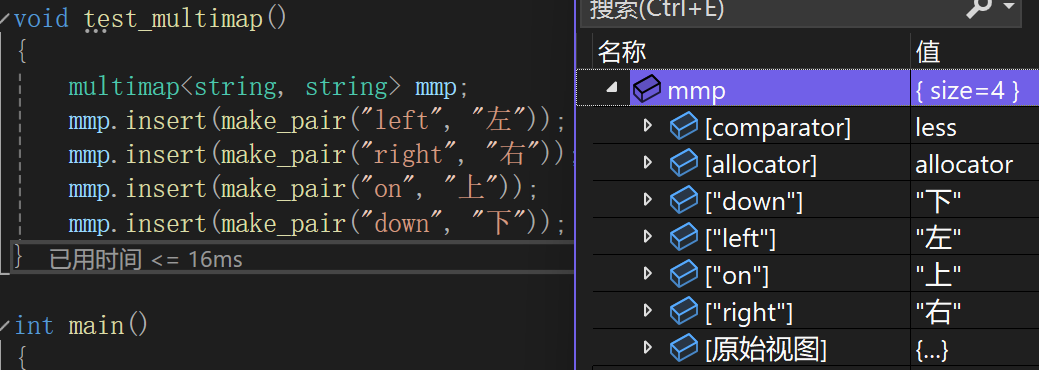
堆——前K个高频元素
- 题目链接
- 第一次练习链接
- 第二次练习链接
- 虽然已经做了两次,但是一点都想不起来应该怎么做!
个人实现
- 这道题可以通过设置不同的数据结构实现,通过key-value改变记录每一个数字出现的频率,然后通过PriorityQueue来实现根据频率进行排序,这样效率就快很多!那么怎么实现自定义排序就很重要!
class Solution {
class Item implements Comparable<Item>{
int val;
int freq;
Item(int value,int frequency){
val = value;
freq = frequency;
}
// override the compareTo function
@Override
public int compareTo(Item o){
return Integer.compare( this.freq,o.freq);
}
}
public int[] topKFrequent(int[] nums, int k) {
// define map to store the key-value item ,priorityqueue to sort the item
PriorityQueue<Item> pq = new PriorityQueue<>(Comparator.reverseOrder());
Map<Integer,Item> map = new HashMap<>();
// traverse all the elements
for(int x :nums){
if(map.containsKey(x)){
Item temp = map.get(x);
temp.freq = temp.freq + 1;
System.out.println(map.get(x).freq);
}else{
Item temp = new Item(x,1);
map.put(x,temp);
pq.add(temp);
}
}
// traverse the front k elements
int[] res = new int[k];
//System.out.println(pq.peek().val);
for(int i = 0;i < k;i ++)
res[i] = pq.poll().val;
return res;
}
}
问题
- 如何重写对象compare方法
- 要实现Comparable接口
- compareTo方法是接受当前类型的变量,进行的比较
- compareTo方法,返回的是一个int类型的变量
- 实现comparable接口,需要实现compareTo方法
class Item implements Comparable<Item> {
int val;
int freq;
Item(int value, int frequency) {
val = value;
freq = frequency;
}
// override the compareTo function
@Override
public int compareTo(Item o) {
return Integer.compare(o.freq, this.freq); // descending order
}
}

- 致命问题!!PriorityQueue并不会自动重新排序!需要每次更新都要插入和删除对应的元素,不然会出问题!

复习实现二
- 这里不知道自己着了什么魔,这个题目为啥要想的那么复杂,不就是先统计频率,然后再根据频率进行排序吗?为什么要想那么多!
class Solution {
class Item implements Comparable<Item>{
int val;
int freq;
Item(int value,int frequency){
val = value;
freq = frequency;
}
// override the compareTo function
@Override
public int compareTo(Item o){
return Integer.compare( this.freq,o.freq);
}
}
public int[] topKFrequent(int[] nums, int k) {
// define map to store the key-value item ,priorityqueue to sort the item
PriorityQueue<Item> pq = new PriorityQueue<>(Comparator.reverseOrder());
Map<Integer,Item> map = new HashMap<>();
// traverse all the elements
for(int x :nums){
if(map.containsKey(x)){
Item temp = map.get(x);
temp.freq = temp.freq + 1;
}else{
map.put(x,new Item(x,1));
}
}
// traverse the values int the
for(Item x:map.values()){
pq.add(x);
}
// traverse the front k elements
int[] res = new int[k];
//System.out.println(pq.peek().val);
for(int i = 0;i < k;i ++)
res[i] = pq.poll().val;
return res;
}
}

问题
- 这里Map的相关方法使用起来还是带有试验的性质,很多方法当时写了就错了,编译器提醒没有这种方法,才知道应该换!这里再复习一遍!
- 加入元素:
- put(K key,V value)
- 如果存在旧值,会将其替换
- 注意,没有set方法,那是list才有的
- 获取对应的value
- get(Object key)
- 如果不含有对应的key,就返回null
- 删除对应的元素
- remove(Object key)
- 判定是否含有对应的元素
- containsKey(Obejct key)
- 是containsKey,contains是Set的方法
- 判定是否为空
- isEmpty
- 不是Empty,每次都写错
- 获取所有value
- values
- 这里是返回所有的values,不是valueset
- 获取所有的key
- keySet
- 不是keys
参考实现
使用计数排序
- 将所有出现的频次记录在对应的数组中,然后根据索引进行遍历,减少遍历的时间!
这里就不记录了,如果感兴趣,就自己去看!
限定堆使用的大小
- 如果直接将所有的元素加入到堆中进行排序,需要消耗很多时间,这里只要前K个元素,所以只需要维护一个大小为K的堆就行了!
class Solution {
class Item implements Comparable<Item>{
int val;
int freq;
Item(int value,int frequency){
val = value;
freq = frequency;
}
// override the compareTo function
@Override
public int compareTo(Item o){
return Integer.compare( this.freq,o.freq);
}
}
public int[] topKFrequent(int[] nums, int k) {
// define map to store the key-value item ,priorityqueue to sort the item
PriorityQueue<Item> pq = new PriorityQueue<>();
Map<Integer,Item> map = new HashMap<>();
// traverse all the elements
for(int x :nums){
if(map.containsKey(x)){
Item temp = map.get(x);
temp.freq = temp.freq + 1;
}else{
map.put(x,new Item(x,1));
}
}
// traverse the values int the
for(Item x:map.values()){
if(pq.size() < k)
pq.add(x);
else{
if(pq.peek().freq < x.freq){
pq.poll();
pq.add(x);
}
}
}
// traverse the front k elements
int[] res = new int[k];
//System.out.println(pq.peek().val);
for(int i = 0;i < k;i ++)
res[i] = pq.poll().val;
return res;
}
}

新作
单词搜索
题目链接



注意
- 整个二维矩阵的大小可能是一个单元格,仅仅只有一个字母,可能是边界情况需要特殊处理。
- 目标单词的长度是遍历的深度,也就是遍历树的高度,然后上下左右是四个方向,是每一层遍历的宽度。
个人实现
- 这道题是典型的回溯,回溯的要素设定如下
- idx 界限值是 单词的长度
- 每一层遍历的宽度是上下左右四个方向
- 需要维护一个exist数组,标记每一个元素的访问情况。
class Solution {
// define the global string to store the mid situation
StringBuilder str = new StringBuilder();
// exist matrix to store the attendence
boolean[][] exist ;
//boolean res = false;
int[][] step = {{1,0},{0,1},{-1,0},{0,-1}};
boolean dfs(char[][] board,String word,int idx,int x,int y){
if(idx == word.length()){
return true;
}
for(int i = 0;i < 4;i ++){
int xNext = x + step[i][0];
int yNext = y + step[i][1];
if(xNext >= 0 && xNext < board.length ){
if(yNext >= 0 && yNext < board[0].length){
if(!exist[xNext][yNext] && board[xNext][yNext] == word.charAt(idx)){
exist[xNext][yNext] = true;
if(dfs(board,word,idx + 1,xNext,yNext)) return true;
exist[xNext][yNext] = false;
}
}
}
}
return false;
}
public boolean exist(char[][] board, String word) {
//define row and col of the matrix
int row = board.length;
int col = board[0].length;
exist = new boolean[row][col];
// traverse the board to find the first char
for(int i = 0;i < board.length;i ++){
for(int j = 0;j < board[0].length;j ++){
if(board[i][j] == word.charAt(0)){
//System.out.println("first " + board[i][j]);
exist[i][j] = true;
if(dfs(board,word,1,i,j)) return true;
exist[i][j] = false;
}
}
}
return false;
}
}

代码量真多,不过还是在规定时间内完成了!
参考实现
这里可以将融合到原来的数组中,通过修改特殊的字符,然后判定当前位置是否已经访问过!
分割回文串
题目链接

注意
- 回文串,逆序和顺序都是一样的
- 仅由小写字母构成,不用担心字母大小写变换
- 长度是1到16,可能有边界情况需要特殊考虑!
个人实现
- 这道题是一个组合体,找到所有的组合,然后在判断一下,是否是回文就行了。
- 总结一下回溯的几个要素
- 树的深度:总的元素数量
- 节点的宽度:每一个节点放或者不放两种情况。
错误!!这里审错题目了!是分割字符串,应该然后分割之后每一个字串都是回文
- 修改一下回溯的几个要素
- 树的深度:分割的位置,总的元素数减一,每一个元素都有一个分割点
- 节点的宽度:是否在当前点进行分割
class Solution {
List<String> list = new ArrayList();
List<List<String>> res = new ArrayList<>();
boolean judge(String str){
str = str.trim();
StringBuilder sb = new StringBuilder(str);
sb.reverse();
return str.equals(sb.toString());
}
void dfs(StringBuilder s,int idx,int len){
if(idx == len ){
if(judge(s.toString())){
list.add(s.toString());
res.add(new ArrayList(list));
list.remove(list.size() - 1);
}
return;
}
// cut
int subIdx = len - s.length();
String temp = s.substring(0,idx - subIdx);
//System.out.print("idx:" + idx + " temp:" + s.substring(0,idx - subIdx));
if(judge(temp)){
list.add(temp);
//System.out.println(" subtemp:" + s.substring(idx - subIdx));
dfs(new StringBuilder(s.substring(idx - subIdx)),idx + 1,len);
list.remove(list.size() - 1);
}
// not cut
dfs(s,idx + 1,len);
}
public List<List<String>> partition(String s) {
dfs(new StringBuilder(s),1,s.length());
return res;
}
}

问题
-
StringBuilder获取子串是substring,没有大写,而且也没有简称,不是subString,不是subStr ,都不是!!是substring
- substring(strat_idx):从start_idx到末尾
- substring(start_idx,end_idx):从start_idx到end_idx这段子串 ,不包括end_idx,相当于在end_idx前面一个字符做的分割点
-
String去除空格
- str.trim()去除前后空格
- str.replace(" “,”");
- 正则表达式replaceAll(“\s+”, “”)
-
我这里回溯的角度可能有问题,导致时间上有很多耗费!
参考实现
暴力搜索 + 迭代优化
暴力搜索
- 这里举得是区间长度,也就是区间起点,然后列举区间的终点,不同于我们列举每一个分割点!
- 迭代深度
- 每一区间的起点的位置
- 单次迭代的宽度
*
迭代优化
- 利用了回文字符串的中间子串也一定是回文字符串的特性,具体如下图!
for(int j = 0;j < n;j ++){
for(int i = 0;i <= j;i ++){
if(i == j) f[i][j] = true;
else if(s[i] == s[j]){
if(i + 1 > j -1 || f[i + 1][j - 1]) f[i][j] = true;
}
}
}
具体实现代码
class Solution {
boolean[][] f;
List<String> list = new ArrayList();
List<List<String>> res = new ArrayList<>();
void dfs(String s,int idx){
int m = s.length();
if(idx == m){
res.add(new ArrayList(list));
return ;
}
for(int i = idx ;i < m; i++){
if(f[idx][i]){
//System.out.println("idx:" + idx + " i" + i + " substr:"+s.substring(idx,i+1));
list.add(s.substring(idx,i + 1));
dfs(s,i+1);
list.remove(list.size() - 1);
}
}
}
public List<List<String>> partition(String s) {
int m = s.length();
f = new boolean[m][m];
for(int j = 0;j < m;j ++){
for(int i = 0;i <= j;i ++){
if(i == j) f[i][j] = true;
else if(s.charAt(i) == s.charAt(j)){
if(i + 1 > j - 1 || f[i + 1][j - 1]) f[i][j] = true;
}
}
}
dfs(s,0);
return res;
}
}

确实更快,那个回文推导的得稍微记一下!
环形链表II
- 题目连接


注意 - pos表示-1或者有效索引
- 不用担心数字越界
- 空间复杂度要求是O(1)
个人实现
- 这个明显是用快慢指针,首先判定是否有环,然后在有环的情况下,判定出对应环的起始点!
- 难点在第二步,不过感觉这个环的起始点,之前好像做过。感觉快慢节点在有环的情况下,应该有特殊情况!
这里还是不知道怎么推导出来的,这题挂了!
如果不强制要求空间复杂度的话,只需要一次遍历就能实现!
这里就不写了,没什么意思!
参考实现
- 这里推导的比较绕,我看了很多遍,总结起来就是一句话
- 快慢指针相遇的地方,和链表的头节点分别同时触发一个速度为1的节点遍历,相遇点就是入点
先套一个快慢指针的模板
while(f != null){
f = f.next;
s = s.next;
if(f == null) return false;
f = f.next;
if(f == s) return true;
}
最终实现代码
/**
* Definition for singly-linked list.
* class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode detectCycle(ListNode head) {
if(head == null || head.next == null) return null;
ListNode s = head;
ListNode f = head.next;
// judge whether contains circle
while(f != null){
f = f.next;
s = s.next;
if(f == null) return null;
f = f.next;
if(f == s){
s = head;
f = f.next;
while(s != f) {
s = s.next;
f = f.next;
}
return s;
}
}
return null;
}
}
两个有序链表
- 题目链接


- 第一次练习连接
个人实现
- 这个题目第二次做了,而且是个简单题,直接遍历就行了
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
ListNode head1 = list1;
ListNode head2 = list2;
ListNode dummy = new ListNode();
ListNode temp = dummy;
while(head1 != null && head2 != null){
if(head1.val < head2.val){
temp.next = head1;
head1 = head1.next;
temp = temp.next;
}else{
temp.next = head2;
head2 = head2.next;
temp = temp.next;
}
}
temp.next = (head1 == null ? head2:head1);
return dummy.next;
}
}

题目很简单,但是让我想到了某一次字节的面试,面试官觉得我代码写的太差了,那道题是一个大数加法,使用链表表示的,我最后写的太差了!毕竟我已经换了三道题,感觉完蛋了!
总结
- 今天状态不得行,刷到了第三题,我就厌烦的不行,不过还是得调整一下!
- 真的是,每天刷题,刷的恶心,恶心的不行!后续还是得加油!
- 又搞到好晚,我要睡了!
- 明天面试百度,加油!