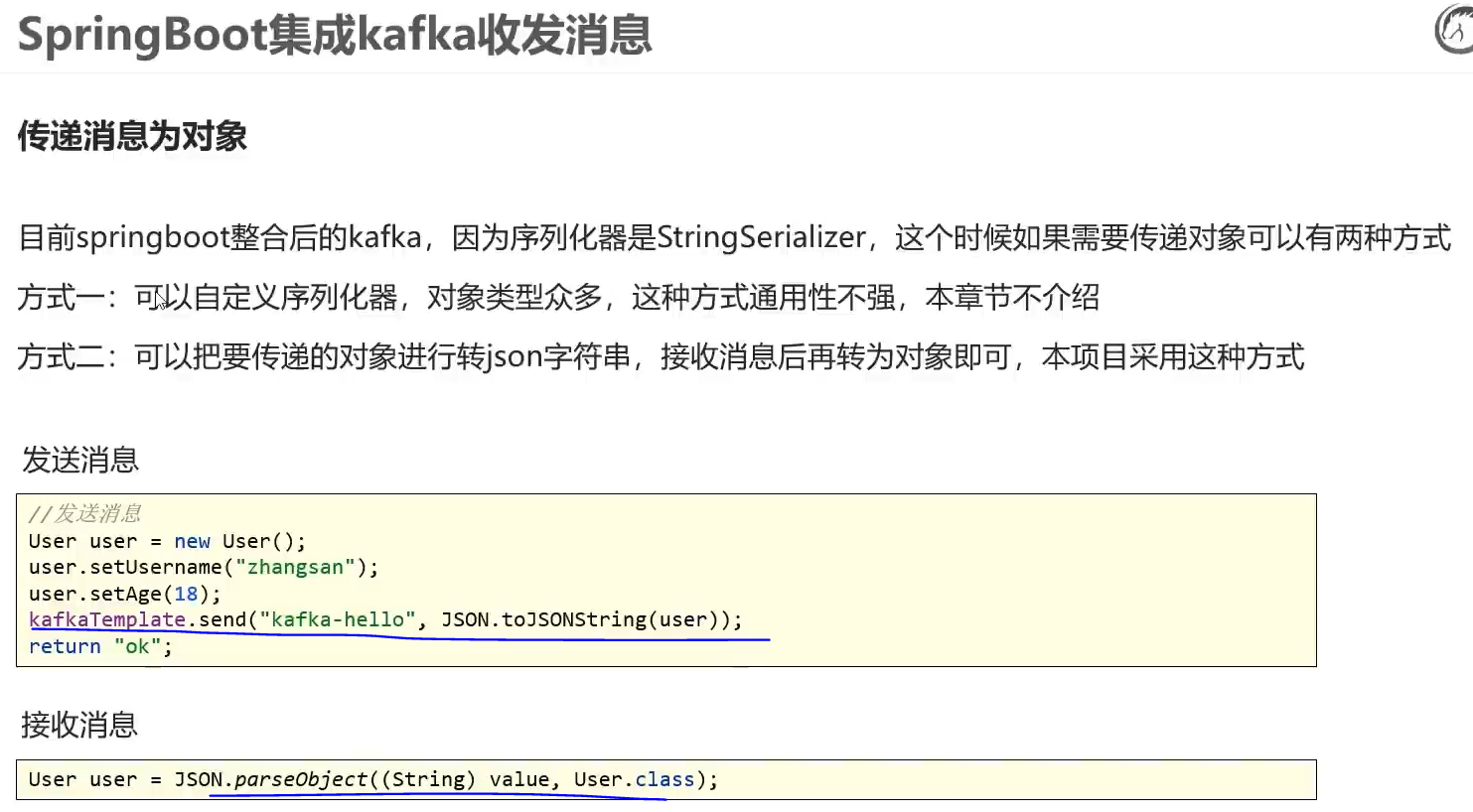
第4章中,当模型未知时,由于状态转移概率P未知,动态规划中值函数的评估方法不再适用,用蒙特卡洛的方法聘雇值函数。
在蒙特卡洛方法评估值函数时,需要采样一整条轨迹,即需要从初始状态s0到终止状态的整个序列数据,然后根据整个序列数据的回报来估计行为-值函数。
蒙特卡洛方法式(5.1)

现在的问题是,有没有一种新的方法可以不用等到终止状态就可以对行为值函数进行评估呢?
答案:Yes.并且这种方法已经在动态规划算法中出现了。在本节中,会重新会议动态规划方法,从而引入强化学习算法中最重要的时间差分强化学习。
5.1 从动态规划到时间差分强化学习
在动态规划中,值评估的公式(5.2)

在无模型的任务中,无法知道状态转移概率模型P,不能直接用式(5.2),而且在无模型任务中,需要评估的是行为-值函数,而不是值函数。下面的式(5.3)行为-值函数也不能直接使用。
行为-值函数公式(5.3):

暂且不管如何处理未知的模型概率,先看一下动态规划方法与蒙特卡洛方法值进行值函数评估时所用的数据的不同。
蒙特卡洛用到了整个轨迹的数据,而动态规划的方法只用到了相邻的两个状态的数据。如式(5.2)用状态s的后继状态s‘的值函数加上回报r估计状态s处的值函数,用的更新方法称为“用自举的方法进行更新”。自举===,字面意思,用自己的手把自己举起来。
于是,可以将自举的方法应用于无模型的行为-值函数的估计。按蒙特卡洛的思想,不是直接计算P,而是得到后继状态s'。
我们用蒙特卡洛中同样的思想,通过采样的方法,即智能体通过策略Π直接与环境进行交互得到后继状态s’。因此式(5.3)近似为式(5.4):

根据上式,对于状态s处动作a的行为值函数的估计,可用以下公式来计算,式(5.5):

在更新式(5.5)中,不需要等到轨迹结束,而仅仅等到下一个时刻就可以形成学习目标,从而进行更新。更新目标与当前值只差一个时刻,因此称该方法为时间差分方法。

为了从动态规划方法中的值迭代算法引出时间差分强化学习算法,先看一下值迭代的伪代码。

在该伪代码中,策略评估涉及第3行和第4行。在利用时间差分的方法进行策略评估时,可用式(5.5)来代替第4行。现在剩下的问题就是时间差分方法如何处理值迭代中的第3行。在值迭代算法中,第3行是要求值评估在整个状态空间进行遍历,这是值迭代算法收敛的重要保证。时间差分方法属于无模型方法,不能对状态进行遍历,但是为了保证收敛性,时间差分方法必须能保证访问到每个状态。为了满足这个条件,在时间差分方法中引入了探索-利用平衡机制。就像在蒙特卡洛算法中,采样的策略必须是柔和性的,即在每个状态处,采取每个动作的概率都大于0,最简单的采样是e-greedy策略。
根据采样策略和要评估的策略是否是同一个,将时间差分方法分为同策略强化学习算法和异策略强化学习算法。
(1)同策略强化学习算法:SARSA算法.
如采样策略为e-greedy,要评估的策略
也是e-greedy策略,在值函数的评估公式中差分目标的计算为:

同策略时间差分强化学习算法在进行策略评估是只需要利用采样相等的数据![]() ,这些数据的字母拼接起来为SARSA,因此得名。
,这些数据的字母拼接起来为SARSA,因此得名。
(2)异策略强化学习算法:Q-Learning算法。
如采样策略为e-greedy,要评估的策略
不是e-greedy策略。此时因为采样策略和评估策略为两个策略,所用我们只能用采样策略采集到的样本,而不能利用采样策略在该状态样本处的动作,所以可以用的数据格式为
,如果要对贪婪策略进行评估,则时间差分目标的计算为:
 跟SARSA 相比,Q-Learning不需要保存后继状态处的动作,只需保存后继状态。
跟SARSA 相比,Q-Learning不需要保存后继状态处的动作,只需保存后继状态。
异策略强化学习算法由于不需保存后继状态处的动作,因此进行值函数评估可以利用任意的策略产生的数据,而且数据可以被重复利用。因此,异策略具有很好的数据样本效率。
至此,我们对于着值迭代将强化学习算法的所有要素引出来,再总结一下:
①利用采样的方法来求近似值迭代中的状态转移概率P;
②利用探索平衡策略来替代值迭代中的状态空间的遍历。
下面通过伪代码进一步比较动态规划算法和时间差分强化学习算法的联系和区别。

上图所示的伪代码中,Q-Learning算法伪代码核心部分是5和6两行,其中
①5:利用探索-平衡策略来实现对每个状态的探索
②6:利用采样的方法求近似转移概率。
注意:强化学习算法可以看成无模型下的动态规划算法。强化学习算法可以解决动态规划中遇到的维数灾难问题。这是因为当状态空间的维数增加时,状态的数目呈指数级增长,遍历状态空间不可能。而强化学习不需要遍历整个状态空间,只需要利用探索-平衡策略将计算力集中在那些对于最优解很有潜力的状态空间。当强化学习中的值函数利用函数逼近的方法进行表述的时候,强化学习算法又叫近似动态规划,由此可见强化学习算法和动态规划的渊源。
5.2 时间差分算法代码实现
时间差分算法的实现包括同策略的SARSA算法和异策略的Q-Learning算法,两者代码实现差别不大。
本章实现的环境类和第3章相同。只需要声明一个TD_RL类,用来构建时间差分算法。
首先导入必要的包,从环境文件中导入环境类YuanYangEnv.

声明一个时间差分算法类TD_RL,在初始化函数中,初始化行为-值函数qvalue为100x4的零矩阵。定义类的子函数贪婪策略greedy_policy和e-greedy策略。定义动作对应的序号函数find_num以便找到对应的动作。

5.2.2 SARSA算法
伪代码如下:

1:初始化行为值函数。
2-9:算法主体,其中2(a)利用采样策略控制智能体与环境进行交互,得到交互数据;2(b)利用时间差分的方法估计当前状态s处采取动作a时的行为-值函数;2(c)智能体往前推进一步。
10:输出最终的最优贪婪策略。
代码如下:
定义时间差分算法类TD_RL的子函数Sarsa来实现同策略时间差分算法。该算法包括2个循环,在外循环实现多条轨迹循环,内循环则是智能体与环境进行交互产生的一条轨迹。

初始状态设置为0,也就是每条轨迹从初始状态0开始.接着调用算法类TD_RL的子函数greedy_test函数,该函数用来测试使用贪婪策略是否能找到目标点,如果第一次找到 目标点,则打印处为了找到目标点,算法共迭代的次数,在找到目标后继续学习,以便找到更优路径。如果找到最短路径,则打印出找到最短路径所需要迭代的次数,并结束学习。
下面代码为第2个循环,即轨迹内循环。在该循环中,智能体通过当前策略与环境进行交互产生一条轨迹。

如果智能体回到本次轨迹中已有的状态,则给出一个负的回报。

为了完成算法,还需事先定义贪婪策略的测试子函数greedy_test().该子函数用于测试初始状态为0时,采用当前贪婪策略是否能找到目标点。

如果找到目标点,flag标志位为1;如果找到目标点的步数小于21,即最短路径,则标志位设置为2.

5.2.3 Q-Learning算法
伪代码如下:

Q-Learning算法与SARSA算法几乎完全相同,唯一的区别在于值函数评估阶段。
def qlearning(self,num_iter, alpha, epsilon):
iter_num = []
self.qvalue = np.zeros((len(self.yuanyang.states), len(self.yuanyang.actions)))
#大循环
for iter in range(num_iter):
#随机初始化状态
# s = yuanyang.reset()
s=0
flag = self.greedy_test()
if flag == 1:
iter_num.append(iter)
if len(iter_num)<2:
print("qlearning 第一次完成任务需要的迭代次数为:", iter_num[0])
if flag == 2:
print("qlearning 第一次实现最短路径需要的迭代次数为:", iter)
break
s_sample = []
#随机选初始动作
# a = self.actions[int(random.random()*len(self.actions))]
a = self.epsilon_greedy_policy(self.qvalue,s,epsilon)
t = False
count = 0
while False==t and count < 30:
#与环境交互得到下一个状态
s_next, r, t = yuanyang.transform(s, a)
# print(s)
# print(s_next)
a_num = self.find_anum(a)
if s_next in s_sample:
r = -2
s_sample.append(s)
if t == True:
q_target = r
else:
# 下一个状态处的最大动作,a1用greedy_policy
a1 = self.greedy_policy(self.qvalue, s_next)
a1_num = self.find_anum(a1)
# qlearning的更新公式TD(0)
q_target = r + self.gamma * self.qvalue[s_next, a1_num]
# 利用td方法更新动作值函数
self.qvalue[s, a_num] = self.qvalue[s, a_num] + alpha * (q_target - self.qvalue[s, a_num])
s = s_next
#行为策略
a = self.epsilon_greedy_policy(self.qvalue, s, epsilon)
count += 1
# print(r)
return self.qvalue为了对这两个算法进行测试并显示轨迹,与蒙特卡洛相似,写一个主函数。首先实例化一个鸳鸯类yuanyang和时间差分算法brain,调用时间差分算法类的SARSA算法,将行为值函数赋予qvalue1,调用时间差分算法类的Q-Learning算法,将行为值函数赋予qvalue2.打印学到的行为值函数。
if __name__=="__main__":
yuanyang = YuanYangEnv()
brain = TD_RL(yuanyang)
# qvalue1 = brain.sarsa(num_iter =5000, alpha = 0.1, epsilon = 0.8)
qvalue2=brain.qlearning(num_iter=10000, alpha=0.1, epsilon=0.1)
#打印学到的值函数
yuanyang.action_value = qvalue2
##########################################
# 测试学到的策略
flag = 1
s = 0
# print(policy_value.pi)
step_num = 0
path = []
# 将最优路径打印出来
while flag:
# 渲染路径点
path.append(s)
yuanyang.path = path
a = brain.greedy_policy(qvalue2, s)
# a = agent.bolzman_policy(qvalue,s,0.1)
print('%d->%s\t' % (s, a), qvalue2[s, 0], qvalue2[s, 1], qvalue2[s, 2], qvalue2[s, 3])
yuanyang.bird_male_position = yuanyang.state_to_position(s)
yuanyang.render()
time.sleep(0.25)
step_num += 1
s_, r, t = yuanyang.transform(s, a)
if t == True or step_num > 30:
flag = 0
s = s_
# 渲染最后的路径点
yuanyang.bird_male_position = yuanyang.state_to_position(s)
path.append(s)
yuanyang.render()
while True:
yuanyang.render()经过运行,可以得到下面的结果。

终端打印的结果如下:

记录了几次数据
SARSA算法第1次完成任务需要的迭代次数为258,而qlearning需要192;
SARSA第1次实现最短路径需要的迭代次数为312,而Q-Learning需要244;
从最后的结果来看,SARSA算法第一次完成任务和实现最短路径需要的迭代次数都比Q-Learning多。回顾蒙特卡洛算法,它往往需要1000次左右的迭代才能完成任务。
由此可见,时间差分强化学习算法比蒙特卡洛算法效率更高。
yuanyang_env_td.py
import pygame
from load import *
import math
import time
import random
import numpy as np
class YuanYangEnv:
def __init__(self):
self.states=[]
for i in range(0,100):
self.states.append(i)
self.actions = ['e', 's', 'w', 'n']
self.gamma = 0.95
self.action_value = np.zeros((100, 4))
self.viewer = None
self.FPSCLOCK = pygame.time.Clock()
#屏幕大小
self.screen_size=(1200,900)
self.bird_position=(0,0)
self.limit_distance_x=120
self.limit_distance_y=90
self.obstacle_size=[120,90]
self.obstacle1_x = []
self.obstacle1_y = []
self.obstacle2_x = []
self.obstacle2_y = []
self.path = []
for i in range(8):
#第一个障碍物
self.obstacle1_x.append(360)
if i <= 3:
self.obstacle1_y.append(90 * i)
else:
self.obstacle1_y.append(90 * (i + 2))
# 第二个障碍物
self.obstacle2_x.append(720)
if i <= 4:
self.obstacle2_y.append(90 * i)
else:
self.obstacle2_y.append(90 * (i + 2))
self.bird_male_init_position=[0,0]
self.bird_male_position = [0, 0]
self.bird_female_init_position=[1080,0]
#def step(self):
def collide(self,state_position):
flag = 1
flag1 = 1
flag2 = 1
# 判断第一个障碍物
dx = []
dy = []
for i in range(8):
dx1 = abs(self.obstacle1_x[i] - state_position[0])
dx.append(dx1)
dy1 = abs(self.obstacle1_y[i] - state_position[1])
dy.append(dy1)
mindx = min(dx)
mindy = min(dy)
if mindx >= self.limit_distance_x or mindy >= self.limit_distance_y:
flag1 = 0
# 判断第二个障碍物
second_dx = []
second_dy = []
for i in range(8):
dx2 = abs(self.obstacle2_x[i] - state_position[0])
second_dx.append(dx2)
dy2 = abs(self.obstacle2_y[i] - state_position[1])
second_dy.append(dy2)
mindx = min(second_dx)
mindy = min(second_dy)
if mindx >= self.limit_distance_x or mindy >= self.limit_distance_y:
flag2 = 0
if flag1 == 0 and flag2 == 0:
flag = 0
if state_position[0] > 1080 or state_position[0] < 0 or state_position[1] > 810 or state_position[1] < 0:
flag = 1
return flag
def find(self,state_position):
flag=0
if abs(state_position[0]-self.bird_female_init_position[0])<self.limit_distance_x and abs(state_position[1]-self.bird_female_init_position[1])<self.limit_distance_y:
flag=1
return flag
def state_to_position(self, state):
i = int(state / 10)
j = state % 10
position = [0, 0]
position[0] = 120 * j
position[1] = 90 * i
return position
def position_to_state(self, position):
i = position[0] / 120
j = position[1] / 90
return int(i + 10 * j)
def reset(self):
#随机产生初始状态
flag1=1
flag2=1
while flag1 or flag2 ==1:
#随机产生初始状态,0~99,randoom.random() 产生一个0~1的随机数
state=self.states[int(random.random()*len(self.states))]
state_position = self.state_to_position(state)
flag1 = self.collide(state_position)
flag2 = self.find(state_position)
return state
def transform(self,state, action):
#将当前状态转化为坐标
current_position=self.state_to_position(state)
next_position = [0,0]
flag_collide=0
flag_find=0
#判断当前坐标是否与障碍物碰撞
flag_collide=self.collide(current_position)
#判断状态是否是终点
flag_find=self.find(current_position)
if flag_collide==1:
return state, -10, True
if flag_find == 1:
return state, 10, True
#状态转移
if action=='e':
next_position[0]=current_position[0]+120
next_position[1]=current_position[1]
if action=='s':
next_position[0]=current_position[0]
next_position[1]=current_position[1]+90
if action=='w':
next_position[0] = current_position[0] - 120
next_position[1] = current_position[1]
if action=='n':
next_position[0] = current_position[0]
next_position[1] = current_position[1] - 90
#判断next_state是否与障碍物碰撞
flag_collide = self.collide(next_position)
#如果碰撞,那么回报为-10,并结束
if flag_collide==1:
return self.position_to_state(current_position),-10,True
#判断是否终点
flag_find = self.find(next_position)
if flag_find==1:
return self.position_to_state(next_position),10,True
return self.position_to_state(next_position), -0.1, False
def gameover(self):
for event in pygame.event.get():
if event.type == QUIT:
exit()
def render(self):
if self.viewer is None:
pygame.init()
#画一个窗口
self.viewer=pygame.display.set_mode(self.screen_size,0,32)
pygame.display.set_caption("yuanyang")
#下载图片
self.bird_male = load_bird_male()
self.bird_female = load_bird_female()
self.background = load_background()
self.obstacle = load_obstacle()
#self.viewer.blit(self.bird_male, self.bird_male_init_position)
#在幕布上画图片
self.viewer.blit(self.bird_female, self.bird_female_init_position)
self.viewer.blit(self.background, (0, 0))
self.font = pygame.font.SysFont('times', 15)
self.viewer.blit(self.background,(0,0))
#画直线
for i in range(11):
pygame.draw.lines(self.viewer, (255, 255, 255), True, ((120*i, 0), (120*i, 900)), 1)
pygame.draw.lines(self.viewer, (255, 255, 255), True, ((0, 90* i), (1200, 90 * i)), 1)
self.viewer.blit(self.bird_female, self.bird_female_init_position)
#画障碍物
for i in range(8):
self.viewer.blit(self.obstacle, (self.obstacle1_x[i], self.obstacle1_y[i]))
self.viewer.blit(self.obstacle, (self.obstacle2_x[i], self.obstacle2_y[i]))
#画小鸟
self.viewer.blit(self.bird_male, self.bird_male_position)
# 画动作值函数
for i in range(100):
y = int(i / 10)
x = i % 10
#往东行为值函数
surface = self.font.render(str(round(float(self.action_value[i,0]), 2)), True, (0, 0, 0))
self.viewer.blit(surface, (120 * x + 80, 90 * y + 45))
#往南的值函数
surface = self.font.render(str(round(float(self.action_value[i, 1]), 2)), True, (0, 0, 0))
self.viewer.blit(surface, (120 * x + 50, 90 * y + 70))
# 往西的值函数
surface = self.font.render(str(round(float(self.action_value[i, 2]), 2)), True, (0, 0, 0))
self.viewer.blit(surface, (120 * x + 10, 90 * y + 45))
# 往北的值函数
surface = self.font.render(str(round(float(self.action_value[i, 3]), 2)), True, (0, 0, 0))
self.viewer.blit(surface, (120 * x + 50, 90 * y + 10))
# 画路径点
for i in range(len(self.path)):
rec_position = self.state_to_position(self.path[i])
pygame.draw.rect(self.viewer, [255, 0, 0], [rec_position[0], rec_position[1], 120, 90], 3)
surface = self.font.render(str(i), True, (255, 0, 0))
self.viewer.blit(surface, (rec_position[0] + 5, rec_position[1] + 5))
pygame.display.update()
self.gameover()
# time.sleep(0.1)
self.FPSCLOCK.tick(30)
if __name__=="__main__":
yy=YuanYangEnv()
yy.render()
while True:
for event in pygame.event.get():
if event.type == QUIT:
exit()
# speed = 50
# clock = pygame.time.Clock()
# state=0
# for i in range(12):
# flag_collide = 0
# obstacle1_coord = [yy.obstacle1_x[i],yy.obstacle1_y[i]]
# obstacle2_coord = [yy.obstacle2_x[i],yy.obstacle2_y[i]]
# flag_collide = yy.collide(obstacle1_coord)
# print(flag_collide)
# print(yy.collide(obstacle2_coord))
# time_passed_second = clock.tick()/1000
# i= int(state/10)
# j=state%10
# yy.bird_male_position[0]=j*40
# yy.bird_male_position[1]=i*30
# time.sleep(0.2)
# pygame.display.update()
# state+=1
# yy.render()
# print(yy.collide())
TD_RL.py
import numpy as np
import random
import os
import pygame
import time
import matplotlib.pyplot as plt
from yuanyang_env_td import *
from yuanyang_env_td import YuanYangEnv
class TD_RL:
def __init__(self, yuanyang):
self.gamma = yuanyang.gamma
self.yuanyang = yuanyang
#值函数的初始值
self.qvalue=np.zeros((len(self.yuanyang.states),len(self.yuanyang.actions)))
#定义贪婪策略
def greedy_policy(self, qfun, state):
amax=qfun[state,:].argmax()
return self.yuanyang.actions[amax]
#定义epsilon贪婪策略
def epsilon_greedy_policy(self, qfun, state, epsilon):
amax = qfun[state, :].argmax()
# 概率部分
if np.random.uniform() < 1 - epsilon:
# 最优动作
return self.yuanyang.actions[amax]
else:
return self.yuanyang.actions[int(random.random() * len(self.yuanyang.actions))]
#找到动作所对应的序号
def find_anum(self,a):
for i in range(len(self.yuanyang.actions)):
if a==self.yuanyang.actions[i]:
return i
def sarsa(self, num_iter, alpha, epsilon):
iter_num = []
self.qvalue = np.zeros((len(self.yuanyang.states),len(self.yuanyang.actions)))
#第一个大循环,产生了多少次实验
for iter in range(num_iter):
#随机初始化状态
epsilon = epsilon*0.99
s_sample = []
#初始状态,s0,
# s = self.yuanyang.reset()
s = 0
flag = self.greedy_test()
if flag == 1:
iter_num.append(iter)
if len(iter_num)<2:
print("sarsa 第一次完成任务需要的迭代次数为:", iter_num[0])
if flag == 2:
print("sarsa 第一次实现最短路径需要的迭代次数为:", iter)
break
#随机选初始动作
# a = self.yuanyang.actions[int(random.random()*len(self.yuanyang.actions))]
a = self.epsilon_greedy_policy(self.qvalue, s, epsilon)
t = False
count = 0
#第二个循环,一个实验,s0-s1-s2-s1-s2-s_terminate
while False==t and count < 30:
#与环境交互得到下一个状态
s_next, r, t = self.yuanyang.transform(s, a)
a_num = self.find_anum(a)
if s_next in s_sample:
r = -2
s_sample.append(s)
#判断一下 是否是终止状态
if t == True:
q_target = r
else:
# 下一个状态处的最大动作,这个地方体现on-policy
a1 = self.epsilon_greedy_policy(self.qvalue, s_next, epsilon)
a1_num = self.find_anum(a1)
# qlearning的更新公式
q_target = r + self.gamma * self.qvalue[s_next, a1_num]
# 利用td方法更新动作值函数,alpha
self.qvalue[s, a_num] = self.qvalue[s, a_num] + alpha * (q_target - self.qvalue[s, a_num])
# 转到下一个状态
s = s_next
#行为策略
a = self.epsilon_greedy_policy(self.qvalue, s, epsilon)
count += 1
return self.qvalue
def qlearning(self,num_iter, alpha, epsilon):
iter_num = []
self.qvalue = np.zeros((len(self.yuanyang.states), len(self.yuanyang.actions)))
#大循环
for iter in range(num_iter):
#随机初始化状态
# s = yuanyang.reset()
s=0
flag = self.greedy_test()
if flag == 1:
iter_num.append(iter)
if len(iter_num)<2:
print("qlearning 第一次完成任务需要的迭代次数为:", iter_num[0])
if flag == 2:
print("qlearning 第一次实现最短路径需要的迭代次数为:", iter)
break
s_sample = []
#随机选初始动作
# a = self.actions[int(random.random()*len(self.actions))]
a = self.epsilon_greedy_policy(self.qvalue,s,epsilon)
t = False
count = 0
while False==t and count < 30:
#与环境交互得到下一个状态
s_next, r, t = yuanyang.transform(s, a)
# print(s)
# print(s_next)
a_num = self.find_anum(a)
if s_next in s_sample:
r = -2
s_sample.append(s)
if t == True:
q_target = r
else:
# 下一个状态处的最大动作,a1用greedy_policy
a1 = self.greedy_policy(self.qvalue, s_next)
a1_num = self.find_anum(a1)
# qlearning的更新公式TD(0)
q_target = r + self.gamma * self.qvalue[s_next, a1_num]
# 利用td方法更新动作值函数
self.qvalue[s, a_num] = self.qvalue[s, a_num] + alpha * (q_target - self.qvalue[s, a_num])
s = s_next
#行为策略
a = self.epsilon_greedy_policy(self.qvalue, s, epsilon)
count += 1
# print(r)
return self.qvalue
def greedy_test(self):
s = 0
s_sample = []
done = False
flag = 0
step_num = 0
while False == done and step_num < 30:
a = self.greedy_policy(self.qvalue, s)
# 与环境交互
s_next, r, done = self.yuanyang.transform(s, a)
s_sample.append(s)
s = s_next
step_num += 1
if s == 9:
flag = 1
if s == 9 and step_num<21:
flag = 2
return flag
if __name__=="__main__":
yuanyang = YuanYangEnv()
brain = TD_RL(yuanyang)
# qvalue1 = brain.sarsa(num_iter =5000, alpha = 0.1, epsilon = 0.8)
qvalue2=brain.qlearning(num_iter=10000, alpha=0.1, epsilon=0.1)
#打印学到的值函数
yuanyang.action_value = qvalue2
##########################################
# 测试学到的策略
flag = 1
s = 0
# print(policy_value.pi)
step_num = 0
path = []
# 将最优路径打印出来
while flag:
# 渲染路径点
path.append(s)
yuanyang.path = path
a = brain.greedy_policy(qvalue2, s)
# a = agent.bolzman_policy(qvalue,s,0.1)
print('%d->%s\t' % (s, a), qvalue2[s, 0], qvalue2[s, 1], qvalue2[s, 2], qvalue2[s, 3])
yuanyang.bird_male_position = yuanyang.state_to_position(s)
yuanyang.render()
time.sleep(0.25)
step_num += 1
s_, r, t = yuanyang.transform(s, a)
if t == True or step_num > 30:
flag = 0
s = s_
# 渲染最后的路径点
yuanyang.bird_male_position = yuanyang.state_to_position(s)
path.append(s)
yuanyang.render()
while True:
yuanyang.render()
load.py和背景图片参考前几章。
















![[GXYCTF2019]BabySQli](https://i-blog.csdnimg.cn/direct/11f25fb58e0640aba1c159ac3b569025.png)
