1.论文速读
本文提出了一个重要的Decoder策略为:“Self-Consistency”,并将其用在CoT的Prompt工作中。
该策略作用:让LLM在处理复杂问题时,让他尝试多个推理路径,每一个推理路径都是一次CoT(Chain of Thought)的过程,每个可以得到一个Answer,并将所有Answers进行统计,进而得到投票次数最高的的Answer作为最终答案。
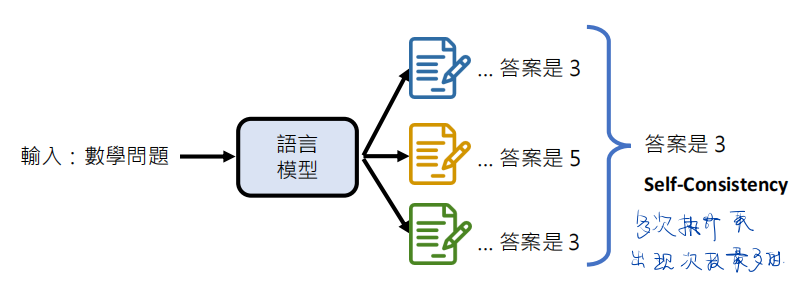
原文部分内容:人类的一个显著方面是,人们的思维方式会有所不同。我们很自然地认为,在需要深思熟虑的思考的任务中,可能有几种方法来解决这个问题。我们建议 在这样的过程中,可以通过从语言模型的解码器中采样【Sample生成多条思维链】,在语言模型中进行模拟。例如,如图1所示,一个模型可以对一个数学question生成几种可信的响应 它们都得到相同的正确答案(输出1和3)。由于语言模型不是完美的推理者,模型也可能产生不正确的推理路径或在一个错误 f的推理步骤(例如,在输出2中),但这样的解决方案不太可能得到相同的答案。也就是说,我们假设正确的推理过程,即使它们是多样化的,也会倾向于 在最终的答案中比错误的过程更一致。我们利用这种直觉,提出了以下的自一致性方法(Self-Consisency)。首先,用一组 手工编写的思维链样本(Wei et al.,2022)。
SC与CoT的区别:
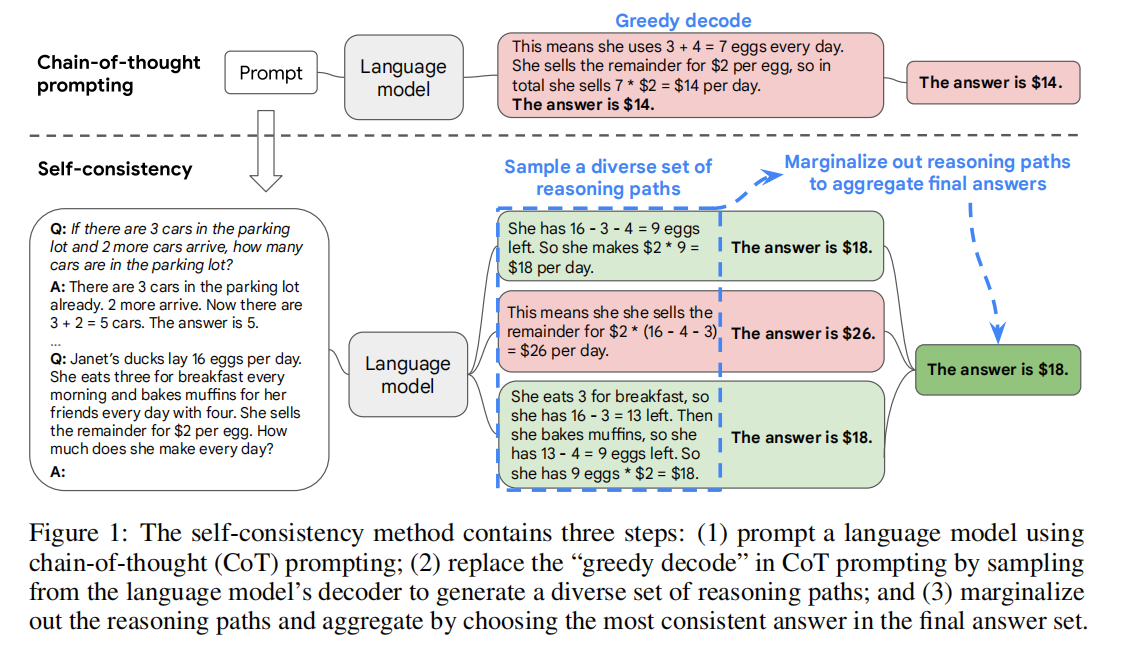
CoT-SC:解码器(Decoder)采用的策略是采样和边缘化(Sample and Marginalize),Sample的主要作用是让LLM的decoder生成多条推理路径,而Marginalize Out的作用在于:将生成的推理路径所得到的答案【final answer set】进行汇总确定唯一一个最终答案【the most consistent answer】。
CoT:采用的就是Greedy Decoding(贪婪策略),类似于贪心算法,在推理步骤中每一步选择都选择当前概率最高的词or标记。【这保证了生成的推理路径是单一的,每一步都是current下最优的一步】
问题:贪婪编码(Greedy Decoder)在文本生成过程中,每一步只会选择概率最高的词【即局部最优解】,忽略了长远的结果【全局结果】。
在方法上,除了多数投票(MV),还对比了不同答案聚合策略对推理任务的准确率,比如:归一化加权求和 【Weighted sum(normalized)】等。对比之下,发现加权求和归一化的效果和多数投票差不多:

具体是对答案标记为ai,过程即推理路径标记为ri,作者将(ri,ai)的生成联系起来,其中ri——>ai。比如: 考虑图 1 中的输出 3:前几句“她早餐吃 3 个……所以她有 9 个蛋 * $2 = $18.”构成 ri,而最后一句“答案是 $18”中的答案 18 被解析为 ai。

2.实验证明
同时论文指出,有时候 CoT 的使用让 LLM 的表现可能还不如标准的 prompt,这时候引入 Self-consistency 可以提升 CoT 的表现。如下是实验证明: 
另外,Self-Consistency跟很多算法都兼容:比如,temperature sampling、top-k sampling、nusleus-sampling。
we sample a set of candidate outputs from the language model’s decoder, generating a diverse set of candidate reasoning paths. Self-consistency is compatible with most existing sampling algorithms, including temperature sampling ( Ackley et al. , 1985 ; Ficler & Goldberg , 2017 ), top- k sampling ( Fan et al. , 2018 ; Holtzman et al. , 2018 ; Radford et al. , 2019 ), and nucleus sampling ( Holtzman et al. , 2020 ). Finally, we aggregate the answers by marginalizing out the sampled reasoning paths and choosing the answer that is the most consistent among the generated answers.
评价数据集(数学):
-
Math Word Problem Repository
-
AddSub
-
MultiArith
-
ASDiv
-
AQUA-RAT
-
GSM8K(小学数学问题)
-
CommonsenseQA
-
StrategyQA
-
AI2 Reasoning Challenge (ARC)

实验证明在MultiArith和CommonsenseQA等数据集中,CoT-SC比CoT的表现更加优异,尤其是path思维链越来越多,准确率愈来愈高。