最近一直在研究 AI Agent 在零代码平台中的应用, 特地研究并总结了一份AI学习的干货, 方便大家快速理解LLM, 并熟悉主流的AI大模型框架, 以及如何基于AI, 来改善我们传统的工作模式.
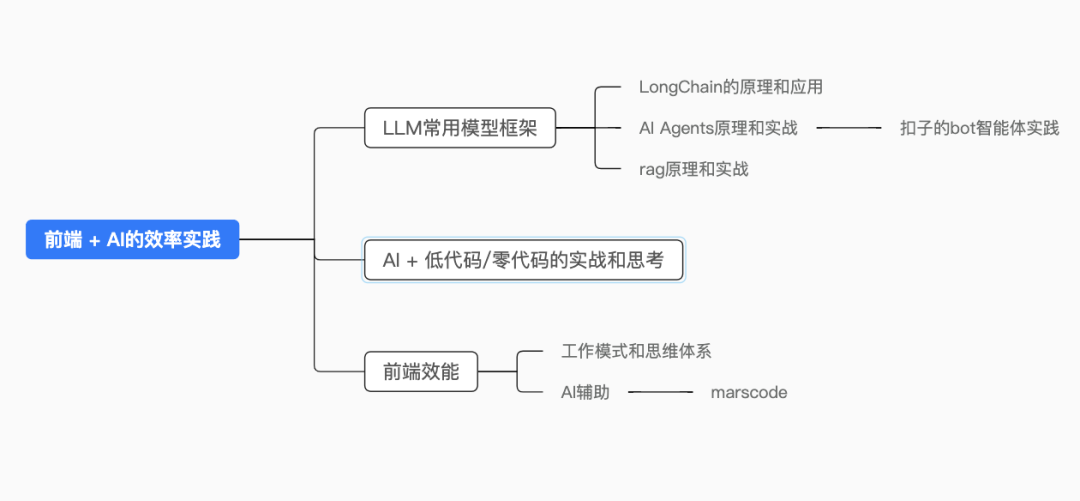
上面是本文的核心大纲, 接下来开始我的分享和总结.
LLM介绍
1. LLM概念
大语言模型(Large Language Model) :通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
2. 大模型分类
按照输入数据类型的不同,大模型主要可以分为以下三大类:
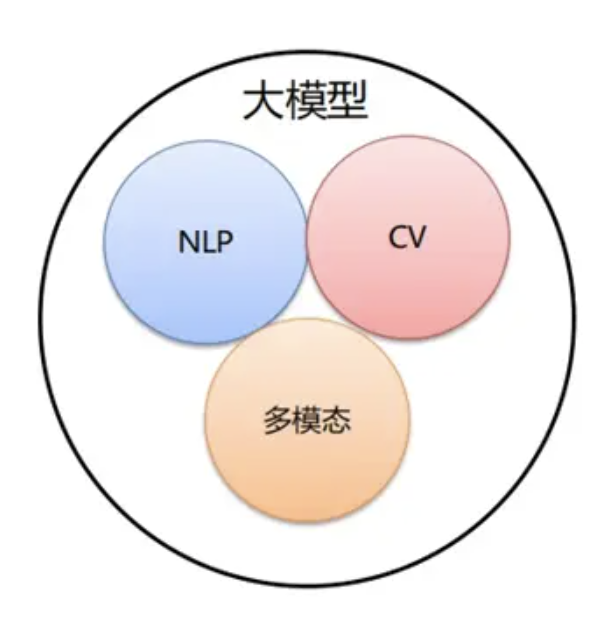
语言大模型(NLP): 是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。例如:GPT 系列(OpenAI).
视觉大模型(CV): 是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务, 比如图像分类, 人脸识别, 目标检测.
多模态大模型: 是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。例如:DingoDB 多模向量数据库(九章云极 DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney。
3.大语言模型的工作机制
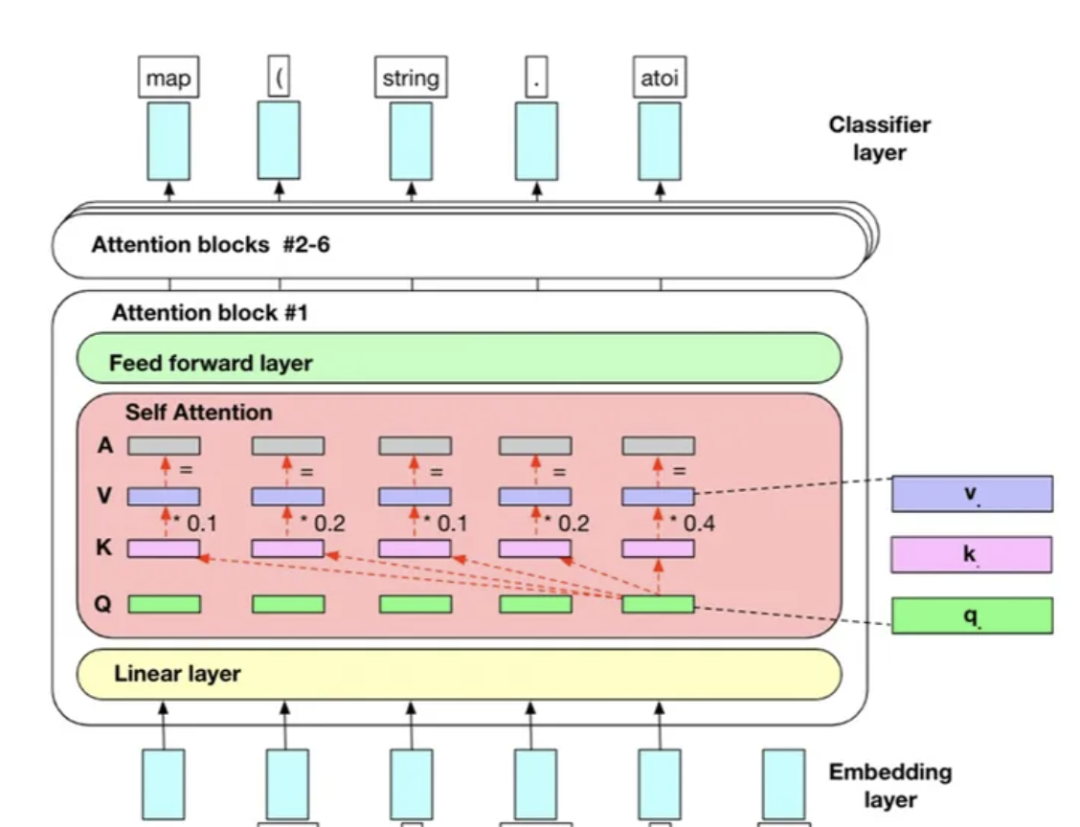
最知名的大型语言模型(LLM)架构基本都是Transformer架构。典型的Transformer模型在处理输入数据时有四个主要步骤:
1. 词嵌入: 模型进行词嵌入,将单词转换为高维向量表示。然后,数据通过多个Transformer层进行传递。这有助于模型理解单词的含义,并基于此进行预测。
2.位置编码(Positional Encoding): 位置编码是帮助模型确定单词在序列中的位置的技术。位置编码主要用于跟踪单词的顺序。例如,当将句子”我喜欢猫”输入到模型时,位置编码可以帮助模型区分”我”是在句子的开头,而”猫”是在句子的结尾。这对于模型理解上下文和生成连贯的输出非常重要。
3.自注意力机制(Self-Attention Mechanism) : 自注意力机制是Transformer模型的核心组成部分。它允许模型在生成输出时,有效地在输入序列的不同位置进行交互和关注。自注意力机制的关键思想是计算输入序列中每个单词之间的相关性,并将这些相关性用于权衡模型在每个位置的关注程度。
4. 前馈神经网络(Feed-forward Neural Network): 前馈神经网络对每个位置的表示进行进一步的处理。前馈神经网络是由多个全连接层组成的,其中每个层都有一组参数,用于将输入进行非线性变换。这个过程可以帮助模型在生成输出时引入更多的复杂性和灵活性。
二.LangChain原理和应用案例
Langchain 是一个开源框架,它允许开发人员将类似 GPT-4 这样的大型语言模型与外部的计算和数据源结合起来, 用于提升大型语言模型(LLMs)的功能。
它提供了 Python 和 TypeScript的软件包。
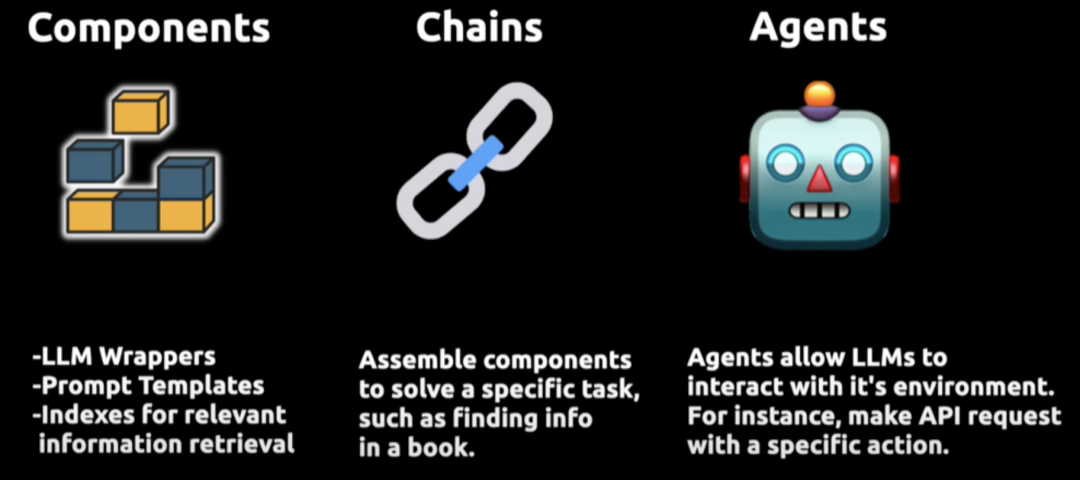
Langchain 通过三个核心组件实现增强:
-
Compents“组件”: 为LLMs提供接口封装、模板提示和信息检索索引;
-
Chains“链”: 它将不同的组件组合起来解决特定的任务,比如在大量文本中查找信息;
-
Agents“代理”: 它们使得LLMs能够与外部环境进行交互,例如通过
Langchain 的这种结构设计使LLMs不仅能够处理文本,还能够在更广泛的应用环境中进行操作和响应,大大扩展了它们的应用范围和有效性。
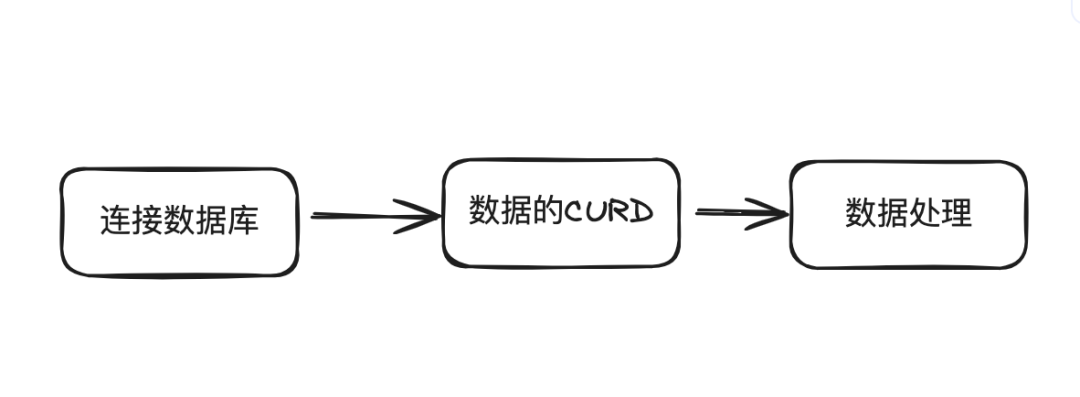
有点类似java的JDBC, 为 Java 开发人员提供了一种统一的方式来访问不同数据库,使得在不同数据库之间切换更加方便。
1.LangChain的工作流程
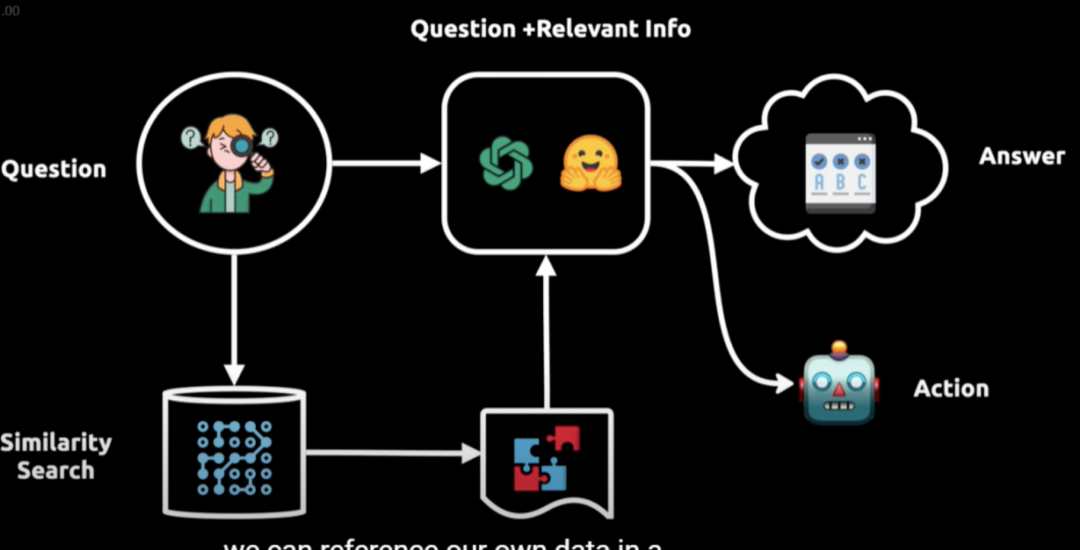
-
提问:用户提出问题;
-
向语言模型查询:问题被转换成向量表示,用于在向量数据库中进行相似性搜索;
-
获取相关信息:从向量数据库中提取相关信息块;
-
输入给语言模型:将相关信息输入给语言模型;
-
生成答案或执行操作:语言模型结合初始问题和相关信息,提供答案或执行相应操作。
2. 应用场景
LangChain 的应用场景十分广泛,以下是一些常见的应用场景和案例:
-
文本总结:可以对长篇文章、书籍、报告等文本进行总结,提取关键信息,例如对新闻文章进行摘要,帮助读者快速了解主要内容。
-
文档问答:基于文档内容进行问答,例如针对产品手册、技术文档等,用户提出问题,系统根据文档中的信息给出准确回答。
-
信息抽取:从大量文本中抽取结构化的信息,如从简历中提取姓名、联系方式、工作经历等关键内容。
-
聊天机器人:构建具备记忆能力的聊天机器人,能够与用户进行多轮对话,并记住之前的对话内容,提供更个性化的服务。例如在线客服机器人,能够理解用户的问题并提供解决方案。
-
智能问答系统:应用于智能客服、智能助手等,回答各种问题,提供相关的知识和信息。
-
代码理解与分析:分析代码,并从代码中获取逻辑,同时也支持代码相关的问答。
-
语言翻译:虽然 LangChain 本身不直接进行语言翻译,但可以与其他翻译工具或模型结合,实现翻译功能。
-
数据库交互:从数据库或类数据库内容中抽取数据信息,实现对数据库的查询和操作。
-
内容生成:生成文章、故事、诗歌等各种文本内容。
-
API 交互:通过对 API 文档的阅读和理解,向真实世界的 API 发送请求并获取数据,例如调用天气预报 API 来获取天气信息并回答用户的相关问题。
三. AI Agents 原理和应用案例
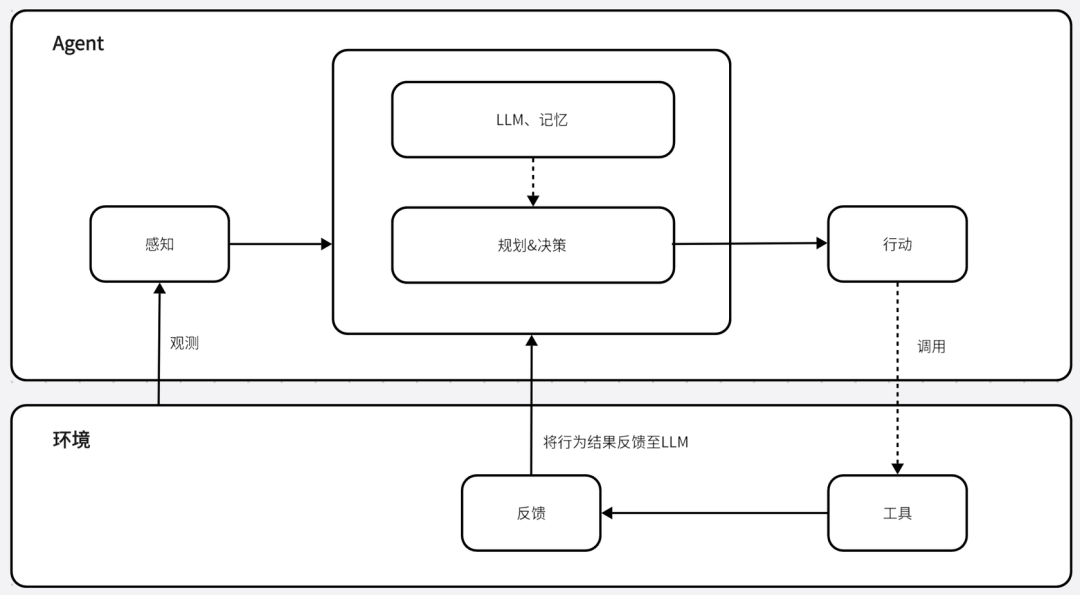
AI Agents(人工智能代理)的原理是通过感知环境、进行决策和执行动作来实现特定目标。它通常包含规划、记忆、工具和行动等关键模块,其工作流程大致如下:
-
目标初始化:为 AI Agents 设定清晰的目标,它们利用核心语言模型(如 GPT-3.5 或 GPT-4)来理解这些目标,并启动相应的行动计划;
-
任务列表创建:根据设定的目标生成一系列任务,确定任务的优先级、规划执行顺序,并为可能的意外情况做好准备;
-
信息收集:收集相关信息,这可能包括搜索互联网、访问数据库或与其他 AI 模型交互等,以执行特定任务;
-
数据管理和策略细化:不断管理和分析收集到的数据,根据数据和目标调整策略;
-
执行任务:基于规划和记忆来执行具体的行动,这可能包括与外部世界互动,或通过工具的调用来完成一个动作;
-
学习和优化:从每次交互和任务执行中学习,不断优化自身的性能和策略,以更好地适应新情况和实现目标。
大白话来说就是一种能自主实现目标的“个体”. 类似如下流程:
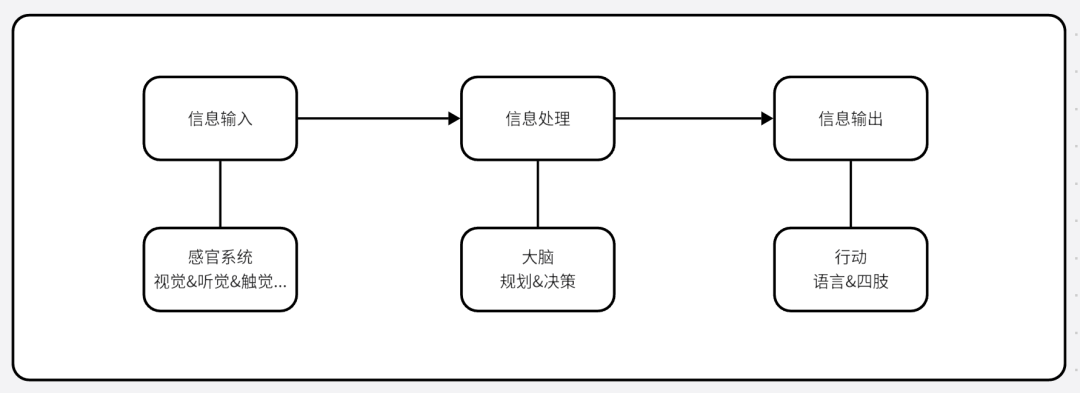
我们将场景抽象成模型, 大致长下面这个样子:
1. 开发一个AI Agent的步骤
-
确定目标和功能:明确你希望 AI Agent 实现的具体目标和具备的功能。
-
选择合适的技术和框架:根据需求选择适合的人工智能技术,如深度学习框架等。
-
数据收集和准备:收集和整理与目标相关的数据,进行清洗和预处理。
-
模型训练:使用收集的数据训练模型,调整参数以优化性能。
-
模型评估和优化:对训练好的模型进行评估,根据结果进行优化和改进。
-
集成和部署:将模型与相关系统集成,并进行部署和测试。
使用通义千问实现AI Agent的案例:
要使用通义千问实现一个 AI Agent,我们可以参考下面的步骤:
-
安装所需的库:使用 pip 安装qwen-agent命令为pip install -u qwen-agent
-
准备模型服务:你可以选择使用阿里云的 Dashscope 提供的模型服务,或者自行部署和使用开源的通义千问模型服务。如果使用 Dashscope,需确保设置了环境变量
-
开发自己的 agent:以下是一个简单的示例,创建一个能够读取 PDF 文件和利用工具的代理。
首先,添加一个自定义工具,例如图片生成工具:
import urllib.parse
import json5
from qwen_agent.tools.base import basetool, register_tool
@register_tool('my_image_gen')
class myimagegen(basetool):
description = 'aipainting(image generation) service, input text description, and return the image url drawn based on text information.'
parameters = ({
'name': 'prompt',
'type':'string',
'description': 'detailed description of the desired image content, in english',
'equired': True
})
def call(self, params: str, **kwargs) -> str:
prompt = json5.loads(params)('prompt')
prompt = urllib.parse.quote(prompt)
return json5.dumps(
{'image_url': f'https://image.pollinations.ai/prompt/{prompt}'},
ensure_ascii=False)
然后,配置使用的 LLM 模型:
llm_cfg = {
'odel': 'qwen-max',
'odel_server': 'dashscope',
#'api_key': 'your_dashscope_api_key', # 可根据实际情况设置或使用环境变量
# 可选的生成配置,用于调整生成参数
'generate_cfg': {
'top_p': 0.8
}
}
接下来,创建 agent:
from qwen_agent.agents import assistant
system_instruction = '''you are a helpful assistant.
after receiving the user's request, you should:
-first draw an image and obtain the image url,
-then run code `request.get(image_url)` to download the image,
-and finally select an image operation from the given document to process the image.
please show the image using `plt.show()`.'''
tools = ('my_image_gen', ) # 这里添加你需要的工具
agent = assistant(system_instruction=system_instruction, tools=tools, llm_cfg=llm_cfg)
最后,我们可以以聊天机器人的形式运行这个助理,与它进行交互并执行相关任务。请注意,这只是一个基本的示例,实际开发中可能需要根据具体需求进一步扩展和定制 agent 的功能,包括添加更多工具、处理不同类型的任务、优化交互方式等。
四.Rag原理和应用案例
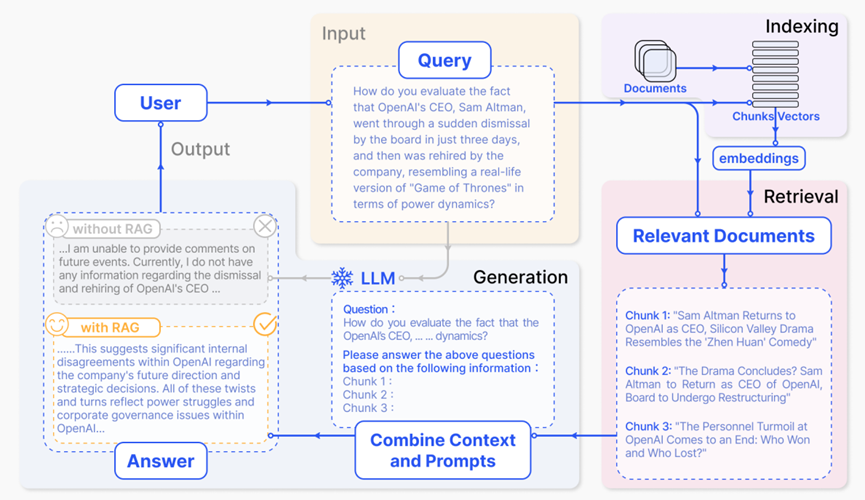
为什么要用RAG技术?
RAG(检索增强生成)主要解决了大语言模型(LLM)的以下几个问题:
-
幻觉问题:LLM 因为是预训练模型,当用户提出的问题与其知识储备不相符时,可能会产生看似正确实则错误的回答,即出现“幻觉”。RAG 通过从外部知识库中检索相关信息,为 LLM 提供更准确的依据,从而减少幻觉的产生。
-
数据新鲜度问题:LLM 预训练完成后,不能感知实时更新的数据。RAG 可以将实时更新的公域数据或企业内部私域数据进行处理后,提供给 LLM,使其能够生成基于最新信息的回答。
-
知识局限性问题:LLM 可能在某些小众领域的知识不足。RAG 能通过向量匹配,帮助找到与提问最相关的段落或文章,补充 LLM 缺乏的知识。
-
隐私保护问题:企业可能出于安全考虑,不想让 LLM 训练自家的敏感数据或机密文档。RAG 可以在不暴露敏感数据的情况下,从知识库中检索相关信息,为 LLM 提供回答所需的内容。
RAG是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(用于搜索大型数据集或知识库)和生成模型(如大型语言模型 LLM)结合在一起,通过从更多数据源添加背景信息,以及通过训练来补充 LLM 的原始知识库,从而提高搜索体验的相关性,改善大型语言模型的输出,且无需重新训练模型。
RAG 的工作原理如下:
-
检索:将用户的查询通过嵌入模型转化为向量,与向量数据库中的其他上下文信息进行比对,通过相似性搜索找到向量数据库中最匹配的前 k 个数据。
-
增强:将用户的查询和检索到的额外信息一起嵌入到预设的提示模板中,提供更丰富、更具上下文的信息,以便于后续的生成过程。
-
生成:将经过检索增强的提示内容输入到大型语言模型(LLM)中,生成所需的输出。
举一个RAG 的一个应用案例:假设要构建一个智能客服系统,能够回答关于产品的各种问题。首先,收集产品相关的文档、常见问题解答等数据,并将这些数据进行处理和向量化后存入向量数据库。当用户提出问题时,系统通过检索模块在向量数据库中查找相关信息,然后将查询和检索到的信息一起输入到提示模板中进行增强。最后,利用大型语言模型根据增强后的提示生成准确且符合语境的回答。
例如,用户询问“某产品的最新功能有哪些”,RAG 系统会从数据库中检索到该产品的最新信息,将其与问题一起提供给 LLM,使得 LLM 生成的回答包含最新的、准确的产品功能描述,而不仅仅依赖于其预先训练的知识。
完整的RAG工作流程分为两个阶段:

RAG 的优点包括提高答案准确性、减少幻觉、能够识别最新信息以保持回答的及时性和准确性、高度透明从而增强用户对输出结果的信任、可定制化以支持不同领域的专业知识,以及在安全性和隐私管理方面有较好的控制、处理大规模数据集时具有更好的扩展性和经济效率、提供更值得信赖的结果等。
然而,RAG 系统在实际应用中也面临一些挑战,例如检索质量方面可能存在精度问题( 检索结果不完全相关)、低召回率问题(未能检索到所有相关文档块)、过时信息问题;回应生成质量方面可能出现错误信息、回答不相关性、有害或偏见性回应等;在增强过程中面临上下文融合、处理冗余和重复、评估文段价值、保持输出一致性、避免过度依赖增强信息等问题。
为了解决这些挑战,可能需要优化检索算法、提升嵌入模型的性能、精心设计提示模板、进行数据清洗和更新、引入人工审核或反馈机制等措施。同时,根据具体的应用场景和需求,选择合适的检索模型、LLM、向量数据库等组件,并不断调整和改进系统的参数和配置,以提高 RAG 系统的性能和效果。
推荐2个相对成熟的Rag方案:
-
GraphRAG:微软开源的一种基于图的检索增强生成方法。它利用大型语言模型构建知识图谱,将图谱聚类成不同粒度级别的相关实体社区。在进行 RAG 操作时,遍历所有社区以创建“社区答案”,并进行缩减得到最终答案。该方法在处理私有数据时性能较好,具备跨大型数据集的复杂语义问题推理能力。其开源地址为:https://github.com/microsoft/graphrag
-
HyKGE:这是知识图谱与检索增强生成技术结合的一种方案。通过利用大型语言模型的深度语义理解与知识生成能力,结合知识图谱丰富的结构化信息,能够提高医学信息检索的效率,并确保回答的精确度。该框架利用大型语言模型生成假设性回答以增强图谱检索,采用 HO 片段重排名机制过滤噪声知识,包含假设输出模块、命名实体识别模块、知识图谱检索模块和 HO 片段粒度感知重排模块等组件。
五. AI + 低代码/零代码的思考
目前主要能落地的几个方向主要有:
-
素材生成(AIGC), 比如图文,音视频
-
页面生成(基于训练的Schema, 批量生成Schema, 进而实现批量页面模版生成)
-
业务流程生成
-
接口 / 数据库表自动创建
-
应用创建
后续我也会出几个实践案例, 和大家分享一下如何让AI赋能零代码.
六. 前端效能
1.下一代工作模式和研发思维方式
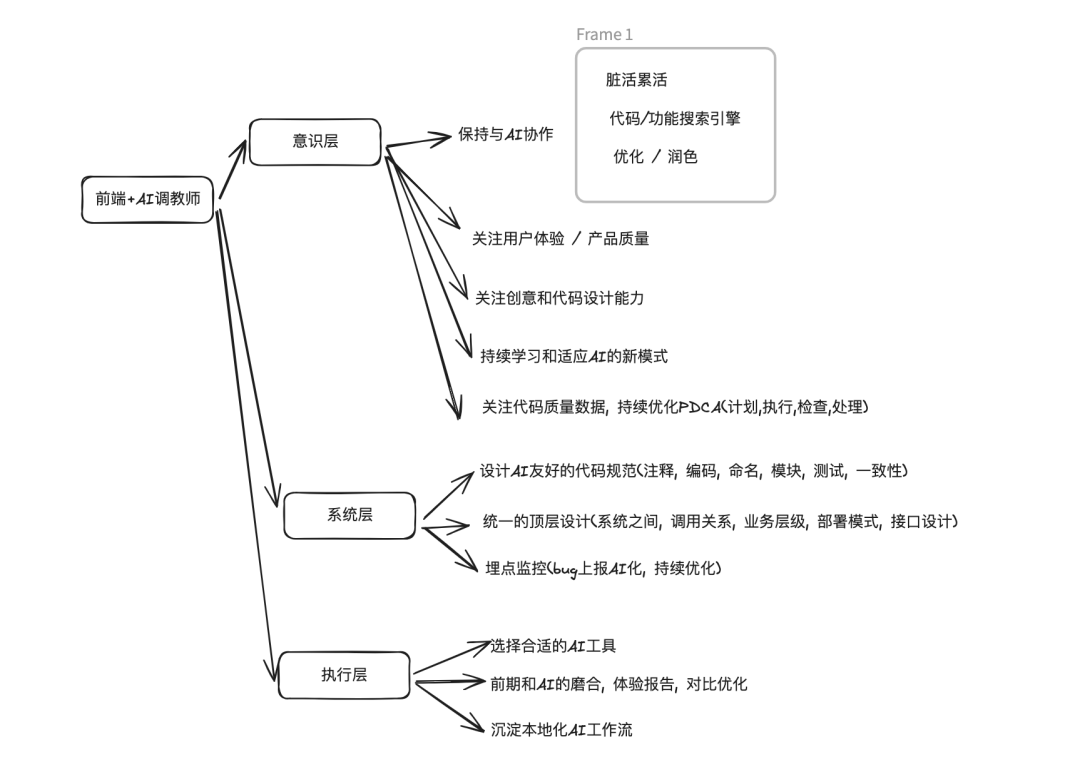
上面是我总结的一些和AI共存的思考, 大家可以参考一下.
2.AI辅助工具Marscode 和 知识库创作工具Nocode/WEP
或者使用我自研的下一代AI文档知识库工具Nocode/WEP, 来轻松帮大家搭建AI知识库:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
文章知识点与官方知识档案匹配,可进一步学习相关知识