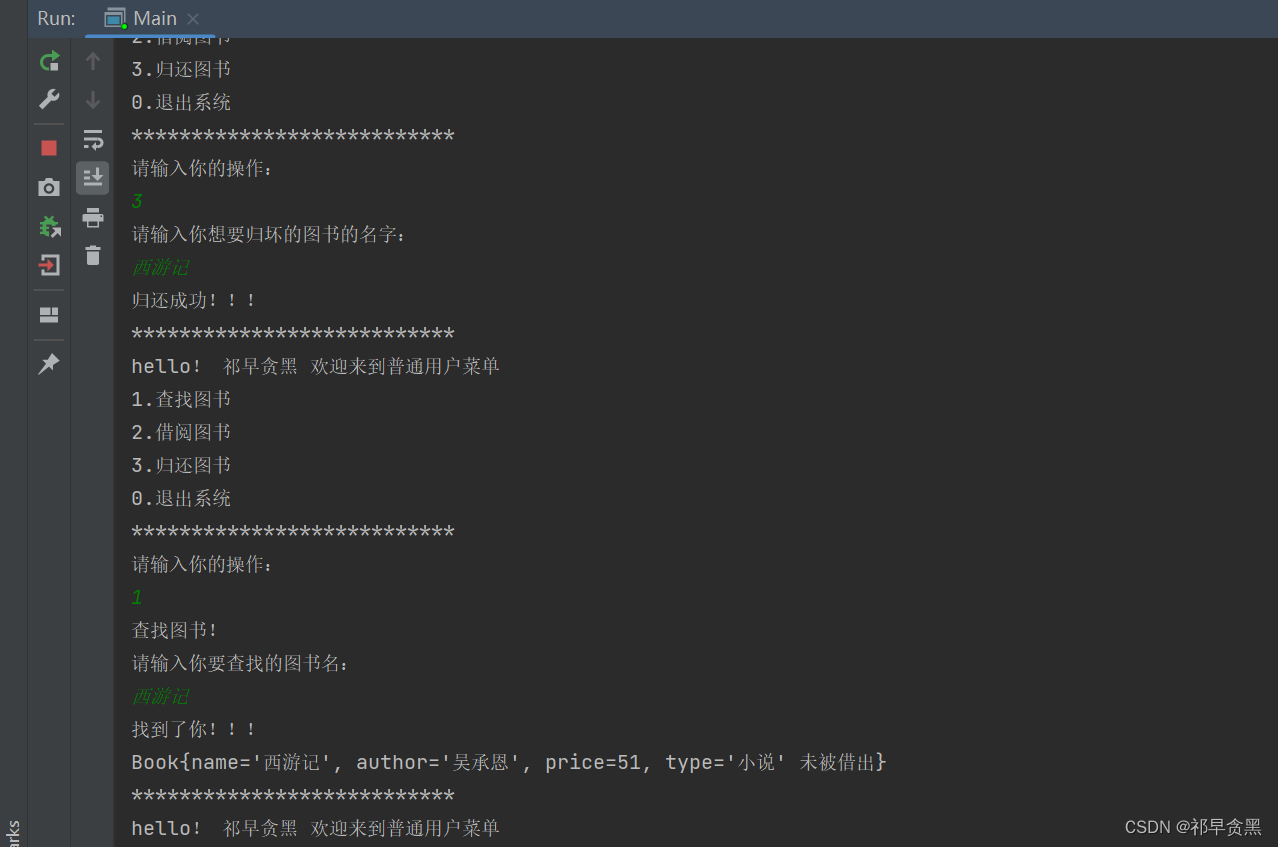
一、文章简介
Wide & Deep Learning for Recommender Systems这篇文章介绍了一种结合宽线性模型和深度神经网络的方法,以实现推荐系统中的记忆和泛化。这种方法在Google Play商店的应用推荐系统中进行了评估,展示了其显著的性能提升。
推荐系统中的记忆和泛化
为了实现记忆和泛化,Wide & Deep模型结合了宽线性模型和深度神经网络:
1.宽组件(Wide Component)
宽组件的主要功能是实现记忆,即捕捉特征之间的频繁共现关系。这部分模型采用线性模型,利用交叉乘积特征来捕捉特征之间的高阶关系。
1). 原始输入特征和交叉乘积特征
- 原始输入特征:这些是从用户和上下文数据中提取的直接特征。例如,用户的安装应用、语言、年龄等。
- 交叉乘积特征:通过交叉乘积转换生成的新特征,这些特征通过组合原始特征来捕捉特征间的交互。例如,“AND(gender=female, language=en)”表示女性用户使用英语。
2). 公式
宽组件的线性组合公式:
其中:
是原始输入特征向量。
-
是交叉乘积特征向量。
是宽组件的权重向量。
3). 记忆功能
宽组件通过权重向量 学习特征间的共现关系。例如,如果某用户安装了Netflix且展示了Pandora,则特征“AND(user_installed_app=netflix, impression_app=pandora)”的值为1,模型可以利用这个信息来进行记忆。
2.深组件(Deep Component):
深组件的主要功能是实现泛化,即学习特征之间的潜在关系,处理未见过的新特征组合。深组件通过深度神经网络来实现,能够更好地捕捉复杂的非线性关系。
1).嵌入层
类别特征嵌入:将高维稀疏的类别特征转化为低维稠密的嵌入向量。每个类别特征(如“language=en”)被映射到一个32维的嵌入向量。公式:
其中, 是嵌入向量,
是类别特征。
2).隐藏层
- 连接嵌入和稠密特征:将所有嵌入向量和稠密特征连接在一起,形成一个约1200维的稠密向量。
- 多层感知器:通过多层感知器(MLP)进行处理,通常包括3个ReLU层,每层执行非线性变换,捕捉复杂的特征关系
其中:
是第
层的激活值。
是第
是第
是激活函数,通常为
。
3).泛化功能
深组件通过嵌入层和多层感知器学习特征之间的非线性关系,能够处理以前未见过的新特征组合。例如,通过学习用户的行为模式和上下文信息,模型可以生成新的推荐。
3).实例代码
import tensorflow as tf
# 创建一个简单的模型,包括一个嵌入层、一个隐藏层和一个输出层
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=4, output_dim=32, input_length=1),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'), # 隐藏层
tf.keras.layers.Dense(1) # 输出层
])
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 打印嵌入层的权重(训练前)
print("嵌入层权重(训练前):")
print(model.layers[0].get_weights()[0])
# 创建简单的数据
import numpy as np
x_train = np.array([[0], [1], [2], [3]])
y_train = np.array([1.0, 2.0, 3.0, 4.0])
# 训练模型
model.fit(x_train, y_train, epochs=100, verbose=0)
# 打印嵌入层的权重(训练后)
print("嵌入层权重(训练后):")
print(model.layers[0].get_weights()[0])
3.结合记忆和泛化
宽组件和深组件的输出通过加权和进行组合,作为最终的预测结果。在训练过程中,这两部分是同时优化的,使得模型能够平衡记忆和泛化的需求。具体过程如下:
1).计算宽组件的输出:
宽组件的输出是原始输入特征和交叉乘积特征的线性组合:
2).计算深组件的输出:
深组件的输出是嵌入层和多层感知器处理后的结果:
其中, 是深度模型最后一层的激活值。
3).组合输出:
宽组件和深组件的输出通过加权和进行组合,作为最终的预测值:
其中, 是sigmoid激活函数,
和
分别是宽组件和深组件的权重向量,
是深组件最后一层的激活值,
是偏置项。
4).损失函数和优化:
使用逻辑损失函数(logistic loss function)进行联合训练,通过反向传播算法同时优化宽组件和深组件的参数:
其中:
是样本的数量。
是第
个样本的实际标签(0 或 1)。
是第
是自然对数。
损失函数的意义
- 当实际标签
起作用,第二项为零。这部分损失鼓励模型将
- 当实际标签
起作用,第一项为零。这部分损失鼓励模型将
通过最小化这个损失函数,模型会在预测时更加准确地反映实际标签。
逻辑损失函数的特性
- 凸性:逻辑损失函数是一个凸函数,这意味着存在全局最优解(证明见下一篇博客)。
- 概率解释:逻辑损失函数直接反映了模型预测概率的准确性,能够有效处理不平衡数据集。
4.结论与意义
- Wide & Deep模型成功结合了记忆和泛化的优势,在推荐系统中表现出色。
- 实际应用中,通过在线实验验证了其有效性和改进。
- 提供了开源实现,为进一步研究和应用提供了基础。


![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 二进制游戏(200分)- 三语言AC题解(Python/Java/Cpp)](https://i-blog.csdnimg.cn/direct/52a38ed47a5d4192b7ea78a65c3fab2f.png)










![[MMU]现代计算机内存管理](https://img-blog.csdnimg.cn/img_convert/41cf0ead30a39b24ebc2aeb59bc948ab.png)