自Oracle发布MySQL9.0以来,貌似对MySQL的吐槽有所增加。作为吃瓜群众的我,来跟个风.
以下文章来源于老叶茶馆 ,作者YeJinrong/叶金荣
Percona 资深工程师 Marco Tusa 近日爆料称,升级到 MySQL 8.0.38 版本后,当实例中的表个数超过一万个,实例重启后会发生 Crash 而失败,即便是重启时加上 validate_tablespace_paths=OFF 也不行。
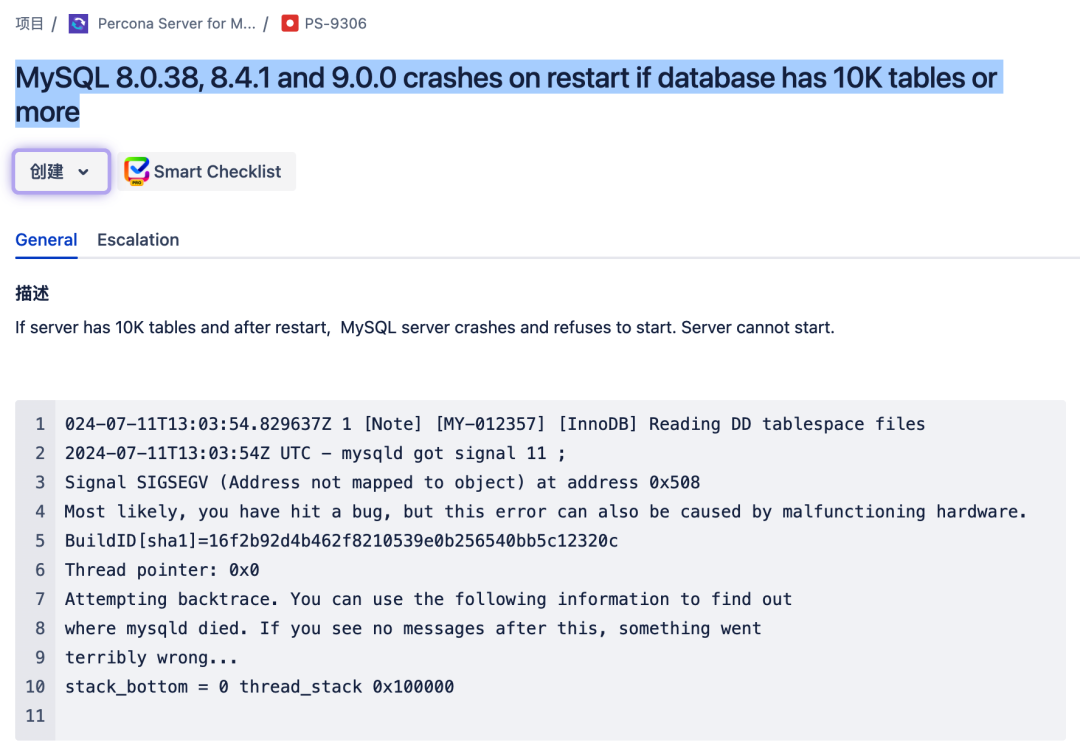
这个问题在 >= 8.0.38 版本中存在,包括 8.4.1 和 9.0.0。
详细复现过程参见:https://perconadev.atlassian.net/browse/PS-9306。
用 MySQL 9.0.0 版本测试:
-- 创建一个最简单的表,并写入数据
> CREATE DATABASE test;
> USE test;
> CREATE TABLE t_1 (
`id` int NOT NULL,
PRIMARY KEY (`id`)
);
> INSERT INTO t_1 SELECT 1;
然后反复创建类似上面的表,表个数达到 1 万。
> SELECT COUNT(*) FROM information_schema.tables WHERE TABLE_SCHEMA ='test';
+----------+
| count(*) |
+----------+
| 10000 |
+----------+
之后重启实例,就能看到日志里有类似下面的内容,启动失败:
[Note] [MY-012207] [InnoDB] Using 2 threads to scan 10002 tablespace files
[Note] [MY-012200] [InnoDB] Thread# 0 - Checked 876/10002 files
...
[Note] [MY-012201] [InnoDB] Checked 10002 files
[Note] [MY-012208] [InnoDB] Completed space ID check of 10004 files.
...
2024-07-12T06:48:14Z UTC - mysqld got signal 11 ;
Signal SIGSEGV (Address not mapped to object) at address 0x508
Most likely, you have hit a bug, but this error can also be caused by malfunctioning hardware.
BuildID[sha1]=7f06a4743d7801096bd81bc999201fdbca43a12c
Thread pointer: 0x0
Attempting backtrace. You can use the following information to find out
where mysqld died. If you see no messages after this, something went
terribly wrong...
stack_bottom = 0 thread_stack 0x100000
[root@db160 mysql-9.0.0-linux-glibc2.17-x86_64-minimal]# #0 0x103f726 <unknown>
#1 0x103fa8c <unknown>
#2 0x7f18f666ac1f <unknown> at sysdeps/unix/sysv/linux/x86_64/sigaction.c:0
#3 0x218a7be <unknown>
#4 0x21705a7 <unknown>
#5 0x2b1d263 <unknown>
#6 0x7f18f6660179 start_thread at /usr/src/debug/glibc-2.28/nptl/pthread_create.c:479
#7 0x7f18f4811dc2 <unknown> at sysdeps/unix/sysv/linux/x86_64/clone.S:95
#8 0xffffffffffffffff <unknown>
The manual page at http://dev.mysql.com/doc/mysql/en/crashing.html contains
information that should help you find out what is causing the crash.
确实挺拉胯的。
除了上面的测试用例,还测试了几种情形:
1、从 8.0.38 降级到 8.0.37、36、35 都是OK的,可以重新拉起,不报错;
2、拉起后删掉多余的表后再次用 8.0.38 也可以拉起;再次降级回 8.0.35 后又升级回 8.0.38 还是正常。
结论:
1、8.0.35 - 8.0.38 间可以反复升级、降级操作不影响,仅限我的测试场景,更复杂场景不能保证也 OK。
2、降级到 8.0.34 后就开始跪了,没再继续往下测试。
MySQL 8.0 手册和 release notes 里都没有说允许 8.0.35-8.0.38 间相互升降级,但目前简单测试是 OK 的。
当然,还是有办法可以规避的,也就是采用 共享/通用 表空间方案,例如:
-- 1. 共享表空间方案
> SET GLOBAL innodb_file_per_table = 0;
> CREATE TABLE ...;
-- 2. 通用表空间方案
> CREATE TABLESPACE test ADD DATAFILE 'test.ibd';
> CREATE TABLE t_1(...) TABLESPACE=test;
上述方案我已经验证过。
说下我个人看法,这个 Bug 虽很 low,但这个问题很小,也很容易规避。
MySQL 最近表现确实很辣鸡,但我依然热爱它 。。。这算不算罗曼罗兰说的那种英雄主义,咱就是这么乐观,哈哈哈。
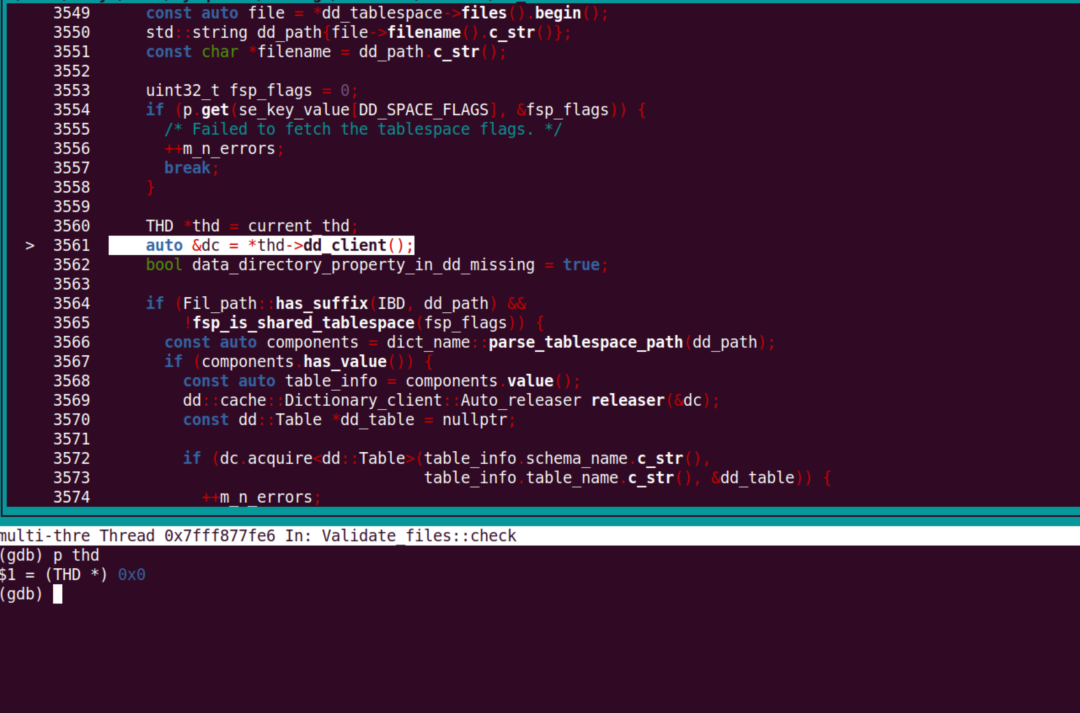
最后,看看 AliSQL 的内核开发者对引发此问题的 bug (#bug115517) 进行的深入分析。他曾在 AliSQL 上做了海量表场景下的启动优化,使百万表 Recovery 启动时间从 500 多秒缩短到 20 多秒。
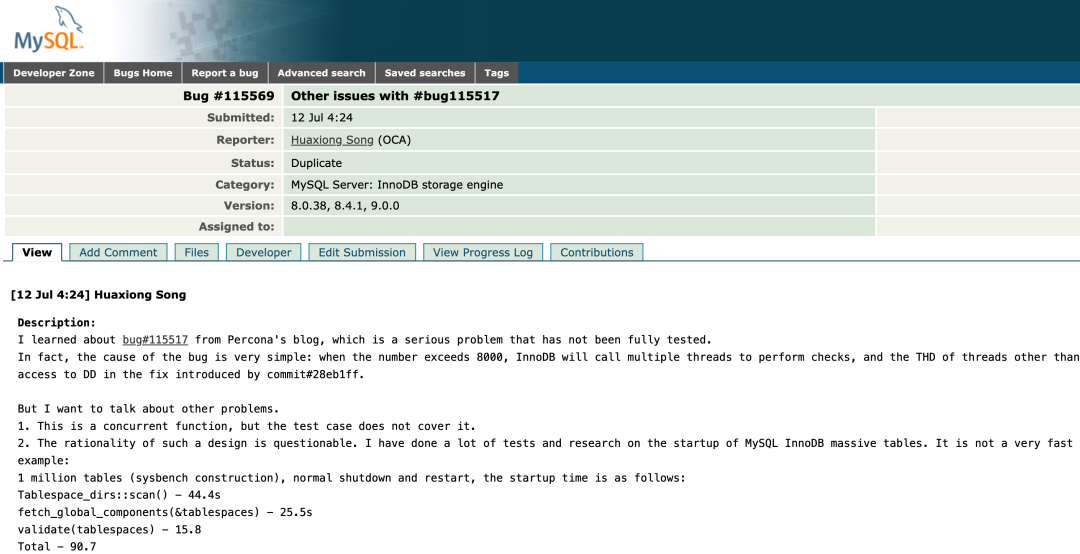
详情查看:https://bugs.mysql.com/bug.php?id=115569