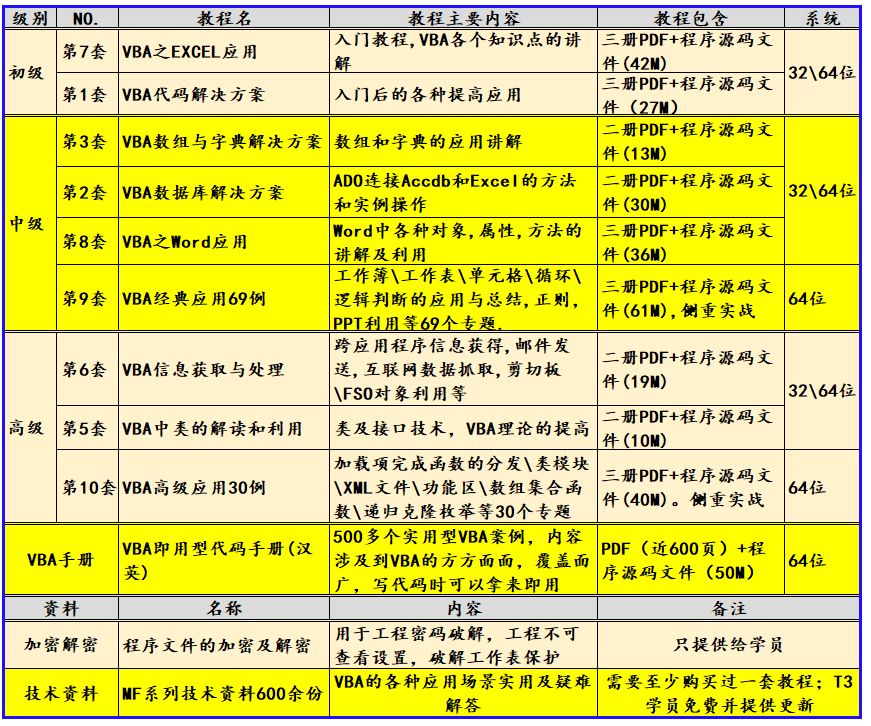
一、定义
1.定义
2. 案例1
3. 全局剪枝案例
4. 全局剪枝案例
5. 自定义剪枝
6. 特定网络剪枝
7. 多参数模块剪枝
8. torch.nn.utils.prune 解读
二、实现
- 定义

- 接口:
import torch.nn.utils.prune as prune
- 案例1
import torch.nn as nn
import torch.nn.utils.prune as prune
import torch
def prune_first_layer(module, inputs):
# 对权重矩阵进行L1剪枝,保留80%的元素
prune.l1_unstructured(module,"weight", amount=0.8)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
def forward(self, x):
x = x.view(-1, 784)
x = self.fc1(x)
x = nn.functional.relu(x)
x = self.fc2(x)
x = nn.functional.relu(x)
x = self.fc3(x)
return x
net = Net()
# 将钩子函数与第一个全连接层关联起来
handle = net.fc1.register_forward_pre_hook(prune_first_layer) #fc1 执行之前进行剪枝
# 进行前向传递
output = net(torch.randn(1, 784))
# 移除钩子函数
handle.remove()
- 全局剪枝案例
import torch
from torch import nn
import torch.nn.utils.prune as prune
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 1: 图像的输入通道(1是黑白图像), 6: 输出通道, 3x3: 卷积核的尺寸
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 是经历卷积操作后的图片尺寸
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = LeNet().to(device=device)
# 首先打印初始化模型的状态字典
print(model.state_dict().keys())
print('*'*50)
# 构建参数集合, 决定哪些层, 哪些参数集合参与剪枝
parameters_to_prune = (
(model.conv1, 'weight'),
(model.conv2, 'weight'),
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight'))
# 调用prune中的全局剪枝函数global_unstructured执行剪枝操作, 此处针对整体模型中的20%参数量进行剪枝
prune.global_unstructured(parameters_to_prune, pruning_method=prune.L1Unstructured, amount=0.2)
# 最后打印剪枝后的模型的状态字典
print(model.state_dict().keys())
print(
"Sparsity in conv1.weight: {:.2f}%".format(
100. * float(torch.sum(model.conv1.weight == 0))
/ float(model.conv1.weight.nelement())
))
print(
"Sparsity in conv2.weight: {:.2f}%".format(
100. * float(torch.sum(model.conv2.weight == 0))
/ float(model.conv2.weight.nelement())
))
print(
"Sparsity in fc1.weight: {:.2f}%".format(
100. * float(torch.sum(model.fc1.weight == 0))
/ float(model.fc1.weight.nelement())
))
print(
"Sparsity in fc2.weight: {:.2f}%".format(
100. * float(torch.sum(model.fc2.weight == 0))
/ float(model.fc2.weight.nelement())
))
print(
"Sparsity in fc3.weight: {:.2f}%".format(
100. * float(torch.sum(model.fc3.weight == 0))
/ float(model.fc3.weight.nelement())
))
print(
"Global sparsity: {:.2f}%".format(
100. * float(torch.sum(model.conv1.weight == 0)
+ torch.sum(model.conv2.weight == 0)
+ torch.sum(model.fc1.weight == 0)
+ torch.sum(model.fc2.weight == 0)
+ torch.sum(model.fc3.weight == 0))
/ float(model.conv1.weight.nelement()
+ model.conv2.weight.nelement()
+ model.fc1.weight.nelement()
+ model.fc2.weight.nelement()
+ model.fc3.weight.nelement())
))
# 当采用全局剪枝策略的时候(假定20%比例参数参与剪枝),
# 仅保证模型总体参数量的20%被剪枝掉,
# 具体到每一层的情况则由模型的具体参数分布情况来定.
import torchfrom torch.nn.utils import prune#
定义模型model = torch.nn.Sequential(
torch.nn.Linear(100, 50),
torch.nn.ReLU(),
torch.nn.Linear(50, 10))
# 剪枝网络结构
prune.random_unstructured(model, amount=0.2)
# 剪枝权重
prune.l1_unstructured(model, amount=0.2)
- 自定义剪枝
#用户自定义剪枝(Custom pruning).
# 剪枝模型通过继承class BasePruningMethod()来执行剪枝,
# 内部有若干方法: call, apply_mask, apply, prune, remove等等.
# 一般来说, 用户只需要实现__init__, 和compute_mask两个函数即可完成自定义的剪枝规则设定.
import time
# 自定义剪枝方法的类, 一定要继承prune.BasePruningMethod
class myself_pruning_method(prune.BasePruningMethod):
PRUNING_TYPE = "unstructured"
# 内部实现compute_mask函数, 完成程序员自己定义的剪枝规则, 本质上就是如何去mask掉权重参数
def compute_mask(self, t, default_mask):
mask = default_mask.clone()
# 此处定义的规则是每隔一个参数就遮掩掉一个, 最终参与剪枝的参数量的50%被mask掉
mask.view(-1)[::2] = 0
return mask
# 自定义剪枝方法的函数, 内部直接调用剪枝类的方法apply
def myself_unstructured_pruning(module, name):
myself_pruning_method.apply(module, name)
return module
# 实例化模型类
model = LeNet().to(device=device)
start = time.time()
# 调用自定义剪枝方法的函数, 对model中的第三个全连接层fc3中的偏置bias执行自定义剪枝
myself_unstructured_pruning(model.fc3, name="bias")
# 剪枝成功的最大标志, 就是拥有了bias_mask参数
print(model.fc3.bias_mask)
# 打印一下自定义剪枝的耗时
duration = time.time() - start
print(duration * 1000, 'ms')
# 打印出来的bias_mask张量, 完全是按照预定义的方式每隔一位遮掩掉一位,
# 0和1交替出现, 后续执行remove操作的时候,
# 原始的bias_orig中的权重就会同样的被每隔一位剪枝掉一位.
- 特定网络剪枝
# 第一种: 对特定网络模块的剪枝(Pruning Model).
import torch
from torch import nn
import torch.nn.utils.prune as prune
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 1: 图像的输入通道(1是黑白图像), 6: 输出通道, 3x3: 卷积核的尺寸
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 是经历卷积操作后的图片尺寸
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
model = LeNet().to(device=device)
# 序列化一个剪枝模型(Serializing a pruned model):
# 对于一个模型来说, 不管是它原始的参数, 拥有的属性值, 还是剪枝的mask buffers参数
# 全部都存储在模型的状态字典中, 即state_dict()中.
# 将模型初始的状态字典打印出来
print(model.state_dict().keys())
print('*'*50)
# 对模型进行剪枝操作, 分别在weight和bias上剪枝
module = model.conv1
prune.random_unstructured(module, name="weight", amount=0.3)
prune.l1_unstructured(module, name="bias", amount=3)
# 再将剪枝后的模型的状态字典打印出来
print(model.state_dict().keys())
# 对模型执行剪枝remove操作.
# 通过module中的参数weight_orig和weight_mask进行剪枝, 本质上属于置零遮掩, 让权重连接失效.
# 具体怎么计算取决于_forward_pre_hooks函数.
# 这个remove是无法undo的, 也就是说一旦执行就是对模型参数的永久改变.
# 打印剪枝后的模型参数
print(list(module.named_parameters()))
print('*'*50)
# 打印剪枝后的模型mask buffers参数
print(list(module.named_buffers()))
print('*'*50)
# 打印剪枝后的模型weight属性值
print(module.weight)
print('*'*50)
# 打印模型的_forward_pre_hooks
print(module._forward_pre_hooks)
print('*'*50)
# 执行剪枝永久化操作remove
prune.remove(module, 'weight')
print('*'*50)
# remove后再次打印模型参数
print(list(module.named_parameters()))
print('*'*50)
# remove后再次打印模型mask buffers参数
print(list(module.named_buffers()))
print('*'*50)
# remove后再次打印模型的_forward_pre_hooks
print(module._forward_pre_hooks)
# 对模型的weight执行remove操作后, 模型参数集合中只剩下bias_orig了,
# weight_orig消失, 变成了weight, 说明针对weight的剪枝已经永久化生效.
# 对于named_buffers张量打印可以看出, 只剩下bias_mask了,
# 因为针对weight做掩码的weight_mask已经生效完毕, 不再需要保留了.
# 同理, 在_forward_pre_hooks中也只剩下针对bias做剪枝的函数了.
- 多参数模块剪枝
import torch
from torch import nn
import torch.nn.utils.prune as prune
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 1: 图像的输入通道(1是黑白图像), 6: 输出通道, 3x3: 卷积核的尺寸
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5x5 是经历卷积操作后的图片尺寸
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, int(x.nelement() / x.shape[0]))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 第二种: 多参数模块的剪枝(Pruning multiple parameters).
model = LeNet().to(device=device)
# 打印初始模型的所有状态字典
print(model.state_dict().keys())
print('*'*50)
# 打印初始模型的mask buffers张量字典名称
print(dict(model.named_buffers()).keys())
print('*'*50)
# 对于模型进行分模块参数的剪枝
for name, module in model.named_modules():
# 对模型中所有的卷积层执行l1_unstructured剪枝操作, 选取20%的参数剪枝
if isinstance(module, torch.nn.Conv2d):
prune.l1_unstructured(module, name="weight", amount=0.2)
# 对模型中所有全连接层执行ln_structured剪枝操作, 选取40%的参数剪枝
elif isinstance(module, torch.nn.Linear):
prune.ln_structured(module, name="weight", amount=0.4, n=2, dim=0)
# 打印多参数模块剪枝后的mask buffers张量字典名称
print(dict(model.named_buffers()).keys())
print('*'*50)
# 打印多参数模块剪枝后模型的所有状态字典名称
print(model.state_dict().keys())
- torch.nn.utils.prune 解读:用于修剪模块参数的实用类和函数。









![Langchain[3]:Langchain架构演进与功能扩展:流式事件处理、事件过滤机制、回调传播策略及装饰器应用](https://img-blog.csdnimg.cn/img_convert/a8a8728efabb841b93b74ddddec2c686.png)