NameNode HA 背景
在Hadoop1中NameNode存在一个单点故障问题,如果NameNode所在的机器发生故障,整个集群就将不可用(Hadoop1中虽然有个SecorndaryNameNode,但是它并不是NameNode的备份,它只是NameNode的一个助理,协助NameNode工作,SecorndaryNameNode会对fsimage和edits文件进行合并,并推送给NameNode,防止因edits文件过大,导致NameNode重启变慢),这是Hadoop1的不可靠实现。
在Hadoop2中这个问题得以解决,Hadoop2中的高可靠性是指同时启动NameNode,其中一个处于active工作状态,另外一个处于随时待命standby状态。这样,当一个NameNode所在的服务器宕机时,可以在数据不丢失的情况下,手工或者自动切换到另一个NameNode提供服务。这些NameNode之间通过共享数据,保证数据的状态一致。多个NameNode之间共享数据,可以通过Network File System或者Quorum Journal Node。前者是通过Linux共享的文件系统,属于操作系统的配置,后者是Hadoop自身的东西,属于软件的配置。
注意:
1) NameNode HA 与HDFS Federation都有多个NameNode,当NameNode作用不同,在HDFS Federation联邦机制中多个NameNode解决了内存受限问题,而在NameNode HA中多个NameNode解决了NameNode单点故障问题。
2) 在Hadoop2.x版本中,NameNode HA 支持2个节点,在Hadoop3.x版本中,NameNode高可用可以支持多台节点。
NameNode HA实现原理
NameNode中存储了HDFS中所有元数据信息(包括用户操作元数据和block元数据),在NameNode HA中,当Active NameNode(ANN)挂掉后,StandbyNameNode(SNN)要及时顶上,这就需要将所有的元数据同步到SNN节点。如向HDFS中写入一个文件时,如果元数据同步写入ANN和SNN,那么当SNN挂掉势必会影响ANN,所以元数据需要异步写入ANN和SNN中。如果某时刻ANN刚好挂掉,但却没有及时将元数据异步写入到SNN也会引起数据丢失,所以向SNN同步元数据需要引入第三方存储,在HA方案中叫做“共享存储”。每次向HDFS中写入文件时,需要将edits log同步写入共享存储,这个步骤成功才能认定写文件成功,然后SNN定期从共享存储中同步editslog,以便拥有完整元数据便于ANN挂掉后进行主备切换。
HDFS将Cloudera公司实现的QJM(Quorum Journal Manager)方案作为默认的共享存储实现。在QJM方案中注意如下几点:
* 基于QJM的共享存储系统主要用于保存Editslog,并不保存FSImage文件,FSImage文件还是在NameNode本地磁盘中。
* QJM共享存储采用多个称为JournalNode的节点组成的JournalNode集群来存储EditsLog。每个JournalNode保存同样的EditsLog副本。
* 每次NameNode写EditsLog时,除了向本地磁盘写入EditsLog外,也会并行的向JournalNode集群中每个JournalNode发送写请求,只要大多数的JournalNode节点返回成功就认为向JournalNode集群中写入EditsLog成功。
* 如果有2N+1台JournalNode,那么根据大多数的原则,最多可以容忍有N台JournalNode节点挂掉。
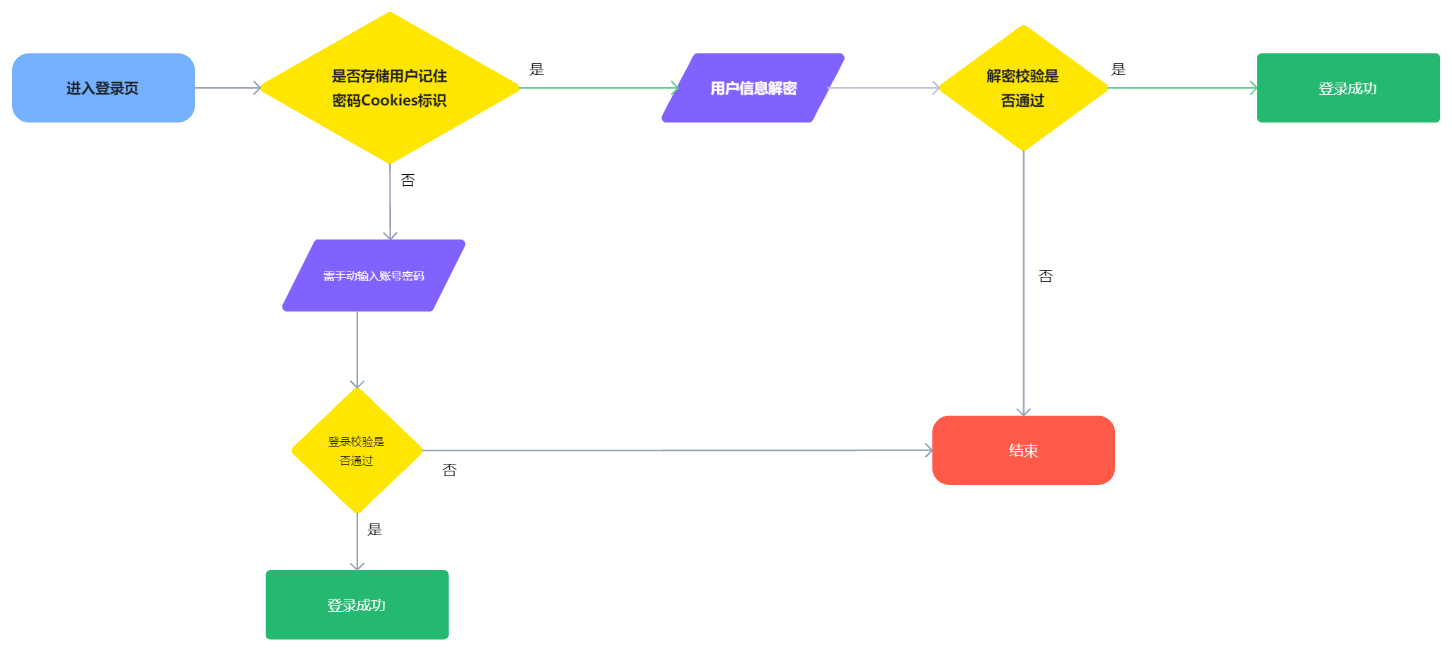
NameNode HA 实现原理图如下:

当客户端操作HDFS集群时,Active NameNode 首先把 EditLog 提交到 JournalNode 集群,然后 Standby NameNode 再从 JournalNode 集群定时同步 EditLog。当处 于 Standby 状态的 NameNode 转换为 Active 状态的时候,有可能上一个 Active NameNode 发生了异常退出,那么 JournalNode 集群中各个 JournalNode 上的 EditLog 就可能会处于不一致的状态,所以首先要做的事情就是让 JournalNode 集群中各个节点上的 EditLog 恢复为一致,然后Standby NameNode会从JournalNode集群中同步EditsLog,然后对外提供服务。
注意:在NameNode HA中不再需要SecondaryNameNode角色,该角色被StandbyNameNode替代。
通过Journal Node实现NameNode HA时,可以手动将Standby NameNode切换成Active NameNode,也可以通过自动方式实现NameNode切换。
上图需要手动进行切换StandbyNamenode为Active NameNode,对于高可用场景时效性较低,那么可以通过zookeeper进行协调自动实现NameNode HA,实现代码通过Zookeeper来检测Activate NameNode节点是否挂掉,如果挂掉立即将Standby NameNode切换成Active NameNode,这种方式也是生产环境中常用情况。其原理如下:

上图中引入了zookeeper作为分布式协调器来完成NameNode自动选主,以上各个角色解释如下:
* AcitveNameNode:主 NameNode,只有主NameNode才能对外提供读写服务。
* Secondby NameNode:备用NameNode,定时同步Journal集群中的editslog元数据。
* ZKFailoverController:ZKFailoverController 作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFailoverController 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换。
* Zookeeper集群:分布式协调器,NameNode选主使用。
* Journal集群:Journal集群作为共享存储系统保存HDFS运行过程中的元数据,ANN和SNN通过Journal集群实现元数据同步。
* DataNode节点:除了通过共享存储系统共享 HDFS 的元数据信息之外,主 NameNode 和备 NameNode 还需要共享 HDFS 的数据块和 DataNode 之间的映射关系。DataNode 会同时向主 NameNode 和备 NameNode 上报数据块的位置信息。
NameNode主备切换流程
NameNode 主备切换主要由 ZKFailoverController、HealthMonitor 和 ActiveStandbyElector 这 3 个组件来协同实现:
* ZKFailoverController 作为 NameNode 机器上一个独立的进程启动 (在 hdfs 集群中进程名为 zkfc),启动的时候会创建 HealthMonitor 和 ActiveStandbyElector 这两个主要的内部组件,ZKFailoverController 在创建 HealthMonitor 和 ActiveStandbyElector 的同时,也会向 HealthMonitor 和 ActiveStandbyElector 注册相应的回调方法。
* HealthMonitor 主要负责检测 NameNode 的健康状态,如果检测到 NameNode 的状态发生变化,会回调 ZKFailoverController 的相应方法进行自动的主备选举。
* ActiveStandbyElector 主要负责完成自动的主备选举,内部封装了 Zookeeper 的处理逻辑,一旦 Zookeeper 主备选举完成,会回调 ZKFailoverController 的相应方法来进行 NameNode 的主备状态切换。
NameNode主备切换流程如下:

1) HealthMonitor 初始化完成之后会启动内部的线程来定时调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法,对 NameNode 的健康状态进行检测。
2) HealthMonitor 如果检测到 NameNode 的健康状态发生变化,会回调 ZKFailoverController 注册的相应方法进行处理。
3) 如果 ZKFailoverController 判断需要进行主备切换,会首先使用 ActiveStandbyElector 来进行自动的主备选举。
4) ActiveStandbyElector 与 Zookeeper 进行交互完成自动的主备选举。
5) ActiveStandbyElector 在主备选举完成后,会回调 ZKFailoverController 的相应方法来通知当前的 NameNode 成为主 NameNode 或备 NameNode。
6) ZKFailoverController 调用对应 NameNode 的 HAServiceProtocol RPC 接口的方法将 NameNode 转换为 Active 状态或 Standby 状态。
脑裂问题
当网络抖动时,ZKFC检测不到Active NameNode,此时认为NameNode挂掉了,因此将Standby NameNode切换成Active NameNode,而旧的Active NameNode由于网络抖动,接收不到zkfc的切换命令,此时两个NameNode都是Active状态,这就是脑裂问题。那么HDFS HA中如何防止脑裂问题的呢?
HDFS集群初始启动时,Namenode的主备选举是通过 ActiveStandbyElector 来完成的,ActiveStandbyElector 主要是利用了 Zookeeper 的写一致性和临时节点机制,具体的主备选举实现如下:
**1. 创建锁节点**
如果 HealthMonitor 检测到对应的 NameNode 的状态正常,那么表示这个 NameNode 有资格参加 Zookeeper 的主备选举。如果目前还没有进行过主备选举的话,那么相应的 ActiveStandbyElector 就会发起一次主备选举,尝试在 Zookeeper 上创建一个路径为/hadoop-ha/\${dfs.nameservices}/ActiveStandbyElectorLock 的临时节点 (\${dfs.nameservices} 为 Hadoop 的配置参数 dfs.nameservices 的值,下同),Zookeeper 的写一致性会保证最终只会有一个 ActiveStandbyElector 创建成功,那么创建成功的 ActiveStandbyElector 对应的 NameNode 就会成为主 NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Active 状态。而创建失败的 ActiveStandbyElector 对应的NameNode成为备用NameNode,ActiveStandbyElector 会回调 ZKFailoverController 的方法进一步将对应的 NameNode 切换为 Standby 状态。
**2. 注册 Watcher 监听**
不管创建/hadoop-ha/\${dfs.nameservices}/ActiveStandbyElectorLock
![【BUG】已解决:OSError: [Errno 22] Invalid argument](https://img-blog.csdnimg.cn/direct/df413fc3bbea46f7962bc7fe31fa6a01.png)