💫《博主介绍》:✨又是一天没白过,我是奈斯,DBA一名✨
💫《擅长领域》:✌️擅长Oracle、MySQL、SQLserver、阿里云AnalyticDB for MySQL(分布式数据仓库)、Linux,也在扩展大数据方向的知识面✌️
💖💖💖大佬们都喜欢静静的看文章,并且也会默默的点赞收藏加关注💖💖💖

白驹过隙,忙忙碌碌之后又是新的一周,最近在梳理公司所有环境的备份情况,忙的焦头烂额的,所以挤出来时间写博客实属不易,虽然工作很忙,但并不会因此而降低博客的质量(目前所有博客的平均质量分为94.1分😀),会认真认真写好每一篇博客的(写作不易,靓仔叹息,希望各位小伙伴点赞收藏加关注 💘 )。那么废话不多说,一起开始今天的内容——Percona XtraBackup工具备份指南:常用备份命令详解与实践。
用一篇文章是不能将Percona XtraBackup工具讲明白的,所以我将理论、命令、备份策略、异机恢复、使用场景等分成五篇去介绍,即使分为五篇也有部分内容没有涵盖到,但是这五篇文章都是精华,掌握了之后就可以轻松应对Percona XtraBackup工具的相关日常工作了,五篇文章的内容分别如下:
- 第一篇:Percona XtraBackup物理备份工具的基础理论概述
- 第二篇:Percona XtraBackup工具备份指南:常用备份命令详解与实践(当前篇)
- 第三篇:Percona XtraBackup标准化全库完整备份策略
- 第四篇:Percona XtraBackup全量+mysqlbinlog增量完成异机恢复:基于全库恢复 or 基于时间点恢复
- 第五篇:物理克隆数据clone插件、逻辑备份工具mysqldump/mysqlpump和物理备份工具Percona XtraBackup这三种的区别和各自的使用场景总汇
目录
安装PXB 8.0版本:
1、xtrabackup备份语法:
案例1:实例完全备份
案例2:实例压缩备份(恢复时需要借助qpress-11-linux-x64.tar解压缩工具,备份时不需要哦)
案例3:指定数据库备份
案例4:指定表备份
方式一:备份不同库下的不同表
方式二:备份指定文件里面的表(批量备份表)
2、xtrabackup恢复语法:
案例1:实例完全恢复
案例2:压缩实例完全恢复(恢复时需要借助qpress-11-linux-x64.tar解压缩工具,备份时不需要哦)
案例3:指定数据库恢复
案例4:指定表恢复
在第一篇文章中,我有介绍Percona XtraBackup(PXB)工具分为多个版本,包括了2.4版本、8.0版本、8.1、8.2、8.3版本。每个版本对应支持不同的MySQL版本,PXB版本对应具体的MySQL版本如下:
| percona xtrabackup版本 | MySQL版本支持 |
| 2.4 | 支持MySQL5.5、5.6和5.7版本 |
| 8.0 | 支持MySQL 8.0版本 |
| 8.1 | 支持MySQL 8.1版本 |
| 8.2 | 支持MySQL 8.2版本 |
| 8.3 | 支持MySQL 8.3版本 |
| 需要注意:PXB版本和MySQL版本有严格的对应关系,不同的PXB版本只能备份对应的MySQL版本。比如: 在MySQL5.7中,只能使用2.4版本,不能使用8.0版本备份(MySQL5.7使用8.0版本报:Please use Percona XtraBackup 2.4 for this database) 在MySQL8.0中,只能使用8.0版本,不能使用2.4版本备份(MySQL8.0使用2.4版本报:Please use Percona Xtrabackup 8.0.x for backups and restores) | |
在xtrabackup 2.4产品中,包括了2个命令innobackupex,xtrabackup。xtrabackup命令主要备份innodb和xtraDB两种表。innobackupex命令则封闭了xtrabackup,同时可以备份myisam数据表。也就是说xtrabackup命令整合了innobackupex命令全部的功能,支持了非innodb表,再早期的版本都是使用innobackupex命令备份,如果有innodb表,它会自动调用xtrabackup脚本来备份innodb表;使用xtrabackup也会调用innobackupex备份非innodb表。
2.4版本的innobackupex命令和xtrabackup命令全备时,默认备份sys、mysql、performance_schema默认数据库,但不备份information_schema数据库(提供了访问数据库元数据的方式。如数据库名或表名,列的数据类型,或访问权限等)。全备恢复时不影响information_schema的恢复,虽然系统目录下没有information_schema目录,但show databases可以看到这个数据库。如下是2.4版本中的命令:
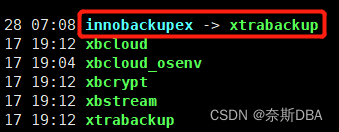
从2.4版本之后innobackupex功能全部集成到xtrabackup命令里面,innobackupex作为xtrabackup的一个软链接(不是linux层面的软连接哦),并且MySQL对内容进行了处理,敲2个命令会出现不同的参数。在8.0之后命令innobackupex取消,所有功能整合到xtrabackup命令中。如下8.0版本中的命令:
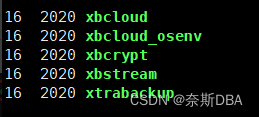
上述有陈述在PXB的2.4版本中,虽然备份可以通过innobackupex、xtrabackup两个命令,但是xtrabackup命令整合了innobackupex命令全部的功能,并且在PXB 2.4版本之后命令innobackupex取消,所有功能整合到xtrabackup命令中了,所以 这篇还是讲解一下xtrabackup命令的备份与恢复,就不再讲解innobackupex命令啦,因为在2.4版本使用innobackupex和xtrabackup命令实现的功能都是一样的 。
安装PXB 8.0版本:
第一步:通过链接可以一键下载不同的PXB版本,省时又省力,下载超链接👉Software Downloads - Percona👈
选择linux generic(通用)二进制作压缩的xtrabackup工具,因为我的MySQL版本是8.0.25,所以在选择PXB的时候小版本尽量也和MySQL的一致,平台选择linux generic,因为这里都是linux二进制压缩版本,其他的linux都是rpm包
第二步:解压,并移动到MySQL数据库的执行路径下
[root@mgr1 software]# tar -zxvf percona-xtrabackup-8.0.25-17-Linux-x86_64.glibc2.17.tar.gz [root@mgr1 software]# mv percona-xtrabackup-8.0.25-17-Linux-x86_64.glibc2.17 /mysql/app/mysql/bin [root@mgr1 software]# cd /mysql/app/mysql/bin [root@mgr1 bin]# mv percona-xtrabackup-8.0.25-17-Linux-x86_64.glibc2.17 xtrabackup [root@mgr1 bin]# chown -R mysql:mysql xtrabackup/ [root@mgr1 ~]# vi ~/.bash_profile export PATH=/mysql/app/mysql/bin/xtrabackup/bin:$PATH [root@mgr1 xtrabackup]# source ~/.bash_profile [root@mgr1 xtrabackup]# which xtrabackup

1、xtrabackup备份语法:
xtrabackup --help选项:
| 参数选项 | 描述 |
| --defaults-file=# | 指定数据库的参数文件 |
| -S, --socket=name | 指定用于连接的套接字文件的名称 |
| -u, --user=name | 指定MySQL数据库的用户名 |
| -p, --password[=name] | 指定MySQL用户名的密码 |
| --throttle= | 限制IO的读写速度,单位M/s。如:--throttle=10,就是表示限制在10M/s之内 |
| --databases= | 备份指定数据库。所有库都需要在双引内,每个之间用空格分开 |
| --tables-file= | 将需要备份的表整理到外部的txt文档中,工具调用然后进行备份。文件的最后不能多行,不能空格,否则全备 |
| --compress | 使用指定压缩单个备份文件压缩算法。支持的算法是“quicklz”,以及“lz4”。默认算法为“quicklz” |
| --compress-threads= | 使用几个线程进行压缩备份 |
| --decompress | 解压使用compress选项备份的文件,所有扩展名为.qp的文件 |
| --backup | 备份到目标目录,并备份到参数--target-dir文件中,配合使用 |
| --target-dir= | 指定备份文件生成的路径 |
| --parallel=# | 用于并行数据文件传输的线程数,默认值为1 |
| --slave-info和--safe-slave-backup | 用于记录备库的GTID和binlog changer信息到xtrabackup_slave_info |
| --stream=name | 该选项表示流式备份的格式,backup完成之后以指定格式到STDOUT,目前只支持tar和xbstream。 |
| --no-lock | 该选项表示关闭FTWRL的表锁,只有在所有表都是Innodb表并且不关心backup的binlog pos点,如果有任何DDL语句正在执行或者非InnoDB正在更新时(包括mysql库下的表),都不应该使用这个选项,后果是导致备份数据不一致,如果考虑备份因为获得锁失败,可以考虑--safe-slave-backup立刻停止复制线程(官方解释)。 备份时不对 non-InnoDB表进行锁表备份。正常备份时innodb表支持在线热备不影响正在执行的事务,而非non-InnoDB表需要加锁(亲测,自己理解,同innobackupex命令一样。 210913 16:09:24 Executing FLUSH TABLES WITH READ LOCK... 210913 16:09:24 Starting to backup non-InnoDB tables and files .......... 210913 16:09:25 Executing UNLOCK TABLES 210913 16:09:25 All tables unlocked 加上--no-lock,都将取消) |
案例1:实例完全备份
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --user=root --password=123456 --no-lock --backup --target-dir=/mysql/app/xtrabackup_full_3306 --parallel=2 2> xtrabackup_full_3306_err.log
###和innobackupex命令一样生成相关xtrabackup文件,但xtrabackup命令不支持自动日期文件夹,需要指定生成到那个文件夹
案例2:实例压缩备份(恢复时需要借助qpress-11-linux-x64.tar解压缩工具,备份时不需要哦)
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --user=root --password=123456 --no-lock --backup --compress --compress-threads=2 --target-dir=/mysql/app/xtrabackup_full_3306 --parallel=2 2> xtrabackup_full_3306_err.log ###全备数据库压缩,所有文件以qp结尾。压缩测试:直接全备7.0G,压缩全备2.9G,能节省接近2.5倍


案例3:实例打包、流备份
1)打包
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --user=root --password=123456 --no-lock --backup --target-dir=/mysql/app/ --parallel=2 --stream=tar 1> /mysql/app/xtrabackup_full_3306.tar 2> xtrabackup_full_3306_err.log ###将数据备份到/mysql/app/目录下(零散的文件),然后通过标准输出(1>)将零散的文件数据打包为xtrabackup_full_3306.tar
2)--stream=xbstream流备份(不推荐使用,需要借助xbstream命令解压)
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --user=root --password=123456 --no-lock --backup --target-dir=/mysql/app/ --parallel=2 --stream=xbstream 1> /mysql/app/xtrabackup_full_3306.tar 2> xtrabackup_full_3306_err.log ###将数据备份到/mysql/app/目录下(零散的文件),然后通过标准输出(1>)将零散的文件数据打包为xtrabackup_full_3306.tar


案例3:指定数据库备份
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --user=root --no-lock --password=123456 --backup --target-dir=/mysql/app/xtrabackup_full_3306 --databases="db1 db2" --parallel=2 2> xtrabackup_full_3306_err.log
###备份了指定的数据库,也备份ibdata、ib_buffer_pool、undo、logfile文件
案例4:指定表备份
方式一:备份不同库下的不同表
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --user=root --password=123456 --no-lock --backup --target-dir=/mysql/app/xtrabackup_full_3306 --databases="db1.tb1 db2.tb2" --parallel=2 2> xtrabackup_full_3306_err.log ###1、--databases参数备份表内容要用双引引起,每个表之间用空格分隔开,不然不备份 ###2、备份了指定的表,也备份了ibdata、ib_buffer_pool、undo、logfile文件。备份ded和itpuxdb库下的部分表,备份内容如下:
方式二:备份指定文件里面的表(批量备份表)
[root@mgr1 ~]# vi tbname.txt db1.table1 db1.table2 db2.table_name1 db2.table_name2 #文件的最后不能多行,不能空格,否则就会触发全备 [root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --user=root --password=123456 --no-lock --backup --target-dir=/mysql/app/xtrabackup_full_3306 --tables-file=tbname.txt --parallel=2 2> xtrabackup_full_3306_err.log ###备份了指定的表,也备份了ibdata、ib_buffer_pool、undo、logfile文件

2、xtrabackup恢复语法:
xtrabackup --help选项:
| 参数选项 | 描述 |
| --defaults-file=# | 指定数据库的参数文件。通过参数文件的datadir参数,将数据文件拷贝到对应的数据目录下。不然就是按照备份时生成的backup-my.cnf进行数据目录恢复 |
| -S, --socket=name | 指定用于连接的套接字文件的名称 |
| --prepare | 准备prepare一个完全备份,使数据文件处理一致状态,然后再进行恢复 |
| --use-memory= | 恢复时使用的内存。默认使用innodb_buffer_pool_size的大小。建议不要全部占用用于恢复 |
| --copy-back | 拷贝恢复所有的文件 |
案例1:实例完全恢复
恢复完全备份需要分成两步:
第一步:先recover恢复,到达数据一致性
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --prepare --use-memory=1G --parallel=2 --target-dir=/mysql/app/xtrabackup_full_3306 ###只是将数据达到一致性,不进行物理拷贝
第二步:restore还原,将文件copy
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --copy-back --use-memory=1G --parallel=2 --target-dir=/mysql/app/xtrabackup_full_3306 ###通过参数文件的datadir参数,将数据文件拷贝到对应的数据目录下。不然就是按照备份时生成的backup-my.cnf进行数据目录恢复
案例2:压缩实例完全恢复(恢复时需要借助qpress-11-linux-x64.tar解压缩工具,备份时不需要哦)
恢复压缩完全备份需要分成三步:
第一步:安装qpress-11-linux-x64.tar解压缩工具,并解压备份。 关于qpress-11-linux-x64.tar的安装包自己在csdn尝试上传过,但是提示该资源已经在csdn存在了,所以不能进行上传了,所以需要的小伙伴在csdn上寻找吧
[root@mysql1 software]# tar -xvf qpress-11-linux-x64.tar [root@mysql1 software]# cp qpress /usr/bin/ [root@mysql1 software]# qpress ---帮助 [root@mysql1 software]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --decompress --use-memory=1G --parallel=2 --target-dir=/mysql/app/xtrabackup_full_3306 ###1、--decompress:解压使用compress选项备份的文件,所有扩展名为.qp的文件 ###2、解压的备份还在同一个目录下,但原有的.qp文件不删除。在restore阶段只copy解压后的,解压前的.qp文件忽略,copy时不影响
第二步:先recover恢复,到达数据一致性
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --prepare --use-memory=1G --parallel=2 --target-dir=/mysql/app/xtrabackup_full_3306 ###只是将数据达到一致性,不进行物理拷贝
第三步:restore还原,将文件copy
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --copy-back --use-memory=1G --parallel=2 --target-dir=/mysql/app/xtrabackup_full_3306 ###通过参数文件的datadir参数,将数据文件拷贝到对应的数据目录下。不然就是按照备份时生成的backup-my.cnf进行数据目录恢复
案例3:指定数据库恢复
恢复指定数据库需要分成两步:
第一步:先recover恢复,到达数据一致性
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --prepare --use-memory=1G --parallel=2 --target-dir=/mysql/app/xtrabackup_full_3306
第二步:restore还原,将文件copy(部分数据库的恢复,不能直接用--copy-back,只能手工复制相应数据库)
备份数据库目录还原:
[root@mysql1 data]# cp -r /mysql/app/xtrabackup_full_3306/db1 ${datadir} ###datadir为数据文件路径 [root@mysql1 data]# cp -r /mysql/app/xtrabackup_full_3306/db2 ${datadir} ###datadir为数据文件路径备份共享表空间还原(ibdata为存放数据字典的共享表空间,而数据字典记录了表的信息,上面恢复出的数据库,可能存在表不能查询的情况,那么就是数据字典没有记录表的问题。不建议马上对共享表空间进行替换,等查询不出问题后替换保险些):
[root@mysql1 data]# cp -r /mysql/app/xtrabackup_full_3306/ibdata* ${datadir}赋予数据文件权限:
[root@mgr1 ~]# chown -R mysql:mysql ${datadir}/db1 [root@mgr1 ~]# chown -R mysql:mysql ${datadir}/db2 [root@mgr1 ~]# chown -R mysql:mysql ${datadir}/ibdata* ###需要重新赋予数据目录下所有数据文件的属性,不然开机报[ERROR] InnoDB: The innodb_system data file 'ibdata1' must be writable
案例4:指定表恢复
恢复指定表需要分成两步:
第一步:先recover恢复,到达数据一致性
[root@mgr1 ~]# xtrabackup --defaults-file=my.cnf --socket=mysql.sock --prepare --use-memory=1G --parallel=2 --target-dir=/mysql/app/xtrabackup_full_3306
第二步:restore还原,将文件copy(部分表的恢复,不能直接用--copy-back,只能手工复制相应表)
teset数据库表还原:
[root@mysql1 data]# cp -r /mysql/app/xtrabackup_full_3306/test/tb1* ${datadir}/test/ ###datadir为数据文件路径备份共享表空间还原(ibdata为存放数据字典的共享表空间,而数据字典记录了表的信息,上面恢复出的数据库,可能存在表不能查询的情况,那么就是数据字典没有记录表的问题。不建议马上对共享表空间进行替换,等查询不出问题后替换保险些):
[root@mysql1 data]# cp -r /mysql/app/xtrabackup_full_3306/ibdata* ${datadir}赋予数据文件权限:
[root@mgr1 ~]# chown -R mysql:mysql ${datadir}/test/tb1* [root@mgr1 ~]# chown -R mysql:mysql ${datadir}/ibdata* ###需要重新赋予数据目录下所有数据文件的属性,不然开机报[ERROR] InnoDB: The innodb_system data file 'ibdata1' must be writable
关于PXB第二篇《常用备份命令详解与实践》这篇文章到这里算是圆满结束了,通过详细的步骤让各位能够亲手实践并掌握这些关键命令。到目前已经是9千字了(累屁了😭),对于撰写每一篇博客我都秉持着如同撰写论文般的严谨态度。从资料收集、整理思路、撰写初稿到反复修订,每一步都凝聚着对知识的尊重,并且力求在减少错别字、提升文章可读性的同时,更加注重图文并茂的呈现方式,让复杂的技术知识变得易于理解,那么我们下篇见!!!