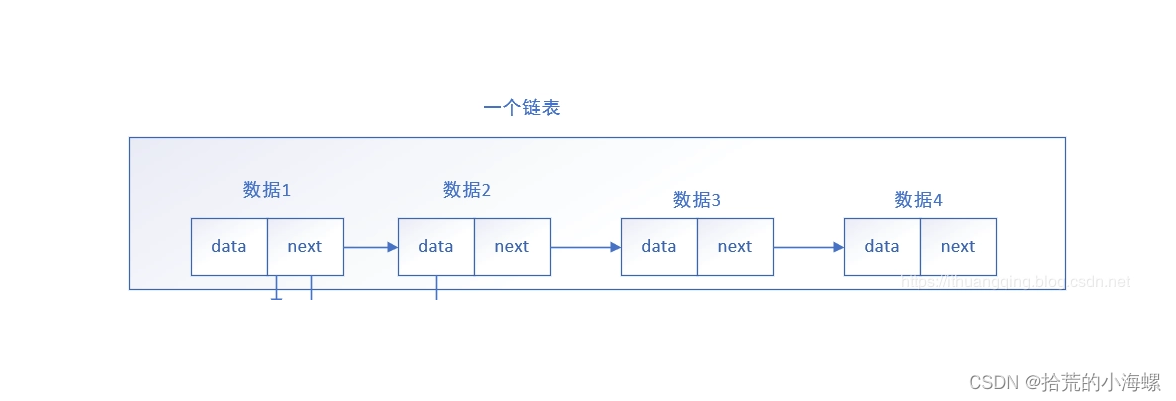
$accumulator 是 MongoDB 聚合管道中用于自定义数据处理逻辑的一个算子,它允许用户使用 JavaScript 编写代码来控制数据的初始化、累积、合并和最终输出。下面是对
$accumulator 各个部分的详细解释:
init: 这是一个 JavaScript 函数,用于初始化每个分组的状态。函数接收 initArgs 中指定的参数,并返回一个对象作为初始状态。这个状态对象将在后续的累积和合并过程中被使用。
initArgs: 这是一个可选的数组表达式,用于传递给 init 函数的参数。这些参数可以来自输入文档或常量值,用于帮助初始化状态。
accumulate: 这是一个 JavaScript 函数,用于更新每个分组的状态。每当处理一个新的输入文档时,accumulate 函数就会被调用一次,它接收当前状态和 accumulateArgs 中指定的参数,然后返回更新后的状态。
accumulateArgs: 这是一个数组表达式,用于传递给 accumulate 函数的参数。这些参数通常是从输入文档中提取的字段值,用于在累积过程中更新状态。
merge: 这是一个 JavaScript 函数,用于合并两个状态。当处理分布式聚合时,可能需要将不同节点上的状态合并到一起。merge 函数负责将两个状态对象合并成一个。
finalize: 这是一个可选的 JavaScript 函数,用于在所有累积和合并操作完成之后,对最终状态进行任何必要的调整。例如,可以使用 finalize 函数来筛选状态对象中的某些字段,或者执行一些计算操作。
lang: 这是一个字符串,指定了用于编写上述函数的编程语言。MongoDB 目前支持的语言有 js(JavaScript)和 mvel(MVEL,一种表达式语言)。默认情况下,lang 的值是 js。
a
c
c
u
m
u
l
a
t
o
r
算子提供了一种高度灵活的方式来处理聚合管道中的数据,允许用户实现复杂的业务逻辑。然而,由于涉及到
J
a
v
a
S
c
r
i
p
t
的执行,它可能会比其他聚合算子更消耗资源,因此在设计和使用时应考虑性能影响。此外,
accumulator 算子提供了一种高度灵活的方式来处理聚合管道中的数据,允许用户实现复杂的业务逻辑。然而,由于涉及到 JavaScript 的执行,它可能会比其他聚合算子更消耗资源,因此在设计和使用时应考虑性能影响。此外,
accumulator算子提供了一种高度灵活的方式来处理聚合管道中的数据,允许用户实现复杂的业务逻辑。然而,由于涉及到JavaScript的执行,它可能会比其他聚合算子更消耗资源,因此在设计和使用时应考虑性能影响。此外,accumulator 在 MongoDB 4.2 版本中被引入,所以使用时需确保 MongoDB 版本兼容。
db.books.aggregate([
{
$group :
{
_id : "$author",
avgCopies:
{
$accumulator:
{
init: function() { // Set the initial state
return { count: 0, sum: 0 }
},
accumulate: function(state, numCopies) { // Define how to update the state
return {
count: state.count + 1,
sum: state.sum + numCopies
}
},
accumulateArgs: ["$copies"], // Argument required by the accumulate function
merge: function(state1, state2) { // When the operator performs a merge,
return { // add the fields from the two states
count: state1.count + state2.count,
sum: state1.sum + state2.sum
}
},
finalize: function(state) { // After collecting the results from all documents,
return (state.sum / state.count) // calculate the average
},
lang: "js"
}
}
}
}
])