简介
从JDK8开始,增加了一新特性Stream流式操作,Stream中提供了非常多的API供大家使用,灵活的使用这些API,可以非常的方便且优美的实现我们的代码逻辑。
流式操作主要用来处理数据(比如集合),就像泛型也大多用在集合中一样。下面我们主要用例子来介绍下,流的基操。
注:本博客相关代码请参考:Scott 数据 映射 MySQL
最终型
toArray
toArray:将流转换为数组。
示例:
@Test
public void fun5() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi");
Object[] array = list.stream().toArray();
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
结果:

collect
collect:将流转换为指定的类型,比如List转换为Set。
示例:
@Test
public void fun1(){
String[] data = {"zhangsan","lisi","wanger","mazi"};
List<String> list = Arrays.stream(data).collect(Collectors.toList());
System.out.println(list);
Set<String> set = Arrays.stream(data).collect(Collectors.toSet());
System.out.println(set);
}
结果:
reduce
reduce:将元素合并起来,得到一个新值。可以简单理解为将一个数组或集合转换成一个String或integer类型的一个对象,最终结果为一个新值。
语法:reduce(a,(b,c)->{b+c})
- a:规约初始值
- b:阶段性的累加结果
- c:当前遍历的元素
注:若是整数类型求和 (Integer),b和c 可换成方法引用 Integer::sum
示例:
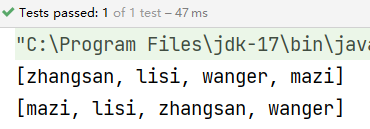
@Test
public void fun4() {
String[] data = {"zhangsan", "lisi", "wanger", "mazi"};
String reduce1 = Arrays.stream(data).reduce("", (v1, v2) -> v1 + v2);
System.out.println(reduce1);
Integer reduce2 = depts.stream().map(Dept::getDeptno).reduce(0, Integer::sum);
System.out.println(reduce2);
}
结果:
iterator
iterator:将流转换为一个迭代器。
示例:
@Test
public void fun6() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi");
Iterator<String> iterator = list.stream().iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
结果:

foreach
foreach:对流中的元素逐个遍历。
示例:
@Test
public void fun7() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi");
list.stream().forEach(System.out::println);
}
结果:

anyMatch/allMatch/noneMatch
- anyMatch:用于判断是否有符合匹配条件的元素。
- allMatch:用于判断是否所有元素都符合匹配条件。
- noneMatch:用于判断是否所有元素都不符合匹配条件。
示例:
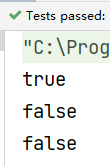
@Test
public void fun8() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi");
boolean b1 = list.stream().anyMatch(item -> item.contains("g"));
System.out.println(b1);
boolean b2 = list.stream().allMatch(item -> item.contains("g"));
System.out.println(b2);
boolean b3 = list.stream().noneMatch(item -> item.contains("g"));
System.out.println(b3);
}
结果:
findFirst/findAny
- findFirst:找到第一个匹配的元素后立即返回。
- findAny:找到任何一个匹配的元素就返回。如果用在一个串行流中,跟findFirst效果一样。如果用在并行流中,就会比较高效。
示例:
@Test
public void fun9() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi");
Optional<String> first = list.stream().findFirst();
System.out.println(first.get());
Optional<String> any = list.stream().findAny();
System.out.println(any.get());
int asInt = IntStream.range(10, 99).parallel().findAny().getAsInt();//并行
System.out.println(asInt);
}
结果:

max/min
- max:匹配元素最大值并返回。
- min:匹配元素最小值并返回。
示例:
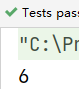
@Test
public void fun10() {
int[] data = {88,23,45,92,18,46,78};
OptionalInt max = Arrays.stream(data).max();
System.out.println(max.getAsInt());
OptionalInt min = Arrays.stream(data).min();
System.out.println(min.getAsInt());
}
结果:

count
count:统计元素的个数,不会自动去重。
示例:
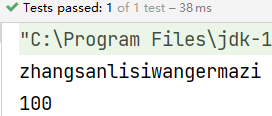
@Test
public void fun11() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi", "lisi", "qianwu");
long count = list.stream().count();
System.out.println(count);
}
结果:
中间型
filter
filter:按照指定的条件匹配出符合要求的元素,并返回一个新的stream流。
示例:
@Test
public void fun12() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi");
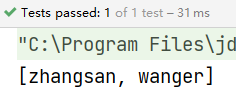
List<String> res = list.stream().filter(item -> item.length() > 4)
.collect(Collectors.toList());
System.out.println(res);
}
结果:
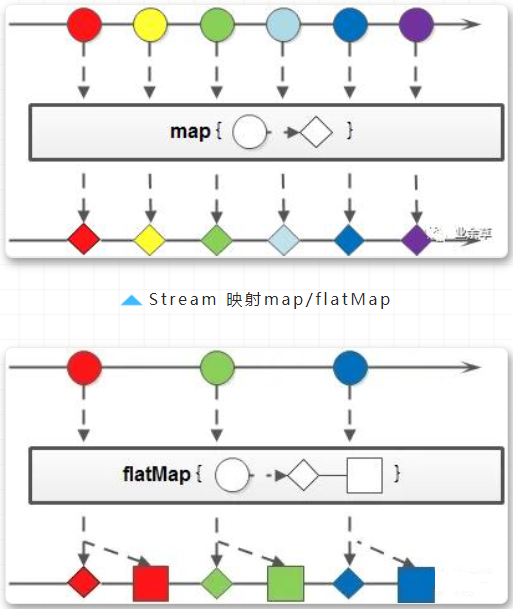
map
map:将一个对象转换为另一个对象,并返回一个新的stream流。比如,可以把数组中的元素从一种类型转换成另一种类型,也可以将多类型的集合变成单纯的只有一种类型的集合。
示例:
@Test
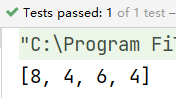
public void fun3(){
String[] data = {"zhangsan","lisi","wanger","mazi"};
List<Integer> list = Arrays.stream(data).map(String::length).collect(Collectors.toList());
System.out.println(list);
}
结果:
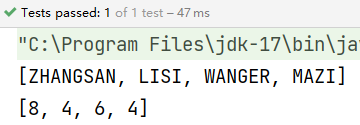
示例:
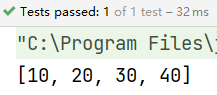
@Test
public void fun4() {
List<Integer> list = depts.stream().map(Dept::getDeptno).collect(Collectors.toList());
System.out.println(list);
}
结果:
flatMap
flatMap:将已有的对象转换为另一个对象,它是一个一对多的逻辑。简单来说就是将多个stream流合并成一个stream。
flatMap与map的区别在于:
- map是一对一的,即将一个对象转换为另一个对象
- flatMap是一对多的,即将一个对象拆分对多个对象
示例:
@Test
public void fun17() {
List<Dept> dept1 = new ArrayList<>();
dept1.add(new Dept(10, "ACCOUNTING", "NEWYORK"));
dept1.add(new Dept(20, "RESEARCH", "DALLAS"));
List<Dept> dept2 = new ArrayList<>();
dept2.add(new Dept(30, "SALES", "CHICAGO"));
dept2.add(new Dept(40, "OPERATIONS", "BOSTON"));
//map 一对一 映射处理
dept1.stream()
.map(dept -> {
Dept build = dept.builder()
.deptno(dept.getDeptno() * 2)
.dname(dept.getDname().toLowerCase())
.loc(dept.getLoc().toLowerCase())
.build();
return build;
}).toList()
.forEach(System.out::println);
List<List<Dept>> depts = new ArrayList<>();
depts.add(dept1);
depts.add(dept2);
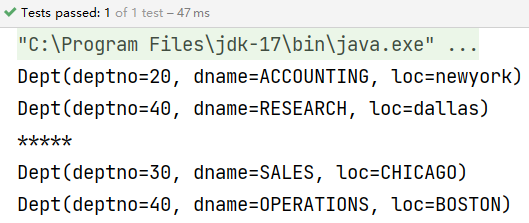
//flatMap 一对多映射处理,深入到多个stream内部去处理子元素,统一输出
depts.stream().flatMap(item -> item.stream()
.filter(dept -> dept.getDeptno() > 20))
.toList()
.forEach(System.out::println);
}
结果:
map和flatMap都可以将一个流的元素按照一定的映射规则映射到另一个流中:
- map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
- flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
示例:
@Test
public void fun16() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi");
//接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
List<String> res1 = list.stream().map(String::toUpperCase).toList();
System.out.println(res1);
//接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
List<String> collect = list.stream().flatMap(item -> {
String[] split = item.split("");
Stream<String> stream = Arrays.stream(split);
return stream;
}).collect(Collectors.toList());
System.out.println(collect);
}
结果:
peek
peek:对流中的元素逐个遍历处理,它与map的区别在于:map一般用于对象的转换,peek用于对象的消费,即不改变元素本身的类型。
示例:
@Test
public void fun13() {
List<Integer> list2 = Arrays.asList(1,2,3,4);
list2.stream()
.peek(x -> System.out.println("stream: " + x)) //peek是对元素逐一消费
.map(x -> x * 2) //map是对元素进行转换
.peek(x -> System.out.println("map: " + x))
.collect(Collectors.toList());
}
结果:

示例:
@Test
public void fun14() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi");
// 使用peek操作流,流中的元素没有改变。
list.stream().peek(String::toUpperCase).forEach(System.out::println);
// 使用map操作流,流中的元素有改变。
list.stream().map(String::toUpperCase).forEach(System.out::println);
}
结果:

limit/skip
- limit:就相当于sql中的limit,可以指定保留前N的元素。
- skip:作用与limit相反,会抛弃前N的元素。
示例:
@Test
public void fun18() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi","qianwu","zhaoliu");
list.stream().limit(3).toList().forEach(System.out::println);
list.stream().skip(2).toList().forEach(System.out::println);
}
结果:

sorted
sorted:用于对流中的数据排序
示例:
@Test
public void fun22() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi");
list.stream()
.sorted(Comparator.comparingInt(String::length))
.toList()
.forEach(System.out::println);
}
结果:
concat
concat:可以将多个流的数据合并为一个流。
示例:
@Test
public void fun20() {
List<String> list1 = List.of("zhangsan", "lisi", "wanger");
List<String> list2 = List.of("mazi","qianwu","zhaoliu");
Stream.concat(list1.stream(),list2.stream())
.toList()
.forEach(System.out::println);
}
结果:

distinct
distinct:用于对流中的元素去重。
示例:
@Test
public void fun21() {
List<String> list = List.of("zhangsan", "lisi", "wanger", "mazi","lisi","mazi");
list.stream().distinct().toList().forEach(System.out::println);
}
结果: