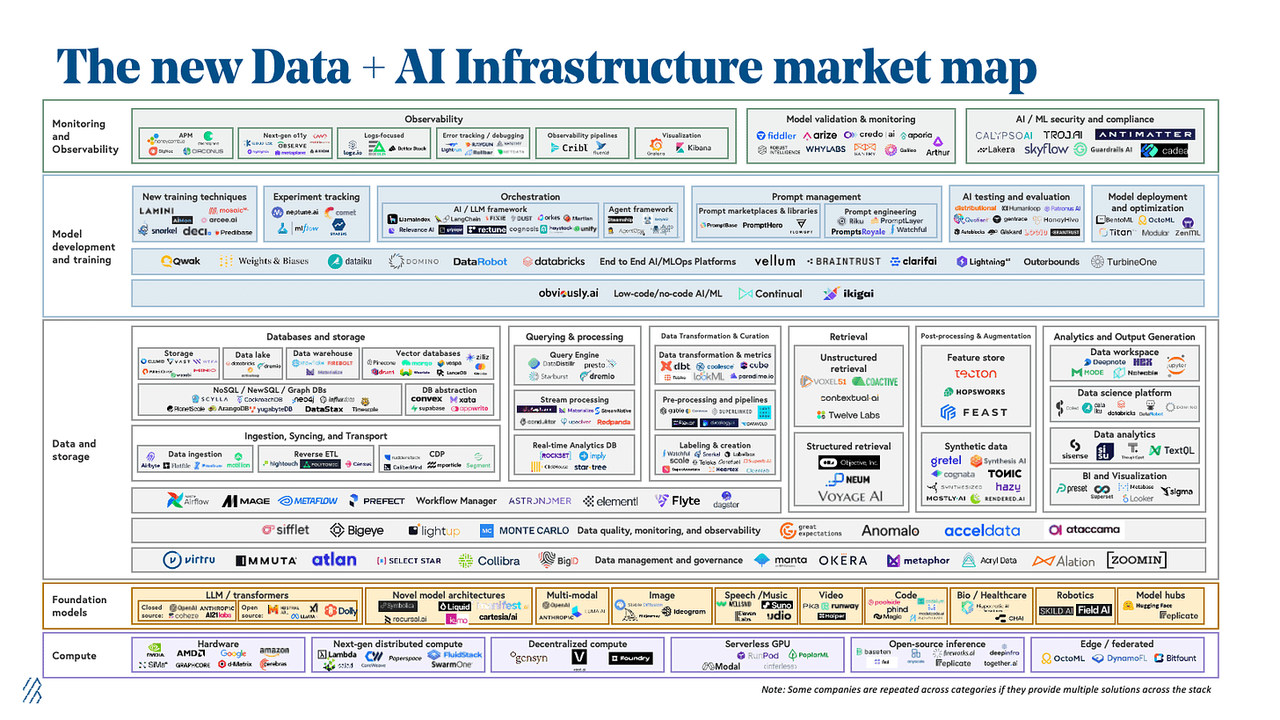
文章目录
- Robust deep alignment network with remote sensing knowledge graph for zero-shot and generalized zero-shot remote sensing image scene classification
- 相关资料
- 摘要
- 引言
- 遥感知识图谱的表示学习
- 遥感知识图谱的构建
- 实体和关系的语义表示学习
- 创建遥感场景类别的语义表示
- 鲁棒深度对齐网络用于零样本和广义零样本遥感图像场景分类
- 零样本学习(ZSL)和广义零样本学习(GZSL)的定义
- 潜在空间中的鲁棒深度对齐网络
- 视觉特征和语义表示的重建
- 跨模态特征重建(CMFR)
- 视觉和语义分布匹配(VSDM)
- 多类别分布分散(MCDD)
- 实验
- 实验
Robust deep alignment network with remote sensing knowledge graph for zero-shot and generalized zero-shot remote sensing image scene classification
相关资料
论文:Robust deep alignment network with remote sensing knowledge graph for zero-shot and generalized zero-shot remote sensing image scene classification - ScienceDirect
代码:kdy2021/SR-RSKG (github.com)
摘要
尽管深度学习已经彻底改变了遥感图像场景分类,但当前基于深度学习的方法高度依赖于预定场景类别的大量监督,并且对于超出预定场景类别的新类别表现不佳。实际上,随着涉及遥感图像场景新类别的新应用的出现,分类任务通常需要扩展,因此如何使深度学习模型具备识别训练阶段未预定场景类别之外的未见遥感图像场景的推理能力变得非常重要。本文充分利用遥感领域的特征,从头构建了一个新的遥感知识图谱(RSKG),以支持未见遥感图像场景的推理识别。为了提高面向遥感的场景类别的语义表示能力,本文提出通过遥感知识图谱的表示学习生成场景类别的语义表示(SR-RSKG)。为了追求视觉特征和语义表示之间鲁棒的跨模态匹配,本文提出了一种新型的深度对齐网络(DAN),并设计了一系列优化约束,可以同时解决零样本和广义零样本遥感图像场景分类问题。在多个公开数据集的集成遥感图像场景数据集上的广泛实验表明,所提出的SR-RSKG明显优于传统知识类型(例如,自然语言处理模型和手动注释的属性向量),并且在零样本和广义零样本遥感图像场景分类设置下,我们提出的DAN与现有最先进方法相比表现出更好的性能。构建的RSKG将与本文一起公开提供(https://github.com/kdy2021/SR-RSKG)。
引言
零样本学习(ZSL)近年来的发展为识别未见类别的样本提供了有希望的解决方案。通过利用包括看到和未见类别在内的类别的先验知识作为辅助信息,ZSL可以学习从看到类别的样本中识别未见类别的样本。通常,看到和未见类别的语义信息是人类的常识,这是普遍的,可以在训练和测试阶段使用,但是训练阶段不存在未见类别的图像样本。因此,如何表达语义是追求ZSL优越性能的关键。
与计算机视觉领域相比,遥感领域的特点限制了ZSL和GZSL的发展:
- 遥感场景类别的名称通常具有领域特异性。如果直接利用通用自然语言处理模型(例如,Word2Vec)将遥感场景类别的名称映射为语义表示,那么这些语义表示就不能反映遥感类别的内在语义信息。
- 遥感图像场景通常具有大的类内差异和大的类间相似性,通常比计算机视觉领域的自然图像具有更复杂的外观。通常,在计算机视觉领域取得优异结果的ZSL和GZSL方法不能直接扩展到遥感领域的任务。总的来说,推动零样本和广义零样本遥感图像场景分类的发展值得更多的探索。
为了生成高质量的遥感场景类别的语义表示,本文基于人类专家的领域先验知识构建了一个新的遥感知识图谱(Remote Sensing Knowledge Graph, RSKG),其中RSKG充分考虑了遥感场景元素之间丰富的联系。据我们所知,本文首次提出通过遥感知识图谱的表示学习来计算遥感场景类别的语义表示(Semantic Representations of RS scene categories by representation learning of RSKG, SR-RSKG)。基于SR-RSKG,本文提出了一个新的深度对齐网络(Deep Alignment Network, DAN),并设计了一系列精心设计的约束条件,该网络可以在潜在空间中稳健地匹配视觉特征和语义表示,以解决零样本和广义零样本遥感图像场景分类问题。
遥感知识图谱的表示学习
遥感知识图谱的构建

为了支持零样本遥感图像场景分类,我们基于遥感场景元素构建了一个新的知识图谱(即RSKG)。值得注意的是,RS场景不仅仅是一系列对象的集合,它还包含了对象之间丰富的关系。结合遥感图像内容的特点以及地理空间关系的相关研究,我们定义了RSKG中的关系如下:
我们将关系分为两类:属性关系和空间关系
-
属性关系用于描述对象的特征或与其他对象的父子关系,可以进一步细分为数据关系和对象关系。数据关系包括形状、颜色、宽度、分布和高度;对象关系包括“拥有”、“组成部分”、“部分”和“成员”。
-
空间关系主要描述空间中不同对象之间的位置关系,可以细分为位置关系、拓扑关系和模糊关系。位置关系包括“标出”、“停靠”、“停止”、“在上方”和“在上方”;拓扑关系包括“被包围”、“在…交叉”、“通过”、“遇见”、“连接”、“覆盖”、“包含”和“在内”;模糊关系包括“靠近”、“旁边”、“周围”和“沿着”。

当前版本的RSKG包含117个实体、26种关系和191个三元组。
实体和关系的语义表示学习

对于知识图谱中的每个三元组(h, r, t),TransE模型假设头部实体向量加上关系向量大约等于尾部实体向量。然而,TransE模型无法处理知识图谱中出现的1-N或N-1等复杂关系。为了解决这个问题,我们推荐使用改进的表示学习模型TransH,它通过将关系建模为超平面上的平移操作来灵活处理复杂关系。
在TransH模型中,给定的嵌入向量ch和ct被映射到超平面上,通过计算 c h ⊥ = c h − w r ⊺ c h w r c_{h_⊥} = c_h − w^⊺_rc_hw_r ch⊥=ch−wr⊺chwr和 c t ⊥ = c t − w r ⊺ c t w r c_{t_⊥} = c_t − w^⊺_rc_tw_r ct⊥=ct−wr⊺ctwr,其中 w r w_r wr是超平面的法向量。然后,通过最小化目标函数来优化嵌入向量,目标函数定义为:
f r ( h , t ) = ∥ c h ⊥ + c r − c t ⊥ ∥ 2 2 f_r(h, t) = \| c_{h_⊥} + c_r - c_{t_⊥} \|^2_2 fr(h,t)=∥ch⊥+cr−ct⊥∥22
通过最小化损失函数:
L T r a n s H = ∑ ( h , r , t ) ∈ Δ ∑ ( h ′ , r ′ , t ′ ) ∈ Δ ′ max ( f r ( h , t ) + τ − f r ( h ′ , t ′ ) , 0 ) L_{TransH} = \sum_{(h,r,t) \in \Delta} \sum_{(h',r',t') \in \Delta'} \max(f_r(h, t) + \tau - f_r(h', t'), 0) LTransH=∑(h,r,t)∈Δ∑(h′,r′,t′)∈Δ′max(fr(h,t)+τ−fr(h′,t′),0)
其中Δ是正确三元组的集合,Δ’是错误的三元组集合,τ是正确三元组和错误三元组分数之间的最小间隔,通常设置为1。通过优化目标函数,我们可以获得SR-RSKG。
创建遥感场景类别的语义表示

为了全面评估零样本和广义零样本遥感图像场景分类的性能,我们采用了一个合并的数据集,该数据集整合了五个公共数据集:UCM、AID、NWPU-RESISC45、RSI-CB256和PatternNet。合并的遥感图像场景数据集由70个场景类别组成,每个类别包含800个图像场景,图像尺寸为256×256像素。如前所述,RSKG的构建考虑了尽可能多的遥感对象和场景类别的细节,因此RSKG中的实体通常涵盖了特定数据集中的场景类别。简而言之,特定任务中的场景类别可以在RSKG中找到相应的实体。
假设 Y = { y 1 , y 2 , . . . , y M } Y = \{y_1, y_2, ..., y_M\} Y={y1,y2,...,yM}表示遥感场景类别的标签集,其中 M M M表示数据集中场景类别的数量。对于每个标签 y i ∈ Y y_i \in Y yi∈Y,RSKG中的实体与 y i y_i yi(即场景类别)有一一对应关系,我们将实体对应的语义表示记为 c i ∈ C c_i \in C ci∈C。值得注意的是,构建的RSKG中的实体不仅包括本文中采用的遥感场景分类数据集的场景类别,还包括其他可能的实体或同义词。因此,只要场景类别可以从RSKG中找到实体或同义词,其他遥感场景分类任务也可以灵活地使用RSKG。
鲁棒深度对齐网络用于零样本和广义零样本遥感图像场景分类
零样本学习(ZSL)和广义零样本学习(GZSL)的定义
ZSL任务的定义如下:设 D s = { ( x s i , y s i , c ( y s i ) ) ∣ i = 1 , 2 , . . . , N } D_s = \{ (x_s^i, y_s^i, c(y_s^i)) \mid i = 1, 2, ..., N \} Ds={(xsi,ysi,c(ysi))∣i=1,2,...,N}表示训练样本集(即已见样本)。具体来说, x s i ∈ X s x_s^i \in X_s xsi∈Xs表示来自已见类别的第i个遥感图像场景的视觉图像特征,其中图像特征是由CNN模型提取的。 y s y_s ys表示来自已见类别的第i个遥感图像场景的标签, c ( y s ) ∈ C s c(y_s) \in C_s c(ys)∈Cs表示相应类别的语义表示(例如,SR-RSKG)。N表示训练样本的数量。同样,我们定义 X u , Y u , C u X_u, Y_u, C_u Xu,Yu,Cu为未见过的视觉图像特征、相应的标签和语义表示。众所周知,对于ZSL和GZSL,已见类别和未见类别是不相交的,即 Y s ∩ Y u = ∅ Y_s \cap Y_u = \emptyset Ys∩Yu=∅。给定训练数据集 D s D_s Ds和 { Y u , C u } \{Y_u, C_u\} {Yu,Cu},在传统的ZSL中,任务是学习一个分类器 F Z S L : X u → Y u F_{ZSL}: X_u \rightarrow Y_u FZSL:Xu→Yu。在GZSL中,任务是学习一个分类器 F G Z S L : X s ∪ X u → Y s ∪ Y u F_{GZSL}: X_s \cup X_u \rightarrow Y_s \cup Y_u FGZSL:Xs∪Xu→Ys∪Yu。
潜在空间中的鲁棒深度对齐网络

我们不是从视觉空间到语义空间或从语义空间到视觉空间学习映射,而是在潜在空间中学习视觉特征和语义表示的映射,以便我们可以减轻ZSL中的中心性问题(hubness problem)并增强视觉-语义耦合。
首先,我们最小化视觉和语义表示的重建损失。然后,我们在隐藏空间中对齐视觉和语义的分布,这进一步在对齐视觉特征和语义表示的基础上分离了不同类别的特征分布,提高了ZSL任务的性能。
此外,该方法基于潜在空间映射和生成训练样本的方法来训练分类器,平衡了已见和未见类别的分类性能,因此在GZSL任务中也表现出色。值得注意的是,所提到的深度对齐网络本质上试图解决文献中存在的协调表示问题。
L = L V A E + α L C M F R + β L V S D M + γ L M C D D L = L_{VAE} + \alpha L_{CMFR} + \beta L_{VSDM} + \gamma L_{MCDD} L=LVAE+αLCMFR+βLVSDM+γLMCDD
其中 α、β 和 γ 分别是跨模态特征重建损失、视觉和语义分布匹配损失以及多类别分布分散损失的权重因子。
视觉特征和语义表示的重建
由于我们提出的方法在潜在空间中学习视觉特征和语义表示的映射,我们首先需要确保每种模态在潜在空间中的表示能力。此外,为了最小化信息的丢失,应尽可能使用潜在向量重建原始数据。因此,我们遵循VAE网络的架构来学习视觉特征和语义表示的重建模型,将视觉特征和语义表示投影到潜在空间中。

跨模态特征重建(CMFR)
通过视觉特征和语义表示的重建,我们学习了潜在空间中视觉特征和语义表示的表示。接下来,我们需要在潜在空间中对齐它们的表示。我们从两个方面实现这一点。首先是跨模态特征重建(CMFR)。在这里,视觉特征和语义表示交叉输入到另一种模态的编码器中,跨模态特征重建的损失函数可以由公式(5)定义。

其中 N 表示训练样本的数量, x i x_i xi和 c i c_i ci分别表示同一类别的视觉特征和语义表示。
视觉和语义分布匹配(VSDM)
第二是视觉和语义分布匹配(VSDM)。视觉特征和语义表示在潜在空间中的分布由 μ ( v ) i , σ ( v ) i \mu(v)_i, \sigma(v)_i μ(v)i,σ(v)i和 μ ( a ) i , σ ( a ) i \mu(a)_i, \sigma(a)_i μ(a)i,σ(a)i确定。我们通过减少它们之间的距离,进一步匹配潜在空间中视觉特征和语义表示的分布,视觉和语义分布匹配的损失函数可以由公式(6)定义。

其中 N 表示训练样本的数量, μ ( v ) i \mu(v)_i μ(v)i和 σ ( v ) i \sigma(v)_i σ(v)i分别表示潜在空间中视觉特征分布的均值和标准差, μ ( a ) i \mu(a)_i μ(a)i和 σ ( a ) i \sigma(a)_i σ(a)i分别表示潜在空间中语义表示分布的均值和标准差。
多类别分布分散(MCDD)
正如我们之前提到的,遥感图像场景具有显著的类间相似性特征,这对分类任务非常不利。为此,我们增加了约束条件,使潜在空间中不同类别的分布更加分散,多类别分布分散的损失函数可以由公式(7)定义。

其中 V = [ μ ( a ) 1 , μ ( a ) 2 , . . . , μ ( a ) N ] ∈ R d × N [ \mu(a)_1, \mu(a)_2, ..., \mu(a)_N ] \in \mathbb{R}^{d \times N} [μ(a)1,μ(a)2,...,μ(a)N]∈Rd×N,H = ( N ⋅ P − W ) / N (N \cdot P - W) / N (N⋅P−W)/N,P ∈ R N × N \mathbb{R}^{N \times N} RN×N表示单位矩阵,W ∈ R N × N \mathbb{R}^{N \times N} RN×N表示所有元素都等于1的矩阵,I ∈ R d × d \mathbb{R}^{d \times d} Rd×d是单位矩阵。
实验
N × N N \times N N×N表示单位矩阵, W ∈ R N × N W ∈\mathbb{R}^{N \times N} W∈RN×N表示所有元素都等于1的矩阵, I ∈ R d × d I ∈\mathbb{R}^{d \times d} I∈Rd×d是单位矩阵。
实验



![【MySQL-17】存储过程-[变量篇]详解-(系统变量&用户定义变量&局部变量)](https://i-blog.csdnimg.cn/direct/1dbf2ba9d33b46efbdbc8744b150b210.png)