HDFS
HDFS 全称 Hadoop Distributed File System,是一个分布式文件系统。HDFS(Hadoop Distributed File System)是 Apache Hadoop 生态系统的一部分,它是一个分布式文件系统,用于存储和处理大规模数据集。HDFS 专门设计用于在具有大量节点的计算集群上存储大规模数据,并提供高可靠性、高吞吐量和容错性。HDFS 的设计灵感来自于 Google 的 GFS(Google File System)。它采用了主从架构,由三个核心组件组成:
- NameNode(nn):存储文件的元数据,如
文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。 - DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2nn):每隔一段时间对 NameNode 元数据备份。
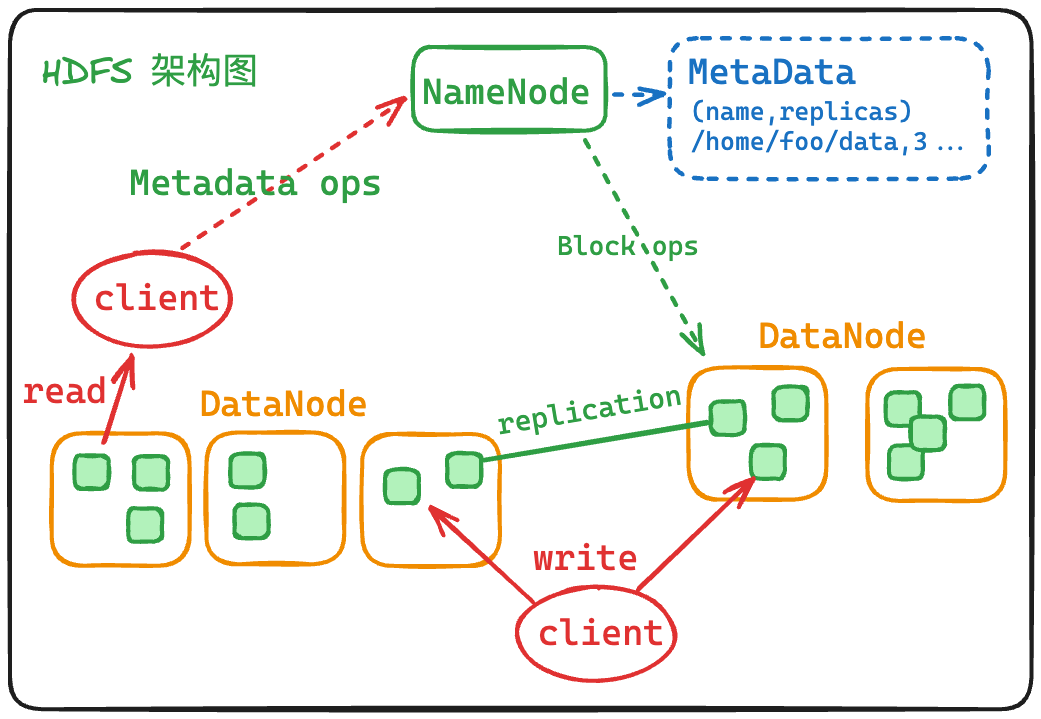
1. HDFS
- 可扩展性:HDFS 可以在
大规模的集群中存储和处理PB级的数据。 - 容错性:HDFS 通过复制数据块来提供
容错性。默认情况下,每个数据块会被复制到多个 DataNode 上,以防止数据丢失。 - 高吞吐量:HDFS 针对批处理工作负载进行了优化,可以实现高吞吐量的数据访问。
- 适合大文件:HDFS 适用于存储和处理
大型文件,而不适合小型文件。
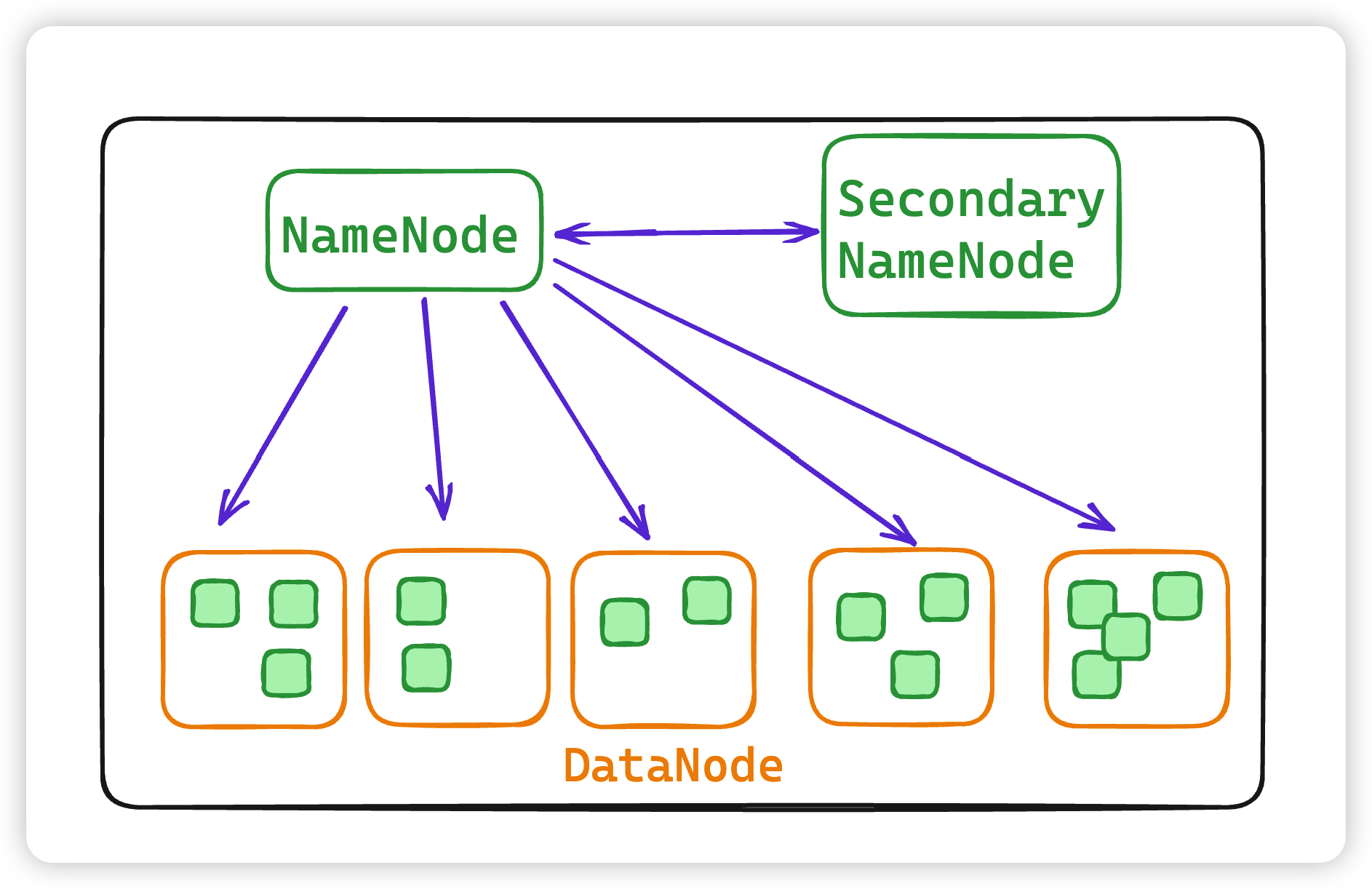
HDFS 遵循主从架构。每个群集包括一个主节点和多个从节点。其中:
- NameNode 是主节点,负责存储和管理文件系统元数据信息,包括 namespace 目录结构、文件块位置信息等
- DataNode 是从节点,负责存储文件具体的数据块。两种角色各司其职,共同协调完成分布式的文件存储服务。
- SecondaryNameNode 是主角色的辅助角色,帮助主角色进行元数据的合并。
2. Namenode
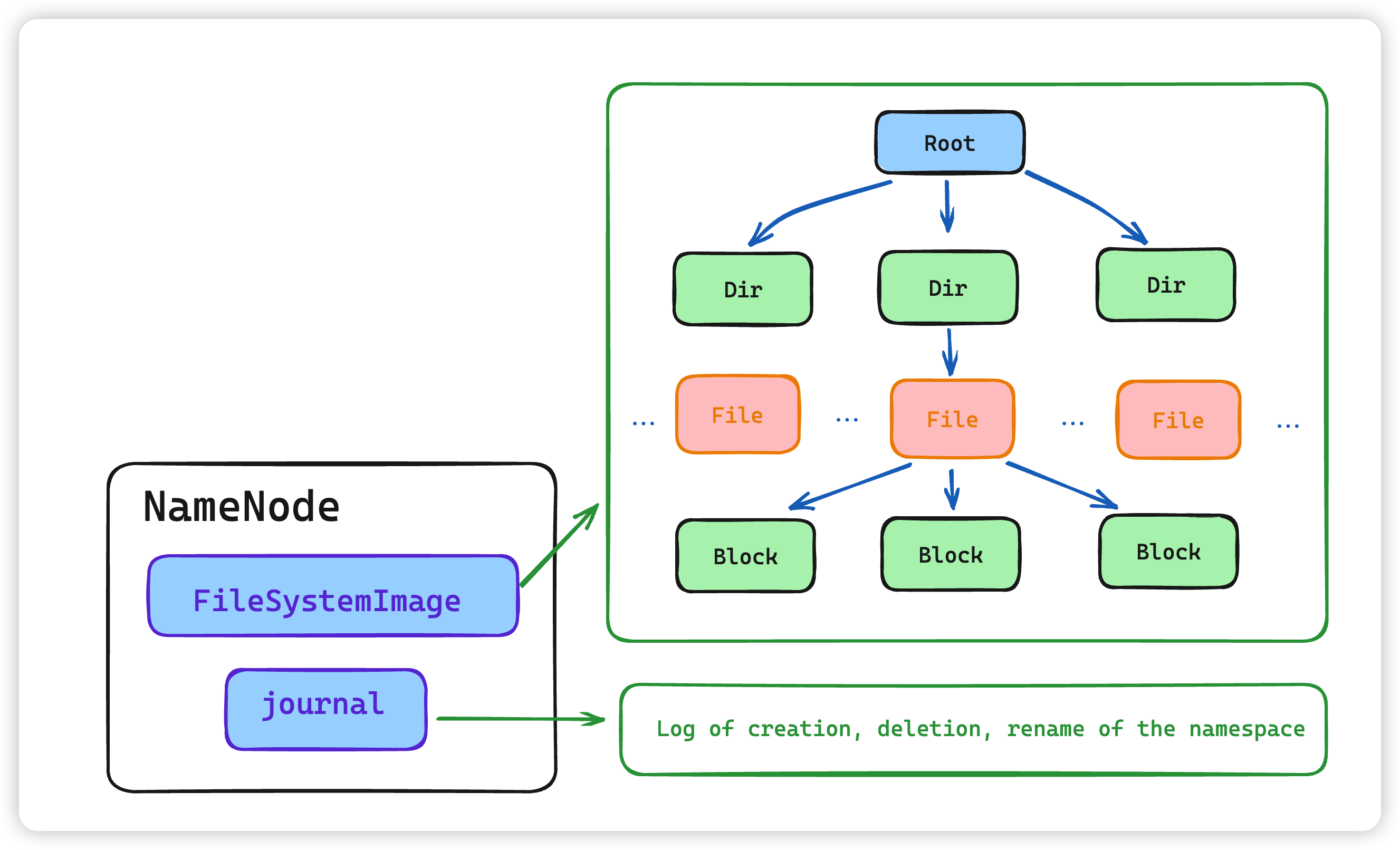
NameNode 是 Hadoop 分布式文件系统的核心,架构中的主角色。它维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。基于此,NameNode 成为了访问 HDFS 的唯一入口。
内部通过内存和磁盘两种方式管理元数据。其中磁盘上的元数据文件包括 Fsimage 内存元数据镜像文件和 edits log(Journal)编辑日志。
管理的元数据具有两种类型:
- 文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。 - 文件块位置映射信息
记录文件块和 DataNode 之间的映射信息,即哪个块位于哪个节点上
HDFS 中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于 hdfs-default.xml 中:dfs.blocksize。默认大小是 128M
3. Datanode
DataNode是 Hadoop HDFS 中的从角色,负责具体的数据块存储。DataNode 的数量决定了 HDFS 集群的整体数据存储能力。通过和 NameNode 配合维护着数据块。
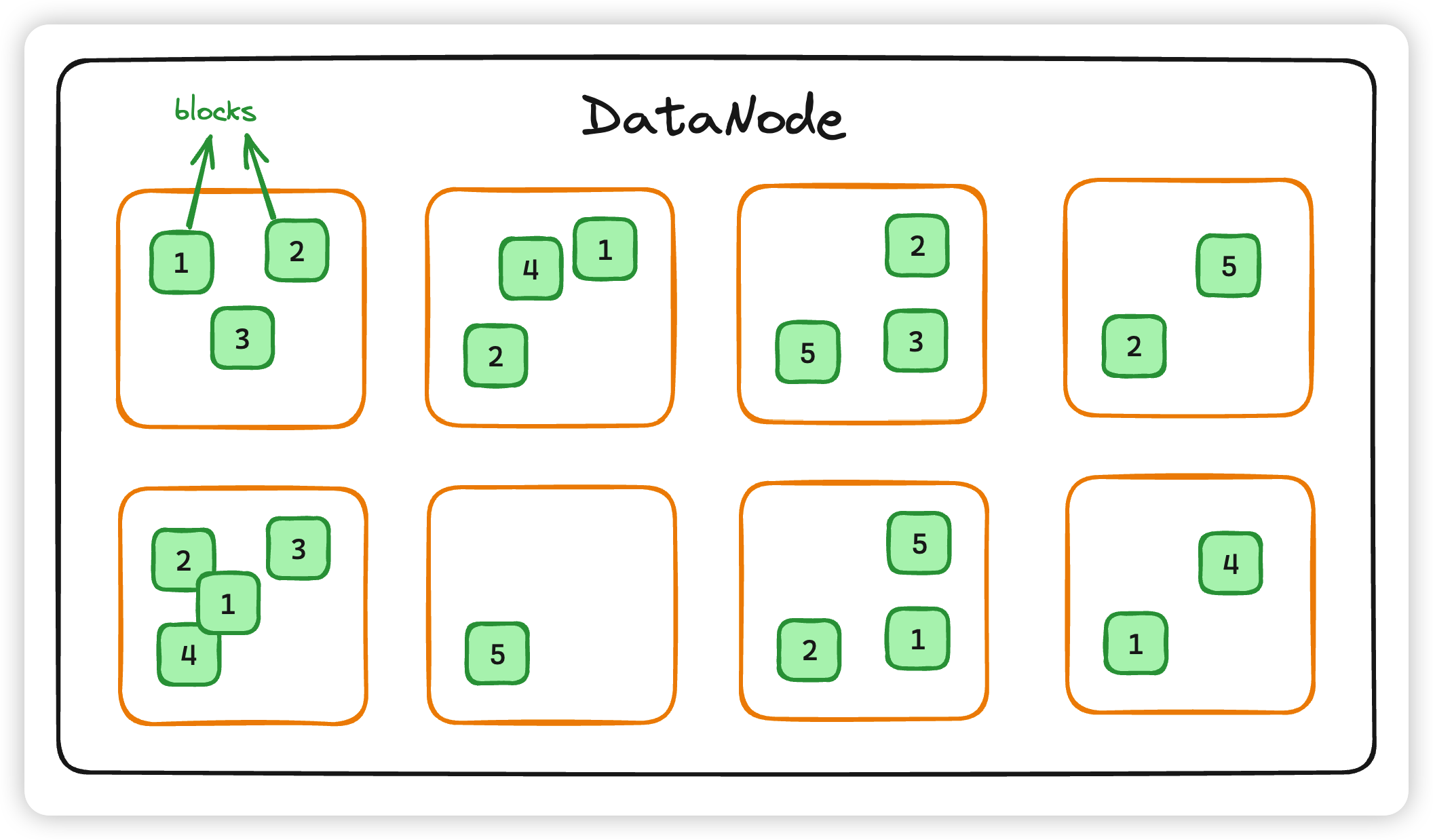
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
默认 dfs.replication 的值是 3,也就是会额外再复制 2 份,连同本身总共 3 份副本。
4. SecondaryNameNode
除了 DataNode 和 NameNode 之外,还有另一个守护进程,它称为 secondary NameNode。充当NameNode 的辅助节点,但不能替代 NameNode。
当 NameNode 启动时,NameNode 合并 Fsimage 和 edits log 文件以还原当前文件系统名称空间。如果 edits log 过大不利于加载,SecondaryNameNode 就辅助 NameNode 从 NameNode 下载 Fsimage 文件和 edits log 文件进行合并。
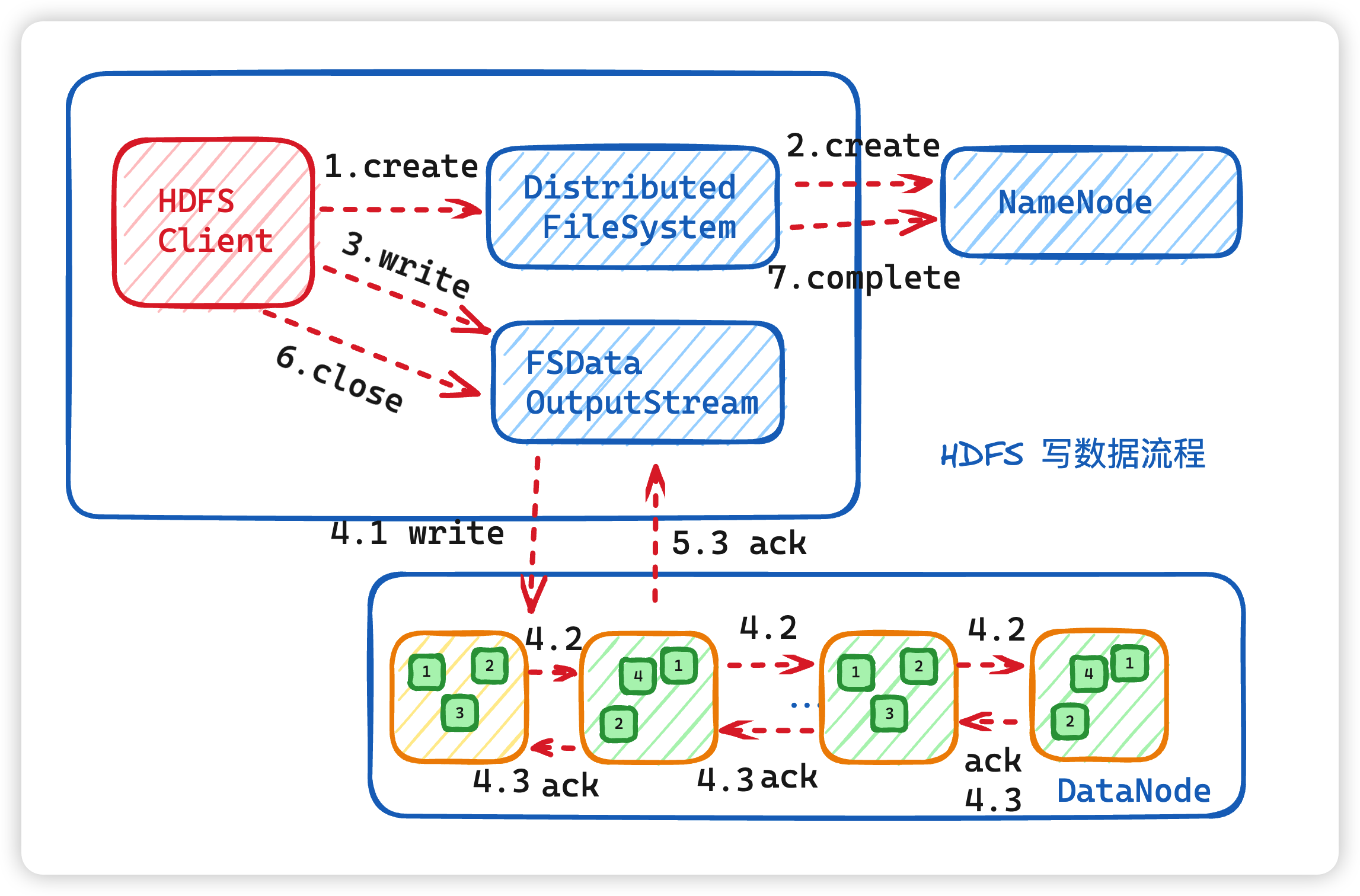
5. 写过程
- HDFS 客户端通过 对
DistributedFileSystem 对象调用create()请求创建文件 DistributedFileSystem对namenode进行RPC调用,请求上传文件。namenode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,namenode 就会为创建新文件记录一条记录。否则,文件创建失败并向客户端抛出 IOException。- DistributedFileSystem 为客户端返回 FSDataOutputStream 输出流对象。由此客户端可以开始写入数据。FSDataOutputStream 是一个包装类,所包装的是 DFSOutputStream。
- 在客户端写入数据时**,DFSOutputStream 将它分成一个个数据包**(packet 默认 64kb),并写入一个称之为数据队列(data queue)的内部队列。DFSOutputStream 有一个内部类做 DataStreamer,用于请求 NameNode 挑选出适合存储数据副本的一组 DataNode。
这一组DataNode采用pipeline机制做数据的发送。默认是3副本存储。 - pipeline 传递数据给 DataNode,
DataStreamer将数据包流式传输到pipeline的第一个datanode,该DataNode存储数据包并将它发送到pipeline的第二个DataNode。同样,第二个 DataNode 存储数据包并且发送给第三个(也是最后一个)DataNode。 - DFSOutputStream 也维护着一个内部数据包队列来等待 DataNode 的收到确认回执,称之为确认队列(ack queue), 收到 pipeline 中所有 DataNode 确认信息后,该数据包才会从确认队列删除。
- 客户端完成数据写入后,将在流上调用 close()方法关闭。
该操作将剩余的所有数据包写入DataNode pipeline,并在联系到 NameNode 告知其文件写入完成之前,等待确认。 - 因为 namenode 已经知道文件由哪些块组成(DataStream 请求分配数据块),因此它仅需等待最小复制块即可成功返回。
- 数据块最小复制是由参数
dfs.namenode.replication.min指定,默认是 1
Pipeline,中文翻译为管道。这是 HDFS 在上传文件写数据过程中采用的一种数据传输方式。客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。通俗描述 pipeline 的过程就是:Client->A->B->C
为什么 datanode 之间采用 pipeline 线性传输,而不是一次给三个 datanode 拓扑式传输呢?因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。
ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。在 pipeline 管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据传输安全。
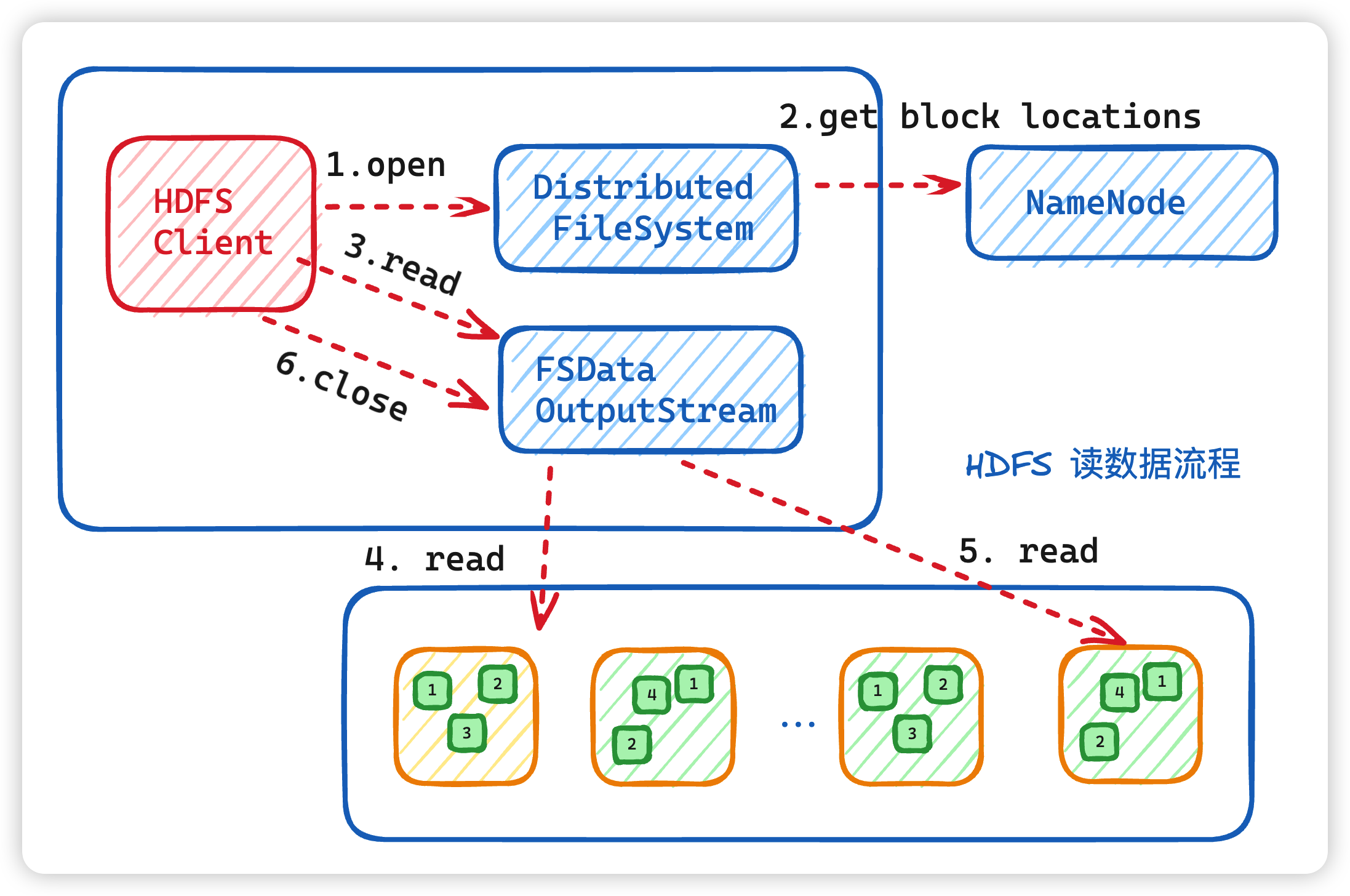
6. 读过程
- 客户端通过调用 DistributedFileSystem 对象上的 open() 来打开希望读取的文件
- DistributedFileSystem 使用 RPC 调用 namenode 来确定文件中前几个块的块位置。对于每个块,namenode 返回具有该块副本的 datanode 的地址,并且 datanode 根据块与客户端的距离进行排序。注意此距离指的是网络拓扑中的距离。比如客户端的本身就是一个 DataNode,那么从本地读取数据明显比跨网络读取数据效率要高。
DistributedFileSystem将FSDataInputStream(支持文件seek定位读的输入流)返回到客户端以供其读取数据。FSDataInputStream 类转而封装为 DFSInputStream 类,DFSInputStream 管理着 datanode 和 namenode 之间的 IO。- 客户端在流上调用 read()方法。然后,已存储着文件前几个块 DataNode 地址的 DFSInputStream 随即连接到文件中第一个块的最近的 DataNode 节点。通过对数据流反复调用 read()方法,可以将数据从 DataNode 传输到客户端。
- 当该块快要读取结束时,DFSInputStream 将关闭与该 DataNode 的连接,然后寻找下一个块的最佳 datanode。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流
- 客户端从流中读取数据时,块是按照打开 DFSInputStream 与 DataNode 新建连接的顺序读取的。它也会根据需要询问 NameNode 来检索下一批数据块的 DataNode 位置信息。一旦客户端完成读取,就对 FSDataInputStream 调用 close() 方法
- 如果 DFSInputStream 与 DataNode 通信时遇到错误,它将尝试该块的下一个最接近的 DataNode 读取数据。并将记住发生故障的 DataNode,保证以后不会反复读取该 DataNode 后续的块。此外,DFSInputStream 也会通过校验和(checksum)确认从 DataNode 发来的数据是否完整。如果发现有损坏的块,DFSInputStream 会尝试从其他 DataNode 读取该块的副本,也会将被损坏的块报告给 namenode