让我们面对现实吧,数字不会说谎。
尽管市场因人工智能而上涨,但其效应显然尚未转化为价值,因为只有不到4%的公司使用人工智能来生产商品和服务。
更糟糕的是,虽然一些大公司确实在拥抱人工智能,但高不可攀的成本阻碍了小公司效仿,讽刺的是,这项旨在使复杂任务民主化和促进竞争力的技术变成了一台巨大的不平等机器。
然而,情况可能很快就会改变,因为微软已经悄然发布了 1.58 位大型语言模型 (LLM),其性能与 16 位模型相当,但价格便宜且速度快了一个数量级。
微软称之为1 位 LLM 时代,你将会爱上它的每一秒。
没有钱,没有派对
尽管人工智能在研究层面取得了令人瞩目的成果,但它也受到经济、环境影响和价值缺失等多种弊端的困扰,无法成为现任者所预测的那样。
数字不对
美国国家经济研究局最近的一项研究证实,即使到了今天,企业对人工智能的采用率仍未达到两位数,麻省理工学院也对此表示赞同。
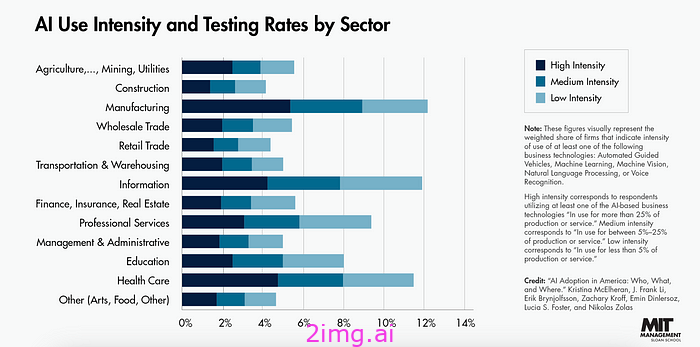
资料来源:麻省理工学院
但研究还显示出更令人担忧的迹象,即大公司与其他公司之间存在明显的不平衡。
更糟糕的是,它还表明不平衡不仅体现在规模上,还体现在行业甚至地理位置上。
多伦多大学的Kristina McElheran对此做出了最好的总结:
“数字时代已经到来,但它的到来并不平衡。”
但这远非唯一的问题。它对环境也有严重影响。
如果我们认为,根据马萨诸塞大学阿默斯特分校的数据,人工智能行业的碳足迹已经占全球排放量的 1% 左右,并且承认人工智能工作量将在未来几年大幅增加,那么我们都必须承认我们存在问题。
简而言之,除非我们找到一种方法使人工智能成为一种高效的技术,否则它的影响和价值创造将仅限于大公司,而我们其他人则只能制作有趣的玩具,用莎士比亚风格说唱德克萨斯烧烤。
然而,由于生成式人工智能给我们带来的范式转变,即“一对多”时代,价值机会仍然很残酷。
基础范式
当今人工智能成功的最大原因莫过于基础模型(FM),即可以执行各种不同下游任务的模型。
通过创建庞大的基础 AI 模型,我们获得了一系列好处,主要是泛化,使 AI 成为一种成功率更高的技术(此前 Gartner 指出 AI 的失败率为 90%)以及更具吸引力的回报。
最后,人工智能不需要训练来学习,因为你只需通过实时向模型提供必要的(通常是私人的)数据,将模型应用到每个用例中,这个过程正式称为提示词工程。
但我们最大的成功也是我们最大的负担。
金钱约束
由于其并行化能力,前沿 AI 模型需要非常昂贵的硬件 GPU 才能运行。
尽管 GPU 是基础,但 LLM 与这些硬件之间的关系却远非理想。
首先,当今大多数型号的尺寸都无法装入单个 GPU。我们目前最好的 GPU,如NVIDIA 的 H100或英特尔的 Gaudi 2,分别只有 80GB 和 96GB 的高内存带宽 (HBM)。
可能看起来很多,但我们正在讨论的模型在极端情况下(如 ChatGPT 或 Gemini Ultra)可能在 TeraByte 大小范围内。
因此,我们必须使用FSDP等分布式计算方法将模型“分解”成各个部分,其中模型的层按组分成多个单元,每个单元分配给单个或一组 GPU。
我们不能将模型存储在 Flash 或 HDD 中吗?
理论上,我们不能。每个预测都要运行整个模型,这意味着权重需要可供 GPU 核心访问,否则检索过程会花费很长时间,并且延迟将令人难以忍受。
苹果公司正在推动一项有趣的研究,将“ Flash LLM ”存储在更加丰富的闪存中,其中加入一个预测器,对于每个输入数据,该预测器可以预测 LLM 的哪些部分需要存储在 RAM 内存中,从而使大规模模型能够适应 iPhone 等硬件。
FSDP 部分解决了分布问题,但由于 GPU 需要共享其计算以进行训练和推理,因此增加了通信开销。
如果事情还不够复杂的话,GPU 的排列也很重要。
目前,最令人兴奋的方法是Ring Attention,其中 GPU 设置在环上,以将单个 GPU 计算与 GPU 逐个通信开销重叠,这样全局预测时间就不会受到工作负载分布式特性的限制。
与此同时,Predibase 等公司正在提供简单的无服务器框架,您可以在其中将多个模型存储到单个 GPU 中,从而大幅降低成本,而Groq等其他组织甚至建议我们根本不应该使用 GPU 进行推理工作负载,他们提出了速度极快的语言处理单元 (LPU)。
然而,无论采用何种方法,关键问题仍然存在,LLM 比理想的要大得多,并且所有以前的创新都围绕着处理大模型尺寸的问题。
因此,考虑到内存要求是主要瓶颈,目前非常流行的解决方案是量化模型。
最后,这就是微软的 1 位 LLM 发挥作用的地方。
1.58 比特可能改变世界
首先,量化到底是什么?
精度问题
量化是降低模型参数(权重)的存储精度以缩小模型尺寸并节省内存的过程,正如我们之前讨论的那样,这是这些模型的主要瓶颈。
目前大多数 LLM 使用 16 位或 2 字节精度来训练模型。换句话说,模型中的每个权重在内存中恰好占用 2 个字节。
必须指出的是,模型的某些参数,例如训练期间使用的优化器状态,是以全精度(4 个字节)存储的,但绝大多数是以 2 个字节存储的。
有不同的方法,但是概念总是一样的,将权重的值压缩成更小的位大小。
一种非常常见的方法是将 16 位权重转换为 4 位值。此时,似乎不清楚实际影响是什么,但请耐心听我举以下例子。
如果我们采用已经训练好的 500 亿参数的 LLM(按照今天的标准这是一个相当小的模型),以 2 字节精度,我们的模型重达 100 GB。
为了简化示例,我假设一个已经针对短序列进行训练的模型,因此 KV 缓存(对长序列有巨大影响的内存需求)可以忽略不计。
因此,您自动需要至少两个NVIDIA H100 GPU来存储模型。
但是如果将权重量化为 4 位,则实际上是将内存需求除以 4,因此模型突然“只有” 25GB,完美适合单个 GPU。
但如果这真的如此不可思议,为什么不一直这样做呢?
训练后的权衡
目前,大多数量化程序都是在训练后进行的。也就是说,以混合精度或全精度(2 或 4 个字节)训练模型,然后量化模型。
单是程序本身就已经是一个问题,因为它将不可逆转地对性能产生相当大的影响。
想象一下,你用一把巨大的网球拍训练了很长时间,突然,在比赛开始前,他们给你一把小得多的球拍。自然,你击球会很困难。
嗯,通过训练后量化,我们基本上对模型做同样的事情。
但是如果我们在量化模型的同时从头开始训练模型会怎么样?
这正是微软所推行的,但却走向了极端。
人工智能的未来?
简单来说,微软的论文提出了一种激进的方法,将每个权重的内存分配从 16 位减少到 1.58 位,内存需求减少了大约 16 倍。
换句话说,线性层中的所有权重都将具有值“1”,“-1”或“0”。
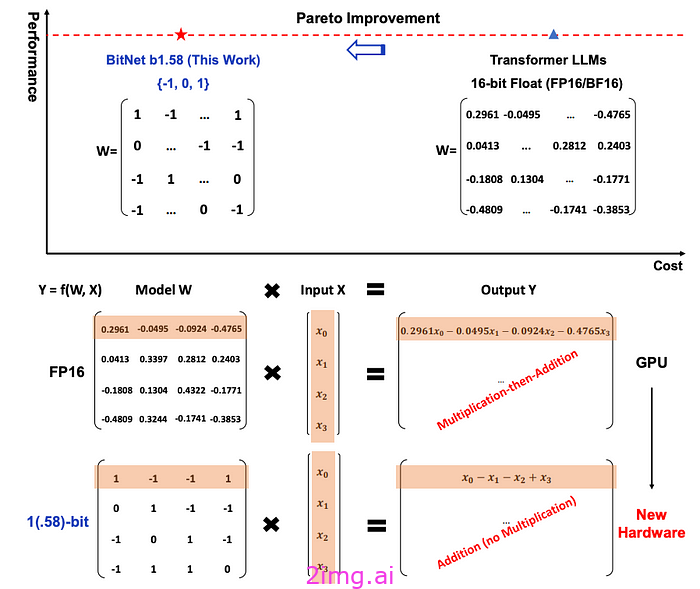
来源:微软
它们仅关注前馈权重,同时将标准激活和注意力保持在 8 位,因为最大量的计算和内存需求积累在前馈层上,而不是注意力上。
但微软方法的关键点在于它是“量化感知”,这意味着他们从头开始训练模型,同时并行应用量化。
这样,您就不必以一定的精度训练模型,然后再剪辑其值,而是从头开始以量化形式训练模型。
另一个值得注意的因素是,通过将这些权重设为 +/- 1 或 0,您基本上可以避免矩阵乘法。
但为什么这如此相关?
由于乘以 1 或 -1 归结为对另一个数字应用符号函数,而 0 会从等式中消除该数字,因此矩阵乘法变成了矩阵加法(如上图所示),从而大大减少了计算要求。
与我们的预期相反,这种妥协并没有对性能产生影响,恰恰相反。
速度飙升,但质量并未下降
与具有相似权重的模型相比,该模型不仅表现良好,而且在大多数基准测试中都胜过其对手。
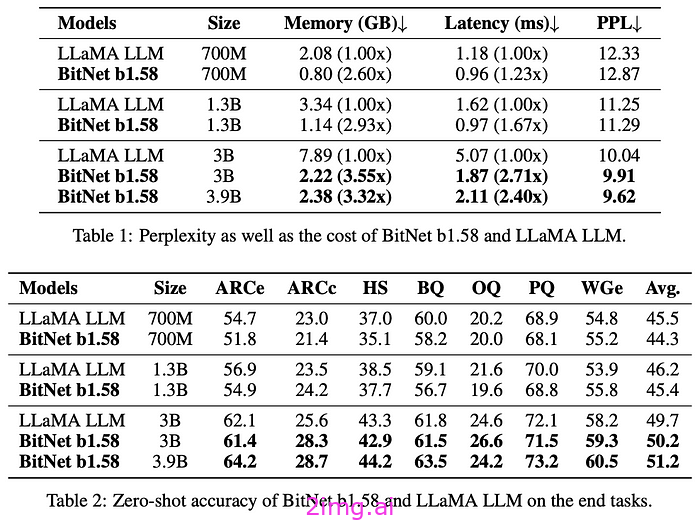
PPL 代表困惑度,它是 LLM 质量的主要客观衡量标准,衡量模型的“困惑度”。换句话说,分配给正确 token 的概率越高,模型的困惑度就越低。
研究人员随后声称,这种方法的主要好处适用于任何其他规模,并且随着规模的扩大而变得更加明显,这意味着:
- “在延迟、内存使用和能耗方面, 13B BitNet b1.58比3B FP16 LLM更高效。”
- “在延迟、内存使用和能耗方面,30B BitNet b1.58比7B FP16 LLM更高效。”
- “在延迟、内存使用和能耗方面, 70B BitNet b1.58比13B FP16 LLM更高效。”
如你所见,量化感知训练形成了自己的缩放规律,模型越大,影响越大。
并且在相同大小之间进行比较时,量化的 LLM 允许11 倍更大的批量大小(可以发送给模型的单个序列的数量),并且每秒生成的标记数增加 9 倍。

但这一切意味着什么呢?
简而言之,我们可能已经找到了一种更有效地训练前沿人工智能模型的方法,同时又不影响性能。
如果是这样,我们很快就会看到 1 位 LLM 成为常态,而需要巨额开支和庞大数据中心的工作负载最终可以在消费硬件上,甚至是在智能手机上运行。
例如,我们可以在你的 iPhone 中运行 +1000 亿个参数的模型,而对于最先进的笔记本电脑,这个数字将增长到 +300 的范围(当然,假设它们具有必要的 GPU,大多数高端消费端硬件已经具备这种情况)。
但我们甚至可以更进一步。
很快,你的数字产品(例如你的智能手机)就可以注入多个并行运行的不同 LLM,每个 LLM 都专门用于其下游任务,这将使 LLM 在我们的生活中更加普遍。
LLM 来处理您的电子邮件,LLM 来处理您的通知,LLM 来编辑您的照片……您说得出名字的。
如果这不能代表人工智能价值创造的本质,那我就不知道该告诉你什么了。











![C语言学习笔记[25]:循环语句for](https://i-blog.csdnimg.cn/direct/db7d2e60964a4d6c9a28612f01f10062.png)



