背景
"Code smell" 是软件开发中的一个术语,指的是代码中可能表明存在问题的某些迹象或模式。这些迹象本身并不表示代码一定有错误,但它们通常表明代码可能难以理解、维护或扩展。Code smells 可以视为一种警告,提示开发者需要进一步检查代码以确定是否存在更深层次的问题。
常见的 code smells 包括:
- 重复代码(Duplication):代码中有重复的逻辑或结构。
- 过长函数(Long Method):一个函数执行太多任务,难以理解和维护。
- 过大类(Large Class):类包含太多的属性和方法,违反了单一职责原则。
- 过长参数列表(Long Parameter List):函数或方法有过多的参数,难以使用。
- 数据泥团(Data Clumps):多个类或方法中出现相同的数据结构。
- 基本类型偏执(Primitive Obsession):过度使用基本数据类型,而不是创建更有意义的类。
- 切换/状态/类型(Switch/State/Type):使用大量的条件语句来处理不同的状态或类型。
- 霰弹式修改(Shotgun Surgery):修改代码时需要在多个地方进行更改。
- 特征嫉妒(Feature Envy):函数或方法似乎更关心另一个类的数据而不是自己的。
- 数据类(Data Class):类只包含数据和访问器,没有行为。
识别和解决 code smells 是重构过程的一部分,可以帮助提高代码质量和可维护性。
单元测试中代码味道
在实际工作中,知道如何不编写代码可能与知道如何编写代码同样重要。测试代码也是如此;今天,我们将探讨编写单元测试时常见的错误。虽然编写单元测试是程序员的常见做法,但测试仍常常被视为二等代码。编写好的测试并不容易--就像在任何编程领域一样,有模式也有反模式。在 Gerard Meszaros 关于 xUnit 模式的书中,有一些关于测试气味的章节很有帮助,互联网上也有更多好东西。
一次测试的演变。 首先,我们要测试什么?一个原始函数:
public String hello(String name) {
return "Hello " + name + "!";
}
我们开始为它编写单元测试:
@Test
void test() {
}
就这样,我们的代码已经有了味道。
1. 无信息的名称
当然,只写 test、test1、test2 要比写一个翔实的名称简单得多。而且,这样也更简短!
但是,写起来容易的代码远不如读起来容易的代码重要--我们花在阅读代码上的时间更多,而可读性差会浪费大量时间。名称应该传达意图;应该告诉我们正在测试什么。
也许我们可以把测试命名为 testHello,因为它测试的是 hello 函数?不行,因为我们不是在测试方法,而是在测试行为。所以好的名字应该是 shouldReturnHelloPhrase:
@Test
void shouldReturnHelloPhrase() {
assert(hello("John")).matches("Hello John!");
}
除了框架之外,没有人会直接调用测试方法,因此名称太长也没有关系。它应该是一个描述性的、有意义的短语(DAMP)。
2. 没有 arrange-act-assert
名字还可以,但现在一行中塞进了太多的代码。最好把准备工作、我们要测试的行为和关于该行为的断言(rangement-act-assert)分开。
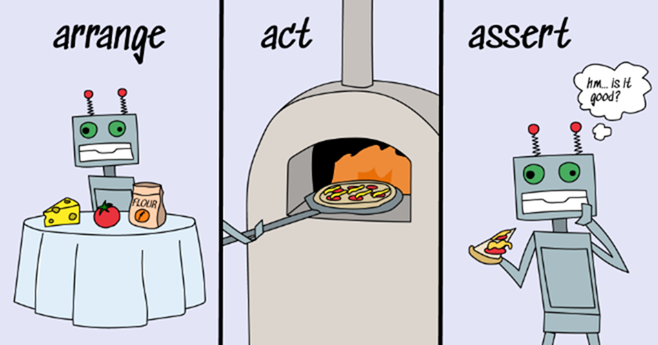
@Test
void shouldReturnHelloPhrase() {
String a = "John";
String b = hello("John");
assert(b).matches("Hello John!");
}
在 BDD 中,习惯使用 Given-When-Then 模式,在本例中也是如此。
3. 变量名不正确,没有变量重复使用
但看起来还是写得很匆忙。a "是什么?b "是什么?你可以推断出一些,但想象一下,这只是测试运行中失败的几十个测试中的一个(在几千个测试的测试套件中完全有可能)。在对测试结果进行排序时,你需要做大量的推断工作!
因此,我们需要正确的变量名。
我们在匆忙中还做了一件事--我们所有的字符串都是硬编码的。硬编码某些内容是可以的,但必须与其他硬编码内容无关!
也就是说,当您阅读测试时,数据之间的关系应该是显而易见的。a' 中的 "John "与断言中的 "John "是否相同?在阅读或修复测试时,我们不应该在这个问题上浪费时间。
因此,我们可以这样重写测试:
@Test
void shouldReturnHelloPhrase() {
String name = "John";
String result = hello(name);
String expectedResult = "Hello " + name + "!";
assert(result).contains(expectedResult);
}
4. 杀虫剂效应
这里还有一件事值得思考:自动化测试很好,因为你可以用很少的成本重复测试,但这也意味着随着时间的推移,它们的有效性会下降,因为你只是在重复测试完全相同的东西。这就是所谓的 "杀虫剂悖论"(Boris Beizer 在 20 世纪 80 年代创造的术语):虫子会对你用来杀死它们的东西产生抗药性。
要完全克服杀虫剂悖论可能是不可能的,但有一些工具可以通过在测试中引入更多的可变性来减少其影响,例如 Java Faker。让我们用它来创建一个随机名称:
@Test
void shouldReturnHelloPhrase() {
Faker faker = new Faker();
String name = faker.name().firstName();
String result = hello(name);
String expectedResult = "Hello " + name + "!";
assert(result).contains(expectedResult);
}
好在我们在上一步中将名称改为了变量--现在我们不必再查看测试,找出所有的 "约翰 "了。
5. 信息不全的错误信息
如果我们在匆忙中编写了测试,那么另一件我们可能没有考虑到的事情就是错误信息。在对测试结果进行分类时,您需要尽可能多的数据,而错误信息是最重要的信息来源。然而,默认的错误信息非常缺乏信息量:
java.lang.AssertionError at org.example.UnitTests.shouldReturnHelloPhrase(UnitTests.java:58)
太好了。我们唯一知道的就是断言没有通过。幸好,我们可以使用 JUnit`Assertions` 类中的断言。具体方法如下
@Test
void shouldReturnHelloPhrase4() {
Faker faker = new Faker();
String name = faker.name().firstName();
String result = hello(name);
String expectedResult = "Hello " + name + "";
Assertions.assertEquals(
result,
expectedResult
);
}
这是新的错误信息:
Expected :Hello Tanja! Actual :Hello Tanja
......这立刻告诉了我们出错的原因:我们忘记了感叹号!
经验教训
这样,我们就有了一个很好的单元测试。我们能从这个过程中吸取什么教训呢?很多问题都是由于我们有点懒惰造成的。不是那种好的懒惰,你会认真思考如何减少工作量。而是坏的懒惰,即为了 "速战速决 "而走阻力最小的路。 硬编码测试数据、剪切和粘贴、使用 "test "+方法名称(或 "test1"、"test2"、"test3")作为测试名称,这些做法在短期内稍显简单,但却使测试库更难维护。一方面,我们一直在谈论测试的可读性和易读性,但同时却把一行测试变成了 9 行,这有点讽刺。不过,随着测试数量的增加,我们在此提出的做法将为您节省大量的时间和精力。