摘要
- 自然图像区域视觉提示使用户可以通过各种视觉标记,如框、点和其他形状,和AI进行交互。但是,自然图像和RS图像之间存在显著差异,现有的视觉提示模型在RS场景中面临着挑战。此外,RS MLLMs主要关注于解释图像级RS数据,只支持与语言指令进行交互,限制了在现时世界的灵活性应用。
- 为此,本文提出一种新的视觉提示模型,擅长图像级、区域级和点级的RS图像解释。具体来说:
- 视觉提示与图像和文本指令输入到LLM,使模型适应特定的预测和任务。
- 随后,引入了一种共享视觉编码方法,以统一细化多尺度图像特征和视觉提示信息。
- 此外,为了赋予EarthMarker多粒度视觉感知能力。设计了跨领域阶段学习策略,并通过利用自然和RS领域特定知识,以轻量级的方式优化不相交的参数。
- 此外,为了解决RS视觉提示数据不足的问题,构建了一个具有多模态细粒度视觉提示指令的RSVP数据集。大量的实验被用来证明了所提出的EarthMarker的竞争性能,代表了在视觉提示学习框架下多粒度RS图像解释方面的显著进步。
方法
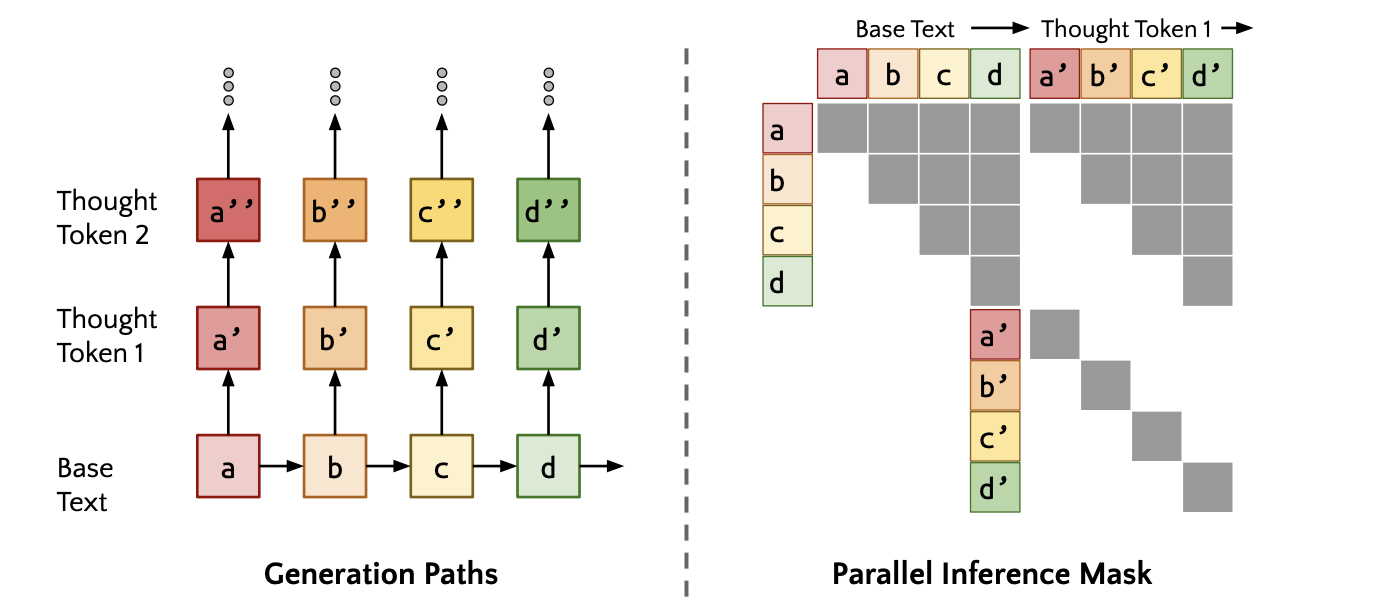
- 如图1所示,EarthMarker可以完成图像级、区域级和点级的RS图像解释,如场景分类、字幕等。

- 如图2所示,EarthMarker包含四个核心组件:共享的视觉编码机制、模式对齐映射层、文本标记器模块和LLM解码器。

- 图像和相应的视觉提示使用共享的视觉编码机制,使用Mixture of Visual Experts (MoV)编码视觉信息,包含两个编码器DINOv2-ViT L/14和CLIP-ConvNeXt,在不同的网络架构上进行预训练(ViT和CNN),以提供互补的视觉语义。为了细化鲁棒的多尺度视觉特征,将输入的图像
降采样到不同的分辨率,即
,然后分别输入MoV模块进行编码。随后,将编码后的视觉特征转换为相同的维度,并沿通道维度连接,得到多尺度特征图
。这个过程可以简单地表述为:
。
- 编码器共享机制的一个关键步骤是“Visual Prompt as Images”。特别是,视觉提示的维度(H×W×1)被处理到与图像相同的维度(H×W×3)。然后,转换后的视觉提示P也可以与图像一起输入MoV,编码的视觉提示表示为
。同样地,这个过程也被写成:
- 随后,模态对齐投影层Φ将视觉tokens转换为语言语义空间。同时,文本指令由tokenizer module进行处理,该模块处理文本tokenization和embedding,并将其转换为文本embeddings
。在获得projected image tokens, visual prompts tokes和text instructions embeddings后,它们被集成到一个完整的多模态输入序列中。LLM解码器接受多模态输入并生成响应序列Y,公式为:
- 使用Llama 2,一个基于变压器的解码器的LLM,作为LLM解码器。
-
Cross-domain Phased Training
- 整个训练过程分为multi-domain image-text alignment、spatial perception tuning和RS visual prompting tuning stage三个阶段。在整个训练过程中,一直保持着轻量级的训练,并避免了昂贵的full-parameters tuning。此外,还提出了disjoint parameters strategy,即各阶段的更新参数都不同。
-
Multi-domain Image-text Alignment:自然和RS图像都被用于预训练,自然场景字幕数据集COCO Caption和新构建的RSVP的RS图像标题和场景分类子集。在这个训练阶段,多尺度的视觉特征和语言表示被集成到LLM中,以发展图像级的理解能力。MoV模块在整个训练过程中都保持冻结,以便专注于改进健壮的视觉特征。只更新对齐映射层参数,以增强多模态能力,并确保视觉和文本信息的无缝集成。
-
Spatial Perception Tuning:为了获取空间感知和对象级理解,将自然场景公开可用的数据集RefCOCO和RefCoCOCO+被转换为instruction-following格式。在整个训练过程中,LLM的注意层被解冻,以将空间区域特征与语言嵌入对齐。冻结其他模块。
- RS Visual Prompting Tuning:该阶段是准确地遵循用户指令,实现复杂的区域级和点级视觉推理任务。MoV、对齐映射和LLM都是固定的。调优采用了LoRA方法。加载在上一阶段训练的权重,并继续训练EarthMarker的RSVP-3M region-text and point-text parings,其中包含细粒度的对象分类标签和简短的标题数据标签。具体地说,将几个可学习的低秩适配器矩阵
插入到LLM的transformer层中。自适应的多头注意力表示为
,第1个自适应的变压器注意力的输出表示为

数据集RSVP-3M构建
基于现有的公开的RS数据集,并使用GPT-4V进行自动注释。
-
Data Conversion and Annotation from Public RS Datasets
- 如表一,图像级、区域级和点级的数据来自于不同的RS数据集。
- 首先,图像分类和字幕数据集转换为图像级视觉提示数据。对于这两种类型的数据集,使用了图像级的视觉指令,以边界框[0, 0, width, height]作为视觉提示,以获得图像的类别或简要标题。
- 随后,区域级的数据是基于目标检测数据集。地面真实边界框被用作视觉提示,以指导模型准确地识别对象级或区域级的类别。此外,点级数据也从分割数据集上进行了转换。例如,对于分割,从实例对应的掩码中提取的代表性点被用作点级的视觉提示。语义分割时,每幅图像分为32个×32个块,每个块内随机采样点作为视觉提示,从相应的分割图中检索类别。
-

- 在RSVP-3M中,每个数据项都由visual prompts、user instructions和images组成。user instructions或model answers的visual prompts被表示为< Mark i >或< Region i >。例如,对于点级数据,指导参考对象分类的用户指令是“Please identify the category of each marked point in the image”。答案格式是“< Mark 1>: Label 1\n <Mark 2>: Label 2\n, ..., ‘points : [x1, y1], [x2, y2], ...”。另外,对于区域级数据,以机场现场为例。机场区域字幕的用户说明是“Please provide the brief caption of each marked region in the image”
,和相应的回答格式生成的模型是“< Region 1 >: A big airplane on the left\n < Region 2>:A small vehicle on the top\n, ..., ‘bbox′ : [x1, y1, x2, y2], ...”。其他视觉任务的数据结构与上面解释的类似。通过基于公共数据集的转换和重新标注,有效地开发了具有图像点-文本和图像-区域-文本配对功能的可视化提示数据集RSVP-3M。
-
GPT4V-assisted Visual Prompting Data Generation
- 上述公共数据集仅提供了简单的分类信息和简短的说明,不足以智能解释复杂的RS图像。为解决此限制,并开发一个更详细和明确的RS视觉提示数据集,制作GPT-4V的语言提示,用于生成具有复杂视觉推理的数据。采用Set-of-Marks(SoM)提示,更好的使用GPT-4V的visual grounding能力,从RS图像中获得全面而独特的特征。
实验
Scene Classification

Image Captioning
 Referring Object Classification
Referring Object Classification


Region Captioning


Complex Visual Reasoning