引言
本文是对Mysql中几种常见日志及其作用的介绍

一、error log(错误日志)
MySQL 中的 error log(错误日志)是一种非常重要的日志类型,它记录了 MySQL 服务器在启动、运行及关闭过程中遇到的所有重要事件、错误信息、警告以及其他关键信息。以下是关于 MySQL 错误日志的一些关键点:
-
内容:错误日志不仅记录实际的错误,还会记录警告信息、MySQL 服务器启动和关闭过程中的详细信息、自动检查或修复表的操作、以及任何可能影响服务稳定性的严重事件(如关键级别的消息)。
-
配置:可以通过修改 MySQL 配置文件(如 /etc/my.cnf 或 /etc/mysql/my.cnf)来启用和配置错误日志。常见的配置项是 log_error,用来指定错误日志文件的路径。如果不指定文件名,MySQL 将使用默认位置。
-
查看:可以使用以下 SQL 命令来查看当前错误日志的配置:
SHOW GLOBAL VARIABLES LIKE 'log_error';
-
分析:错误日志对于诊断 MySQL 服务器问题至关重要。当服务器遇到问题时,首先查看错误日志通常能直接定位到问题所在。日志中可能包含了诸如连接错误、权限问题、磁盘空间不足、表损坏等信息。
-
管理:定期审查和维护错误日志是非常重要的,以确保系统健康并及时发现潜在问题。根据服务器的活跃程度和日志策略,可能需要定期轮换日志文件以避免磁盘空间耗尽。
-
示例:错误日志条目可能包括时间戳、错误级别(如警告或错误)、线程ID、具体的错误消息等。例如,它可能记录类似于“MySQL 无法打开表 XYZ 的错误”或“内存分配失败”的消息。
二、redo log(重做日志)
MySQL 的 redo log(重做日志)是 InnoDB 存储引擎使用的一种日志机制,用于确保数据的持久性和一致性。以下是关于 redo log 的一些关键概念:
作用
-
数据恢复:在数据库崩溃或意外关机后,redo log 可以帮助恢复未提交的事务对数据所做的更改,从而保证数据的一致性。
-
持久性:即使在系统崩溃的情况下,redo log 也能保证已提交事务的数据不会丢失。
工作原理
-
写入缓冲区:当一个事务开始修改数据时,除了修改缓冲池中的数据页之外,还会在 redo log buffer 中记录相应的重做日志条目。
-
预写日志 (WAL):在事务提交之前,redo log 必须先写入到磁盘上的 redo log 文件中,这个过程称为预写日志。这确保了如果系统在此期间崩溃,可以通过 redo log 进行恢复。
-
刷新到磁盘:事务提交时,redo log buffer 中的条目会被写入到磁盘上的 redo log 文件中。这一步骤可以通过不同的策略完成,例如立即同步到磁盘或延迟到一定条件满足时才进行。
-
恢复机制:在数据库启动时,如果检测到未完成的事务,InnoDB 会读取 redo log 文件,重放其中的更改,以确保数据库状态的一致性。
特性
-
物理日志:redo log 记录的是物理更改,这意味着它记录的是数据页上实际的字节更改,而不是 SQL 语句。这种记录方式使得恢复过程更快。
-
顺序写入:redo log 文件通常位于高速磁盘上,且日志的写入是顺序进行的,这比随机写入的性能要高很多。
配置
- MySQL 的 redo log 可以通过配置参数进行管理,例如 innodb_log_file_size 控制每个 redo log 文件的大小,innodb_log_files_in_group 控制 redo log 文件的数量。
总结
redo log 是 InnoDB 存储引擎中保证事务 ACID 特性的重要组成部分,特别是在持久性方面发挥着核心作用。通过预写日志和重做日志文件,InnoDB 能够在系统崩溃后恢复数据,确保数据库的完整性和一致性。
三、undo log(撤销日志)
MySQL 的 undo log(撤销日志)是 InnoDB 存储引擎中实现事务的隔离性和回滚机制的关键组件。以下是关于 undo log 的主要特点和工作原理:
功能
-
事务回滚:当事务需要回滚时,undo log 提供了一种机制来撤销已经执行的数据更改,将数据还原到事务开始之前的状态。无论是显式地执行 ROLLBACK 命令还是因为某种原因导致事务失败,undo log 都能够确保数据的原子性。
-
多版本并发控制 (MVCC):undo log 在实现 MVCC 机制中起到重要作用。为了支持并发读取,InnoDB 会利用 undo log 提供旧版本的数据视图。这样,在一个事务中执行查询时,即便其他事务已经修改了相关数据,查询仍能看到该数据在自己事务开始时刻的样子。
工作原理
-
记录更改前映像:当事务对数据进行修改(INSERT、UPDATE、DELETE)时,InnoDB 会先在 undo log 中记录这些操作的相反动作(即更改前的数据状态)。这被称为 undo 日志条目。
-
事务提交与回滚:事务提交前,相关的 redo log 必须先持久化。如果事务需要回滚,undo log 被用来恢复数据到事务开始前的状态;如果事务成功提交,undo log 会在适当的时候(比如不再有其他事务需要它来构建历史版本)被清理。
-
链表结构与空间管理:undo log 通常组织成链表形式,并且每个 undo 链表对应一个 undo log segment。undo 链表的第一个页面存储控制信息,后续页面则存储 undo 记录。undo 页面是从对应的 undo log segment 中申请的。
-
空间回收:InnoDB 使用一种称为 Purge 的机制来回收不再需要的 undo log 记录所占用的空间,这个过程通常在系统空闲时进行。
与 redo log 的关系
虽然都是日志机制,undo log 和 redo log 服务于不同的目的。redo log 保证事务的持久性,即使在系统崩溃后也能恢复数据;而 undo log 保障了事务的原子性和隔离性,支持事务的回滚和并发控制。
综上所述,undo log 在 MySQL 的事务处理和并发控制中扮演着至关重要的角色,确保了数据库在复杂事务操作下的数据一致性和完整性。
四、bin log(二进制日志)
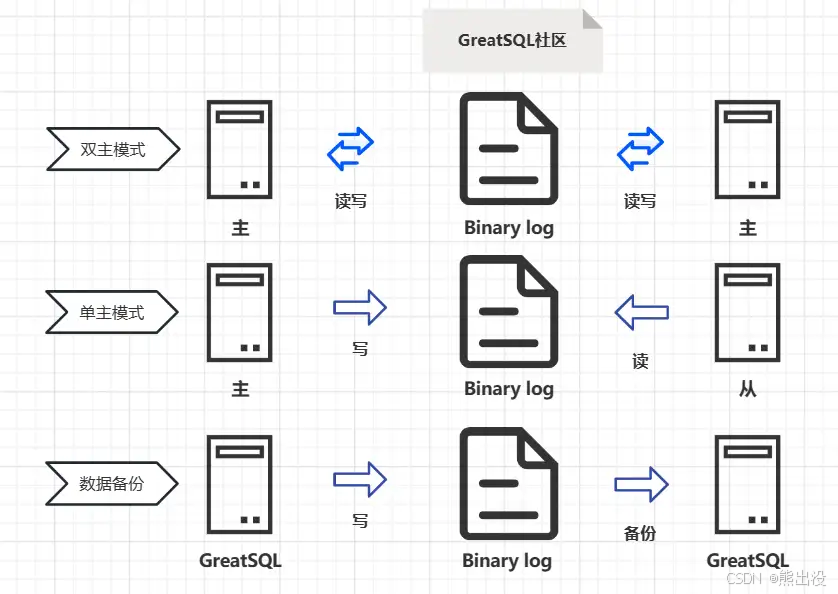
MySQL 的 binlog(二进制日志)是一种记录所有数据库更改的日志,它记录了所有更新数据的 SQL 语句(除了数据查询语句)。二进制日志在 MySQL 中具有多种用途,包括数据恢复、主从复制、数据分析等。以下是关于 binlog 的一些关键概念和工作原理:
作用
-
数据恢复:在数据丢失或数据库崩溃的情况下,可以使用 binlog 来恢复数据。
-
主从复制:binlog 是 MySQL 主从复制的基础,从服务器通过读取主服务器的 binlog 来复制数据和操作。
-
审计与数据分析:binlog 可以用于审计目的,追踪数据库的变更历史;同时,它也是进行数据挖掘和分析的重要数据源。
工作原理
- 记录更改:每当执行一条改变数据的 SQL 语句时,这条语句就会被记录在 binlog 中。记录的内容包括执行的 SQL 语句及其上下文信息。
- 预写日志:为了确保数据的安全性,MySQL 采用了预写日志(Write-Ahead Logging, WAL)策略,即在事务提交之前,先将事务的更改写入 binlog,然后再提交事务。这样即使在系统崩溃后,也可以通过 binlog 来恢复数据。
- 日志格式:
- STATEMENT:记录 SQL 语句本身,适用于大多数情况。
- ROW:记录每一行数据的变化,适用于触发器、存储过程等复杂场景。
- MIXED:默认模式,结合了 STATEMENT 和 ROW 的优点。
配置
-
启用 binlog:在 MySQL 的配置文件(如 my.cnf 或 my.ini)中,需要设置 log_bin 参数来启用 binlog。
-
日志文件:可以通过 expire_logs_days 设置 binlog 文件的保留天数,通过 max_binlog_size 设置单个 binlog 文件的最大大小。
-
日志格式:通过 binlog_format 设置 binlog 的格式。
总结
binlog 是 MySQL 数据库中极其重要的一个功能,它不仅能够用于数据恢复和主从复制,还是进行数据审计和分析的基础。合理配置和管理 binlog,对于保障数据库系统的稳定性和安全性具有重要意义。
五、slow query log(慢查询日志)
MySQL 的 slow query log(慢查询日志)用于记录执行时间超过特定阈值的 SQL 查询语句,它是数据库性能优化和问题排查的有力工具。以下是关于慢查询日志的一些关键信息和配置要点:
作用
-
性能分析:帮助识别执行效率低下的 SQL 语句,从而进行优化,提高数据库整体性能。
-
问题定位:当数据库响应缓慢时,可以通过慢查询日志找到耗时较长的查询,便于迅速定位问题。
-
监控趋势:持续监控慢查询日志可以发现查询性能随时间的变化,提前预防性能瓶颈。
配置
-
启用慢查询日志:通过在 MySQL 配置文件(my.cnf 或 my.ini)中设置 slow_query_log = 1 来启用慢查询日志。
-
定义慢查询时间阈值:使用 long_query_time 参数设定一个阈值(比如 1 秒),执行时间超过这个值的查询将会被记录。自 MySQL 5.7 开始,这个参数可以设置为小数,以更精确地控制。
-
指定日志文件路径:使用 slow_query_log_file 参数可以设置慢查询日志的存放路径和文件名。
-
记录额外信息:可以设置 log_queries_not_using_indexes 来记录未使用索引的查询,以及通过 log_slow_extra 来记录额外的性能相关字段,如锁时间和行扫描数量。
内容
-
慢查询日志会记录执行时间过长的 SQL 语句、执行时间、锁定时间、返回的行数以及使用的用户和主机信息。
-
根据配置,还可以包含是否使用了索引、查询计划等额外详情。
分析工具
-
MySQL 提供了 mysqldumpslow 工具来解析和摘要慢查询日志,便于快速查看最慢的查询和最常见的慢查询模式。
-
第三方工具,如 Percona Toolkit 或 pt-query-digest,提供了更强大的分析功能,包括统计信息、建议和图表展示。
注意事项
-
启用慢查询日志会对性能造成轻微影响,因此生产环境中应谨慎开启,并根据实际情况调整记录阈值。
-
定期清理和分析慢查询日志,避免日志文件过大导致磁盘空间紧张。
慢查询日志是数据库优化过程中的一个重要环节,合理利用可以显著提升数据库应用的性能和响应速度。
六、general log(通用查询日志)
MySQL 的 general log(通用查询日志)是一种记录所有客户端发送给 MySQL 服务器的 SQL 语句的日志。这包括所有的读写操作,如 SELECT, INSERT, UPDATE, DELETE 等语句。通用查询日志提供了详细的数据库活动记录,对于调试、审计和性能分析等方面非常有用。以下是关于通用查询日志的一些关键点:
作用
-
审计与监控:通用查询日志可以用于审计目的,记录所有对数据库的访问和操作,有助于监控数据库的使用情况。
-
故障排除:在遇到数据库问题时,通用查询日志可以帮助追踪问题的根源,尤其是当问题与特定的 SQL 语句相关时。
-
性能分析:虽然慢查询日志专门用于记录执行缓慢的查询,但通用查询日志可以提供更全面的 SQL 语句执行情况,有助于性能分析和调优。
配置
通用查询日志的开启和配置主要通过 MySQL 的配置文件(如 my.cnf 或 my.ini)或者通过 SQL 命令来完成。以下是一些关键的配置选项:
-
启用通用查询日志:通过设置 general_log = ON 来启用通用查询日志。
-
日志文件位置:使用 general_log_file 设置通用查询日志文件的名称和位置。
-
日志级别:log_output 设置日志输出目标,可以是文件(FILE)、表(TABLE)或其他输出方式。
注意事项
- 由于通用查询日志记录了所有 SQL 语句,因此在高负载的生产环境中,它可能会生成大量的日志数据,消耗大量磁盘空间和 I/O 资源。因此,通常建议仅在需要进行详细审计或调试时暂时启用通用查询日志,并在问题解决后将其关闭,以避免不必要的资源消耗。
使用
一旦通用查询日志被启用,所有发送到 MySQL 服务器的 SQL 语句都将被记录下来。这些日志条目通常包含查询的时间戳、客户端连接信息以及查询文本。
总结
通用查询日志是 MySQL 提供的一种强大的监控和审计工具,它记录了所有数据库操作的详细信息。然而,由于其可能产生的大量数据,应谨慎使用,尤其是在生产环境中。在需要深入了解数据库活动或进行故障排除时,适时启用和分析通用查询日志可以提供宝贵的线索。
七、relay log(中继日志)
MySQL 中的 relay log(中继日志)是专用于 MySQL 复制(Replication)功能的一个日志类型,主要存在于 MySQL 的从服务器(Slave)上。在主从复制架构中,中继日志扮演着承上启下的关键角色,负责在从服务器上记录从主服务器接收到的二进制日志(binlog)事件。以下是关于 relay log 的一些关键点:
作用
-
数据同步:中继日志作为主服务器二进制日志的副本,存储在从服务器上,用于逐步应用这些日志事件,以保持从服务器数据与主服务器数据的一致性。
-
断点续传:当从服务器与主服务器的连接因网络问题或其他原因中断后,中继日志可以作为断点,从中断处继续复制过程,确保数据复制的连续性和完整性。
工作原理
-
接收 binlog 事件:从服务器通过 I/O 线程与主服务器建立连接,请求并接收主服务器的二进制日志事件。
-
记录到 relay log:接收到的二进制日志事件被写入到从服务器的中继日志文件中,形成一系列的中继日志文件。
-
应用 binlog 事件:从服务器上的 SQL 线程读取中继日志,并按照顺序执行其中的 SQL 语句,从而更新从服务器的数据库。
-
管理与循环:中继日志也会根据配置进行循环,旧的中继日志文件在不再需要时会被自动删除,以避免无限增长占用过多磁盘空间。
配置
中继日志的相关配置通常在从服务器的 MySQL 配置文件(如 my.cnf 或 my.ini)中进行,包括但不限于:
- 中继日志基础路径:通过 relay_log 参数设置中继日志的基本文件名。
- 自动删除策略:relay_log_purge 控制是否自动删除不再需要的中继日志文件。
- 日志文件大小限制:max_relay_log_size 可以设置单个中继日志文件的最大大小,超过此限制时将自动创建新的中继日志文件。
总结
中继日志是 MySQL 复制机制中的重要组件,它确保了主服务器与从服务器间的数据同步。通过有效地管理中继日志,可以提高复制的效率和可靠性,同时减少因网络中断或故障导致的数据不一致风险。在设计和维护 MySQL 复制环境时,合理配置中继日志参数是保障数据复制顺畅的关键。

![[Maven] 打包编译本地Jar包报错的几种解决办法](https://i-blog.csdnimg.cn/direct/f3d9f140bbb142f68083c9e4633e08c9.png)