极致的感知性能与极简的感知pipeline一直是牵引我们持续向前的目标。为了实现该目标,打造一个性能优异的端到端感知模型是重中之重,充分发挥深度神经网络+数据闭环的作用,才能打破当前感知系统的性能上限,解决更多的corner case,让系统更加鲁棒。因此,在Sparse4D-v3中,我们主要做了两部分工作,其一是进一步提升模型的检测性能,另一是将Sparse4D拓展为一个端到端跟踪模型,实现多视角视频到目标运动轨迹端到端感知。
在Sparse4D-v2的落地过程中,我们发现其感知性能仍然具备一定的提升空间。
1. 首先,我们从训练优化的角度对Sparse4D进行了分析。我们观察发现以稀疏形式作为输出的模型,大多数都面临这个收敛困难的问题,收敛速度相对较慢、训练不稳定导致最终指标不高。因此我们参考DETR-like 2D检测算法,引入了最为有效的提升模型训练稳定性的辅助任务——"query denoising",并将其在时序上进行了拓展;
2. 其次,我们观察到相比以dense-heatmap做输出的模型,以稀疏形式作为输出的模型其距离误差明显要更大。经过分析与实验论证,我们认为这是由于检测框置信度不足以反应框的精度导致的。因此,我们能提出另外一个辅助训练任务 "quality estimation",这个任务不仅让模型的检测指标更高,还在一定程度上加速了模型收敛;
3. 最后,为了进一步提升模型性能,我们还对网络结构进行了小幅的优化。对于instance feature直接的特征交互模块,我们提出decoupled attention,在几乎不增加推理时延的情况下提升了感知效果。
除了可以获得更高效的检测能力以外,我们致力于发展稀疏感知框架的另一原因就是其能够更容易的将下游任务(如跟踪、预测及规划)以端到端的形式扩展进来。因此,在Sparse4D-v3中,我们成功地将多目标跟踪任务加入到模型中,实现了极致简洁的训练和推理流程,既无需在训练过程中添加跟踪约束,也无需进行任何的跟踪后处理(关联、滤波和生命周期关联),并且NuScenes上的实验结果证实了该跟踪方案的有效性。我们希望Sparse4D-v3的端到端跟踪方案会推动多目标跟踪算法的快速发展。
1. Temporal Instance Denoising

(a)中灰色和橙色模块仅在训练中使用,推理阶段只需保留; (b)灰色方格代表attention mask=True。
我们对GT加上小规模噪声来生成noisy instance,用decoder来进行去噪,这样可以较好的控制instance和GT之间的偏差范围,decoder 层之间匹配关系稳定,让训练更加鲁棒,且大幅增加正样本的数量,让模型收敛更充分,以得到更好的结果。具体来说,我们设置两个分布来生产噪声Delta_A,用于模拟产生正样本和负样本,对于3D检测任务加噪公式如下:
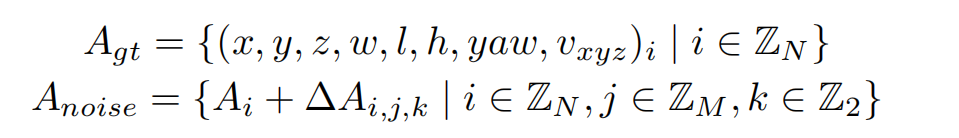
3D检测加噪公式
加上噪声的GT框需要重新和原始GT进行one2one匹配,确定正负样本,而并不是直接将加了较大扰动的GT作为负样本,这可以缓解一部分的分配歧义性。噪声GT需要转为instance的形式以输入进网络中,首先噪声GT可以直接作为anchor,把噪声GT编码成高维特征作为anchor embed,相应的instance feature直接以全0来初始化。
为了模拟时序特征传递的过程,让时序模型能得到denoising任务更多的收益,我们将单帧denoising拓展为时序的形式。具体地,在每个训练step,随机选择部分noisy-instance组,将这些instance通过ego pose和velocity投影到当前帧,投影方式与learnable instance一致。
具体实现中,我们设置了5组noisy-instance,每组最大GT数量限制为32,因此会增加5*32*2=320个额外的instance。时序部分,每次随机选择2组来投影到下一帧。每组instance使用attention mask完全隔开,与DINO中的实现不一样的是,我们让noisy-instance也无法和learnable instance进行特征交互,如上图(b)。
2.Quality Estimation
除了denoising,我们引入了第二个辅助监督任务,Quality Estimation,初衷一方面是加入更多信息让模型收敛更平滑,另一方面是让输出的置信度排序更准确。对于第二点,我们在实验过程中,发现两个异常现象:
1.相比dense-based算法,query-based算法的mATE(mean Average-Translation Error)指标普遍较差,即使是confidence高的预测结果也会存在较大的距离误差,如下图(a);
2. Sparse4D在行人上的Precision-Recall曲线前半段会迅速降低,如下图(b);
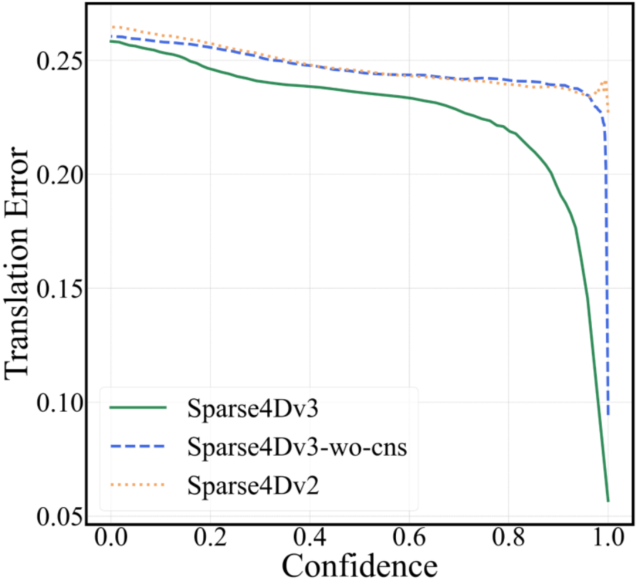
(a)confidence-translation error曲线,NuScenes val set
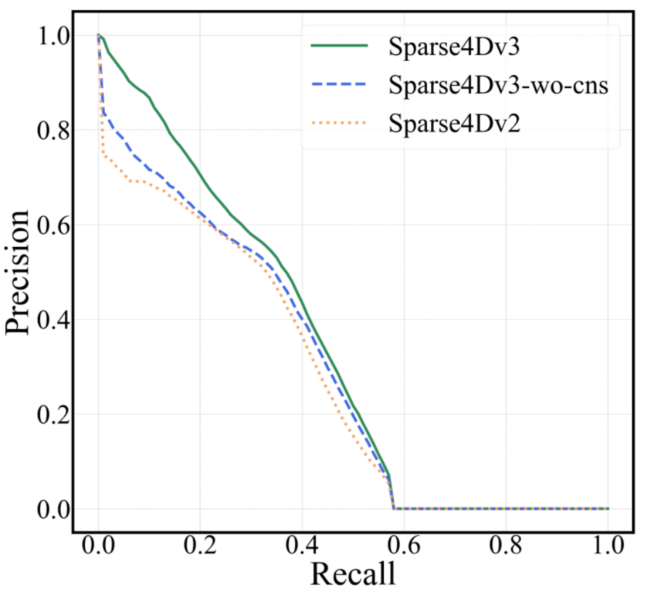
(b)precision-recall error曲线,NuScenes val set
上述现象说明,Sparse4D输出的分类置信度并不适合用来判断框的准确程度,这主要是因为one2one 匈牙利匹配过程中,正样本离GT并不能保证一定比负样本更近,而且正样本的分类loss并不随着匹配距离而改变。而对比dense head,如CenterPoint或BEV3D,其分类label为heatmap,随着离GT距离增大,loss weight会发生变化。
因此,除了一个正负样本的分类置信度以外,还需要一个描述模型结果与GT匹配程度的置信度,也就是进行Quality Estimation。对于3D检测来说,我们定义了两个quality指标,centerness和yawness,公式如下:
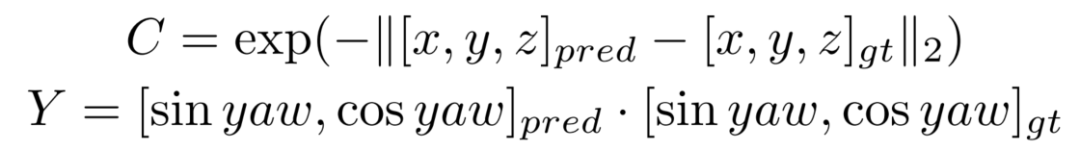
对于centerness和yawness,我们分别用cross entropy loss和focal loss来进行训练。
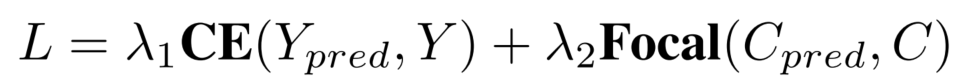
从上图的曲线来看,对比Sparse4D v3和v2,可以看出加入Quality Estimation之后,有效缓解了排序不准确的问题。
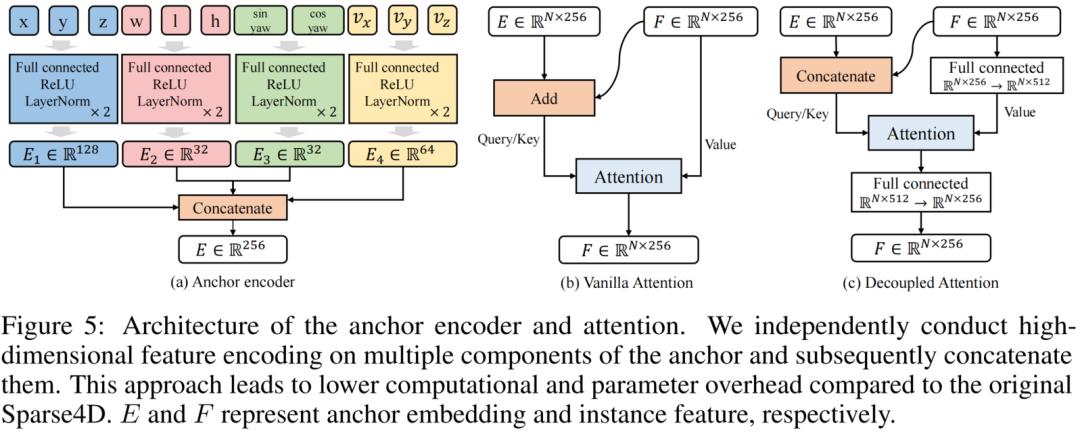
3. Decoupled Attention
Sparse4D中有两个instance attention模块,1)instance self-attention和2)temporal instance cross-attention。在这两个attention模块中,将instance feature和anchor embed相加作为query与key,在计算attention weights时一定程度上会存在特征混淆的问题,如图下所示。

为了解决这问题,我们对attention模块进行了简单的改进,将所有特征相加操作换成了拼接,提出了decoupled attention module,结构如下图所示。
4. End to End 3D Multi-object Tracking
由于Sparse4D已经实现了目标检测的端到端(无需dense-to-sparse的解码),进一步的我们考虑将端到端往检测的下游任务进行拓展,即多目标跟踪。我们发现当Sparse4D经过充分检测任务的训练之后,instance在时序上已经具备了目标一致性了,即同一个instance始终检测同一个目标。因此,我们无需对训练流程进行任何修改,只需要在inference阶段对instance进行ID assign即可,infer pipeline如下所示。

对比如MOTR(v1 & v3)、TrackFormer、MUTR3D等一系列端到端跟踪算法,我们的实现方式具有以下两点不同:
训练阶段,无需进行任何tracking的约束。这一做法一定程度上打破了对多目标跟踪训练的常规认知,我们进行以下简单分析:
a. 对于3D检测任务,我们加入了他车的运动补偿,当上一帧检测结果和速度估计准确时,投影到当前帧的temporal instance就可以准确的匹配到同一目标。因此,我们认为目标检测任务的优化目标和目标跟踪一致,当检测任务训练充分时,即使不需要加入tracking约束,也可以获得不错的跟踪效果。加入tracking 约束的实验我们也尝试过,但会导致检测和跟踪指标均降低;
b. 相比于MOTR等2D跟踪算法,3D跟踪可以利用运动补偿,一定程度上消除检测和跟踪任务在优化目标上的GAP,我认为这可能是Sparse4D能去掉tracking 约束的一大原因;
c. 另外,相比于MUTR3D等3D跟踪算法,Sparse4D的检测精度显著高于MUTR3D,也只有当检测精度足够高时,才能摆脱对tracking 约束的依赖。
2. Temporal instance不需要卡高阈值,大部分temporal instance不表示一个历史帧的检测目标。MOTR等方法中,为了更贴近目标跟踪任务,采用的track query会经过高阈值过滤,每个track query表示一个确切的检测目标。而Sparse4D中的temporal instance设计出发点是为了实现时序特征融合,我们发现有限的temporal instance数量会降低时序模型的性能,因此我们保留了更多数量的temporal instance,即使大部分instance为负样本。
5. 实验验证
Ablation Study
在NuScenes validation数据集上进行了消融实验,可以看出Sparse4D-v3的几个改进点(temporal instance denoising、decoupled attention和quality estimation)对感知性能均有提升。
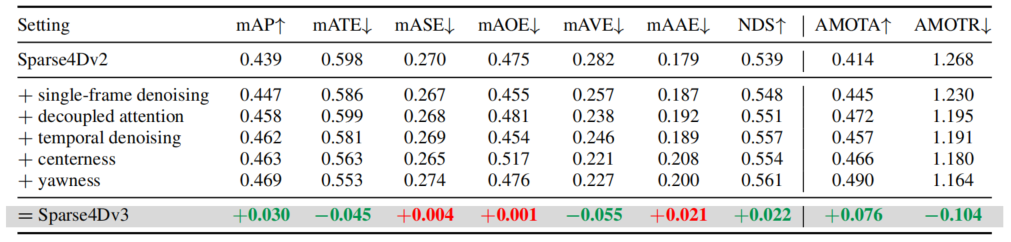
Ablation Experiments of Sparse4D-v3
Compare with SOTA
在NuScenes detection和tracking两个benchmark上,Sparse4D均达到了SOTA水平。
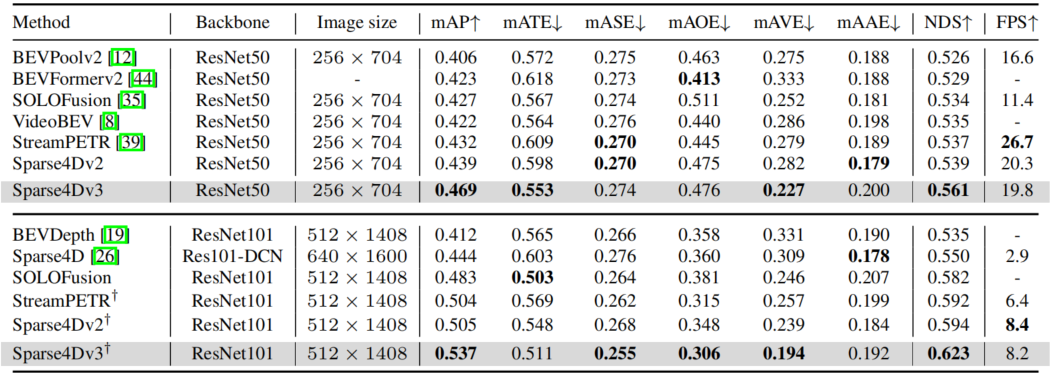
Results of Detection 3D on NuScenes Validation Set
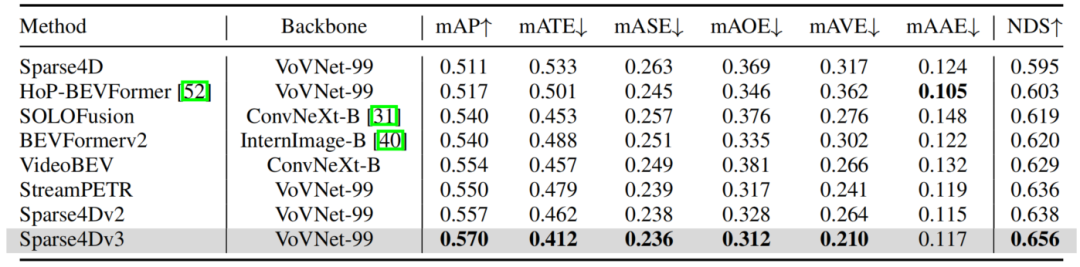
Results of Detection 3D on NuScenes Test Set
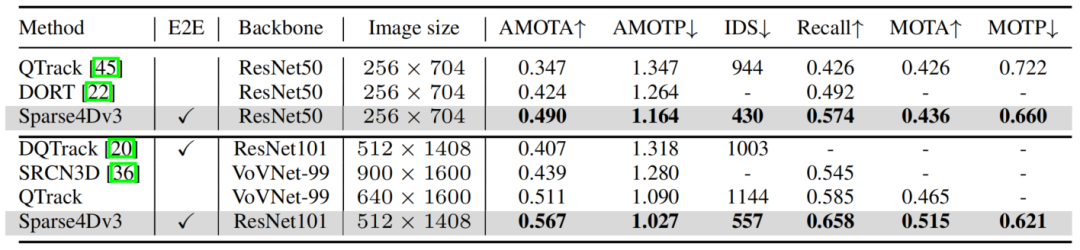
Results of Tracking 3D on NuScenes Validation Set

Results of Tracking 3D on NuScenes Test Set
Cloud-Based Performance Boost
针对云端系统,为了进一步提升模型的性能,我们进行了Offline 模型和加大backbone的尝试。
1. Offline 模型是通过加入未来帧特征,让模型获得更好效果,速度估计精度大幅提升,感知结果也更加平滑,对云端真值系统具有重要的意义。具体实现上,我们用Sparse4D-v1的多帧采样的方式来融合未来帧特征,共加入了未来8帧的特征。这里的未来帧融合方式计算复杂度较高,如何搭建更加高效的Offline 模型,也是今后重要的研究方向之一;
2. 我们采用EVA02-large作为backbone,这一改进带来的性能提升非常显著。特别是对于稀有类别,EVA02的检测精度有10+个点的提升。这主要得益于EVA02具有更大的参数量,经过更充分的预训练,其参数量是ResNet101/VoVNet的3倍,并且在ImageNet-21k基于EVA-CLIP蒸馏+Mask Image Model的形式进行了充分的自监督训练。大参数量+大数据+自监督训练,让模型收敛到更平坦的极值点,更加鲁棒,具备更强的泛化性;
我们最终在NuScenes test数据集上获得了NDS=71.9和AMOTA=67.7,在部分指标上甚至超过了LiDAR-based和multi-modality的模型。

展望与总结
在对长时序稀疏化3D 目标检测的进一步探索过程中,我们主要有如下的收获:
1. 卓越的感知性能:我们在稀疏感知框架下进行了一系列性能优化,在不增加推理计算量的前提下,让Sparse4D在检测和跟踪任务上都取得了SOTA的水平;
2. 端到端多目标跟踪:在无需对训练阶段进行任何修改的情况下,实现了从多视角视频到目标轨迹的端到端感知,进一步减小对后处理的依赖,算法结构和推理流程非常简洁。
我们希望Sparse4D-v3能够成为融合感知算法研究中的新的baseline,更多的研发者已经加入进来。我们这里给出几个值得进一步探索的方向:
1. Sparse4D-v3中对多目标跟踪的探索还比较初步,跟踪性能还有提升空间;
2. 如何在端到端跟踪的基础上,进一步扩展下游任务(如轨迹预测和端到端planning)是重要的研究方向;
3. 将Sparse4D拓展为多模态模型,具有非常大的应用价值;
4. Sparse4D还有待扩展为一个并行的多任务模型,比如加入online mapping、2D detection等。


















