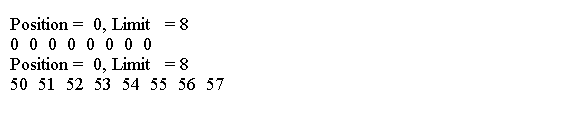1.进行shell命令行
spark-shell

2.创建RDD
2.1 读取文件创建RDD
2.1.1读取linux文件系统的文件创建RDD
--需要保证每一个worker中都有该文件
val data1 = sc.textFile("file:/opt/file/word.txt")

2.1.2读取hdfs文件系统上的文件创建RDD
val data2=sc.textFile("hdfs:/word.txt")
2.2使用Parallelize创建RDD
· val array1=Array(1,2,3,4,5,6)
val data3 = sc.parallelize(array1)
2.3从其他的RDD中创建新的RDD
val data4=data3.map(num =>(num*2))
3.对RDD进行操作
--统计RDD中的数据记录表
data1.count()
--对RDD中的数据进行过滤操作
--过滤数据,保留每行中含有hello的数据
val filterRDD=data1.filter(line => line.contains("hello"))
filterRDD.count()
--读取RDD的第一条数据
filterRDD.first()
--读取中的N条数据
filterRDD.take(2)
4.实现wordcount
val wordcount=data1.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)

将RDD中的数据写到hdfs上
wordcount.saveAsTextFile("hdfs:/out")






![鸿蒙 next 5.0 版本页面跳转传参 接受参数 ,,接受的时候 要先定义接受参数的类型, 代码可以直接CV使用 [教程]](https://i-blog.csdnimg.cn/direct/3aef65364d524a808122309b771cc4a8.png)