目录
一、引言
二、自动语音识别(automatic-speech-recognition)
2.1 概述
2.2 技术原理
2.2.1 whisper模型
2.2.2 Wav2vec 2.0模型
2.3 pipeline参数
2.3.1 pipeline对象实例化参数
2.3.2 pipeline对象使用参数
2.3.3 pipeline对象返回参数
2.4 pipeline实战
2.4.1 facebook/wav2vec2-base-960h(默认模型)
2.4.2 openai/whisper-medium
2.5 模型排名
三、总结
一、引言
pipeline(管道)是huggingface transformers库中一种极简方式使用大模型推理的抽象,将所有大模型分为音频(Audio)、计算机视觉(Computer vision)、自然语言处理(NLP)、多模态(Multimodal)等4大类,28小类任务(tasks),共计覆盖32万个模型。

今天介绍Audio音频的第二篇,自动语音识别(automatic-speech-recognition),在huggingface库内共有1.8万个音频分类模型。
二、自动语音识别(automatic-speech-recognition)
2.1 概述
自动语音识别 (ASR),也称为语音转文本 (STT),是将给定音频转录为文本的任务。主要应用场景有人机对话、语音转文本、歌词识别、字幕生成等。

2.2 技术原理
自动语音识别主要原理是音频切分成25ms-60ms的音谱后,采用卷机网络抽取音频特征,再通过transformer等网络结构与文本进行对齐训练。比较知名的自动语音识别当属openai的whisper和meta的Wav2vec 2.0。
2.2.1 whisper模型
语音部分:基于680000小时音频数据进行训练,包含英文、其他语言转英文、非英文等多种语言。将音频数据转换成梅尔频谱图,再经过两个卷积层后送入 Transformer 模型。
文本部分:文本token包含3类:special tokens(标记tokens)、text tokens(文本tokens)、timestamp tokens(时间戳),基于标记tokens控制文本的开始和结束,基于timestamp tokens让语音时间与文本对其。
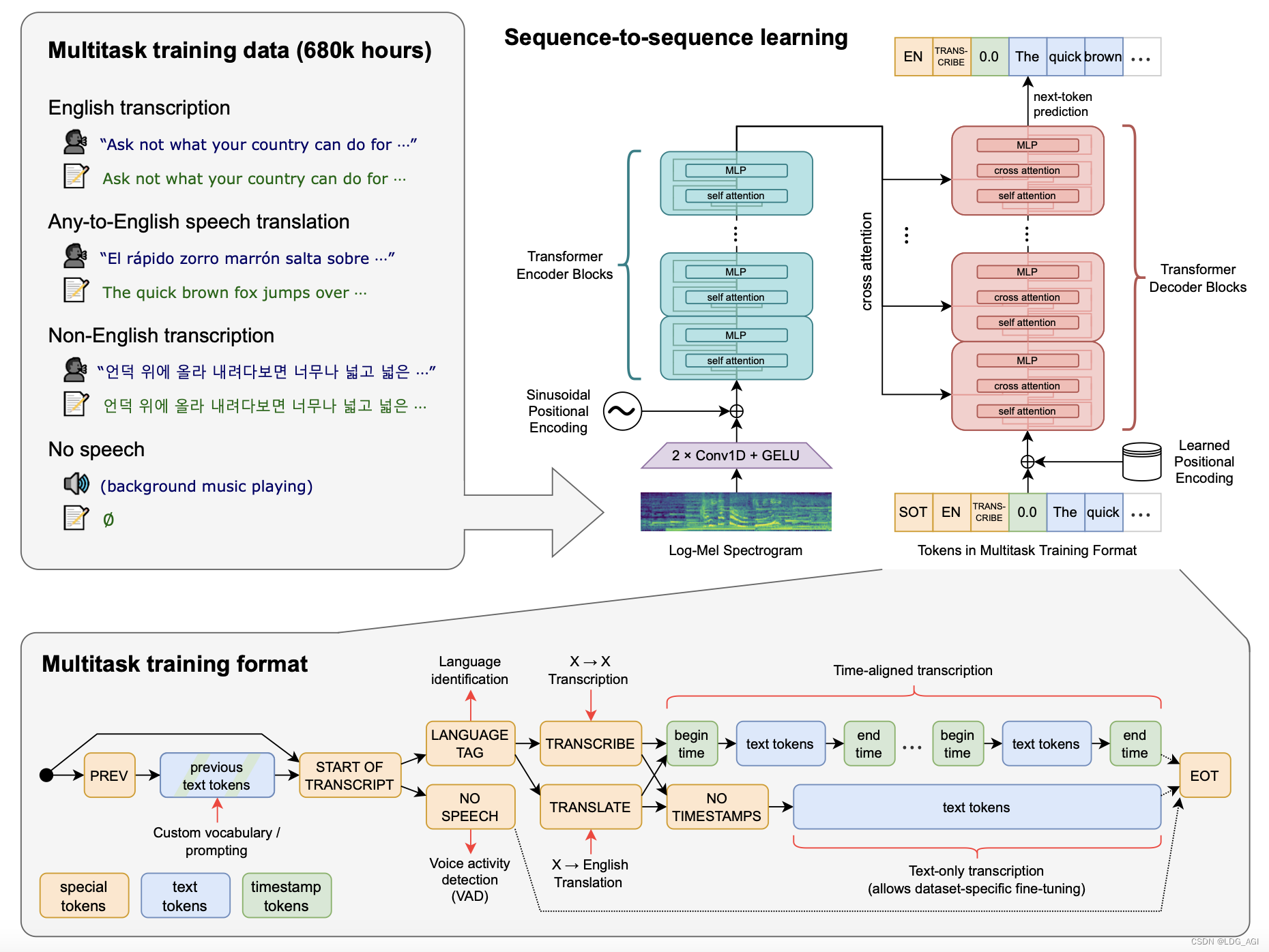
不同尺寸模型参数量、多语言支持情况、需要现存大小以及推理速度如下
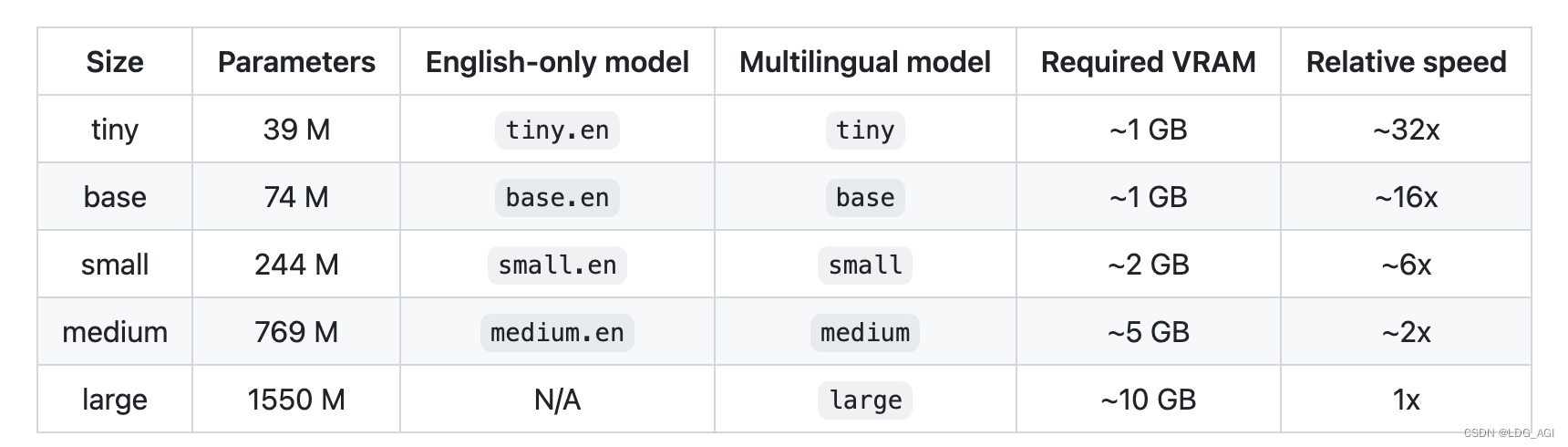
2.2.2 Wav2vec 2.0模型
Wav2vec 2.0是 Meta在2020年发表的无监督语音预训练模型。它的核心思想是通过向量量化(Vector Quantization,VQ)构造自建监督训练目标,对输入做大量掩码后利用对比学习损失函数进行训练。模型结构如图,基于卷积网络(Convoluational Neural Network,CNN)的特征提取器将原始音频编码为帧特征序列,通过 VQ 模块把每帧特征转变为离散特征 Q,并作为自监督目标。同时,帧特征序列做掩码操作后进入 Transformer [5] 模型得到上下文表示 C。最后通过对比学习损失函数,拉近掩码位置的上下文表示与对应的离散特征 q 的距离,即正样本对。

2.3 pipeline参数
2.3.1 pipeline对象实例化参数
- 模型(PreTrainedModel或TFPreTrainedModel)— 管道将使用其进行预测的模型。 对于 PyTorch,这需要从PreTrainedModel继承;对于 TensorFlow,这需要从TFPreTrainedModel继承。
- feature_extractor(SequenceFeatureExtractor)——管道将使用其来为模型编码波形的特征提取器。
- tokenizer ( PreTrainedTokenizer ) — 管道将使用 tokenizer 来为模型编码数据。此对象继承自 PreTrainedTokenizer。
- 解码器(
pyctcdecode.BeamSearchDecoderCTC,可选)— PyCTCDecode 的 BeamSearchDecoderCTC 可以传递用于语言模型增强解码。有关更多信息,请参阅Wav2Vec2ProcessorWithLM 。- chunk_length_s (
float,可选,默认为 0) — 每个块的输入长度。如果chunk_length_s = 0禁用分块(默认)。- stride_length_s (
float,可选,默认为chunk_length_s / 6) — 每个块左侧和右侧的步幅长度。仅与 一起使用chunk_length_s > 0。这使模型能够看到更多上下文并比没有此上下文时更好地推断字母,但管道会在最后丢弃步幅位,以使最终的重构尽可能完美。- 框架(
str,可选)— 要使用的框架,"pt"适用于 PyTorch 或"tf"TensorFlow。必须安装指定的框架。如果未指定框架,则默认为当前安装的框架。如果未指定框架且两个框架都已安装,则默认为 的框架model,如果未提供模型,则默认为 PyTorch 的框架。- 设备(Union[
int,torch.device],可选)— CPU/GPU 支持的设备序号。设置为None将利用 CPU,设置为正数将在关联的 CUDA 设备 ID 上运行模型。- torch_dtype (Union[
int,torch.dtype],可选) — 计算的数据类型 (dtype)。将其设置为None将使用 float32 精度。设置为torch.float16或torch.bfloat16将在相应的 dtype 中使用半精度。
2.3.2 pipeline对象使用参数
- 输入(
np.ndarray或bytes或str或dict) — 输入可以是:
str即本地音频文件的文件名,或下载音频文件的公共 URL 地址。文件将以正确的采样率读取,以使用 ffmpeg获取波形。这需要系统上安装ffmpeg 。bytes它应该是音频文件的内容,并以相同的方式由ffmpeg进行解释。- (
np.ndarray形状为(n,)类型为np.float32或np.float64)正确采样率的原始音频(不再进行进一步检查)dict形式可用于传递任意采样的原始音频sampling_rate,并让此管道进行重新采样。字典必须采用{"sampling_rate": int, "raw": np.array}可选格式"stride": (left: int, right: int),可以要求管道在解码时忽略第一个left样本和最后一个right样本(但在推理时使用,为模型提供更多上下文)。仅用于strideCTC 模型。- return_timestamps(可选,
str或bool)— 仅适用于纯 CTC 模型(Wav2Vec2、HuBERT 等)和 Whisper 模型。不适用于其他序列到序列模型。对于 CTC 模型,时间戳可以采用以下两种格式之一:
"char":管道将返回文本中每个字符的时间戳。例如,如果您得到[{"text": "h", "timestamp": (0.5, 0.6)}, {"text": "i", "timestamp": (0.7, 0.9)}],则意味着模型预测字母“h”是在 秒后0.5和0.6秒之前说出的。"word":管道将返回文本中每个单词的时间戳。例如,如果您得到[{"text": "hi ", "timestamp": (0.5, 0.9)}, {"text": "there", "timestamp": (1.0, 1.5)}],则意味着模型预测单词“hi”是在 秒后0.5和0.9秒之前说的。对于 Whisper 模型,时间戳可以采用以下两种格式之一:
"word":与上文相同,适用于字级 CTC 时间戳。字级时间戳通过动态时间规整 (DTW)算法进行预测,该算法通过检查交叉注意权重来近似字级时间戳。True:管道将返回文本中单词片段的时间戳。例如,如果您得到[{"text": " Hi there!", "timestamp": (0.5, 1.5)}],则意味着模型预测“Hi there!” 片段是在 秒后0.5和1.5秒之前说的。请注意,文本片段指的是一个或多个单词的序列,而不是像单词级时间戳那样的单个单词。- generate_kwargs(
dict,可选generate_config)—用于生成调用的临时参数化字典。有关 generate 的完整概述,请查看以下指南。- max_new_tokens(
int,可选)— 要生成的最大令牌数,忽略提示中的令牌数。
2.3.3 pipeline对象返回参数
- 文本(
str):识别的文本。- chunks(可选(,
List[Dict])当使用时return_timestamps,chunks将成为一个列表,包含模型识别的所有各种文本块,例如*[{"text": "hi ", "timestamp": (0.5, 0.9)}, {"text": "there", "timestamp": (1.0, 1.5)}]。通过执行可以粗略地恢复原始全文"".join(chunk["text"] for chunk in output["chunks"])。
2.4 pipeline实战
2.4.1 facebook/wav2vec2-base-960h(默认模型)
pipeline对于automatic-speech-recognition的默认模型是facebook/wav2vec2-base-960h,使用pipeline时,如果仅设置task=automatic-speech-recognition,不设置模型,则下载并使用默认模型。
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="automatic-speech-recognition")
result = pipe(speech_file)
print(result)可以将.mp3内的音频转为文本:
{'text': "WELL TO DAY'S STORY MEETING IS OFFICIALLY STARTED SOMEONE SAID THAT YOU HAVE BEEN TELLING STORIES FOR TWO OR THREE YEARS FOR SUCH A LONG TIME AND YOU STILL HAVE A STORY MEETING TO TELL"}2.4.2 openai/whisper-medium
我们指定模型openai/whisper-medium,具体代码为:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
from transformers import pipeline
speech_file = "./output_video_enhanced.mp3"
pipe = pipeline(task="automatic-speech-recognition", model="openai/whisper-medium")
result = pipe(speech_file)
print(result)输入为一段mp3格式的语音,输出为
{'text': " Well, today's story meeting is officially started. Someone said that you have been telling stories for two or three years for such a long time, and you still have a story meeting to tell."}2.5 模型排名
在huggingface上,我们筛选自动语音识别模型,并按下载量从高到低排序:

三、总结
本文对transformers之pipeline的自动语音识别(automatic-speech-recognition)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的代码极简的进行自动语音识别推理,应用于语音识别、字幕提取等业务场景。
期待您的3连+关注,如何还有时间,欢迎阅读我的其他文章:
《Transformers-Pipeline概述》
【人工智能】Transformers之Pipeline(概述):30w+大模型极简应用
《Transformers-Pipeline 第一章:音频(Audio)篇》
【人工智能】Transformers之Pipeline(一):音频分类(audio-classification)
【人工智能】Transformers之Pipeline(二):自动语音识别(automatic-speech-recognition)
【人工智能】Transformers之Pipeline(三):文本转音频(text-to-audio)
【人工智能】Transformers之Pipeline(四):零样本音频分类(zero-shot-audio-classification)
《Transformers-Pipeline 第二章:计算机视觉(CV)篇》
【人工智能】Transformers之Pipeline(五):深度估计(depth-estimation)
【人工智能】Transformers之Pipeline(六):图像分类(image-classification)
【人工智能】Transformers之Pipeline(七):图像分割(image-segmentation)
【人工智能】Transformers之Pipeline(八):图生图(image-to-image)
【人工智能】Transformers之Pipeline(九):物体检测(object-detection)
【人工智能】Transformers之Pipeline(十):视频分类(video-classification)
【人工智能】Transformers之Pipeline(十一):零样本图片分类(zero-shot-image-classification)
【人工智能】Transformers之Pipeline(十二):零样本物体检测(zero-shot-object-detection)
《Transformers-Pipeline 第三章:自然语言处理(NLP)篇》
【人工智能】Transformers之Pipeline(十三):填充蒙版(fill-mask)
【人工智能】Transformers之Pipeline(十四):问答(question-answering)
【人工智能】Transformers之Pipeline(十五):总结(summarization)
【人工智能】Transformers之Pipeline(十六):表格问答(table-question-answering)
【人工智能】Transformers之Pipeline(十七):文本分类(text-classification)
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)
【人工智能】Transformers之Pipeline(十九):文生文(text2text-generation)
【人工智能】Transformers之Pipeline(二十):令牌分类(token-classification)
【人工智能】Transformers之Pipeline(二十一):翻译(translation)
【人工智能】Transformers之Pipeline(二十二):零样本文本分类(zero-shot-classification)
《Transformers-Pipeline 第四章:多模态(Multimodal)篇》
【人工智能】Transformers之Pipeline(二十三):文档问答(document-question-answering)
【人工智能】Transformers之Pipeline(二十四):特征抽取(feature-extraction)
【人工智能】Transformers之Pipeline(二十五):图片特征抽取(image-feature-extraction)
【人工智能】Transformers之Pipeline(二十六):图片转文本(image-to-text)
【人工智能】Transformers之Pipeline(二十七):掩码生成(mask-generation)
【人工智能】Transformers之Pipeline(二十八):视觉问答(visual-question-answering)