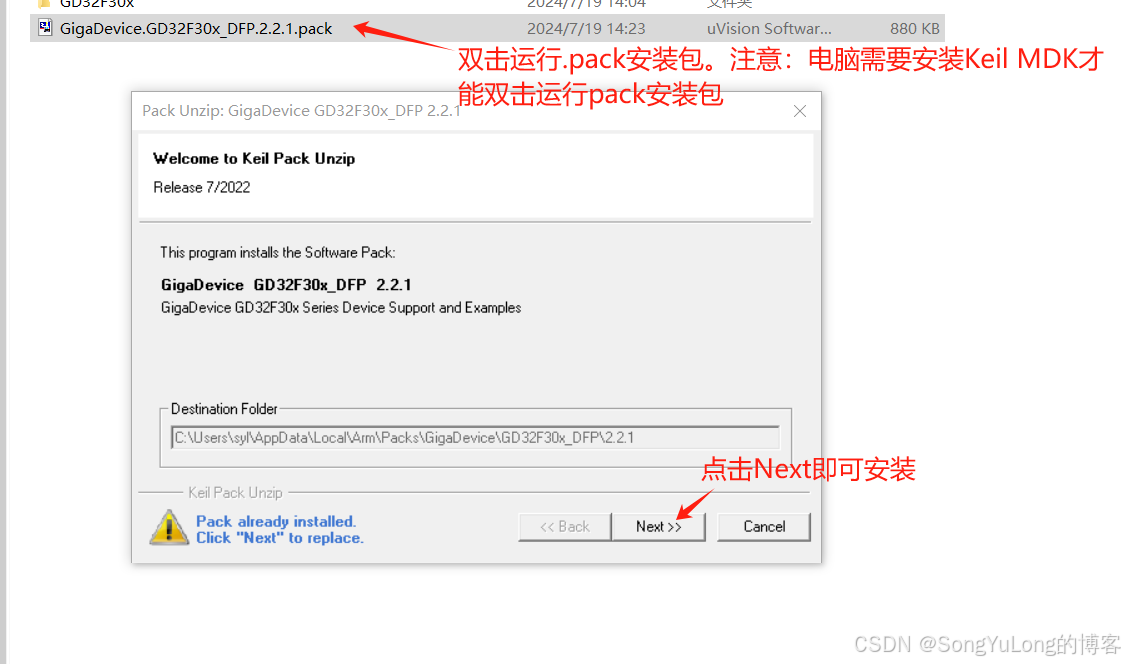
在了解了vector之后,我们只需要简单学习List与vector不一样的接口即可
1.list的基本接口
1.1 iterator
list中,与vector最大的区别就是迭代器由随机迭代器变成双向迭代器
string和vector中的迭代器都是随机迭代器,支持+-等,而LIST的双向迭代器不支持双目运算+ -, 只支持弹幕运算++ --
vector中对于迭代器的解释:
list中对于迭代器的解释:双向带头链表(bidirectional iterator)

双向迭代器不支持+ -的原因:
效率低,毕竟链表无法随机访问 ,自然也无法方括号访问
1.2 sort
由于排序算法的底层是快排,而快排不支持随机迭代器“RandomAccessIterator”

并且双向迭代器不支持迭代器相减,快排中有一些三数取中的操作无法进行,所以不能使用std中的sort,否则在运行时会有运行错误:

因此链表中有自己的sort(底层是归并排序):

升序:

降序(正如演示中的代码,链表的构造函数用法与vector一致):

1.3两个建议先排序再使用的函数:
li.unique();
li.merge(li1);
unique,即去重,将重复的元素去掉。
先排序,再去重,否则去不干净
不排序就去重,在相同元素未连续的情况下是无法起到效果的

先降序:

merge,即合并

因为其原理是用双指针取小的尾差,所以先排序,再合并,就能将两个元素中一样的元素有序合并到一起
2.list中排序的效率问题
C语言数据结构基础——排序-CSDN博客
链表的排序复杂度和vector的排序复杂度都是O(nlogn)
但是vector的效率几乎稳定在list自带sort的2~5倍左右
测试代码:
void effciency_test() {
srand(time(0));//初始化时间种子,避免伪随机数
int N = 100000000;
vector<int> v;
for (int i = 0; i < N; ++i) {
v.push_back(i + rand());
}
list<int> li;
for (int i = 0; i < N; ++i) {
li.push_back(rand() + i);
}
size_t begin1 = clock();
sort(v.begin(), v.end());
size_t end1 = clock();
size_t begin2 = clock();
li.sort();
size_t end2 = clock();
cout << "time of vector : " << end1 - begin1 << endl;
cout << "time of list : " << end2 - begin2 << endl;
}debug版本下,两倍左右:
 realease版本下,五倍左右:
realease版本下,五倍左右:

建议的方法是:先将链表的内容拷贝到一个vector,然后再对vector进行sort
我们拷贝之后再进行测试: 
只有少量数据时,不太在乎效率的时候使用list自带的sort
3.结合splice(剪切函数)


中间的list& x表示会有元素被转出的链表
注意,不是复制,就是把节点转移进去。
观察官网中的例子:

这样操作之后,链表1就是1 10 20 30 2 3 4
链表2就是empty
由于其不存在复制的问题,我们还可以通过splice函数的功能将其自己的元素调换位置

测试函数:
void test_of_splice() {
list<int> li1{ 1,2,3,4,5 };
list<int> li2{ 1,2,3,4,5 };
list<int> li3{ 1,2,3,4,5 };
list<int> li{ 2,5,99,89,68 };
li1.splice(li1.begin(), li);//entire list
//li2.splice(li2.begin(), li, --li.end());//single element
//li3.splice(li3.begin(), li, li.begin(), find(li.begin(), li.end(), 89));//element range
for (auto e : li1) {
cout << e << " ";
}
cout << endl;
for (auto e : li) {
cout << e << " ";
}
cout << endl;
for (auto e : li) {
cout << e << " ";
}
cout << endl;
}由于splice会让被移动的元素离开原链表,所以建议一次一次的测试。