文章目录
- 启动数据库
- 查看数据库节点启动成功状态
- 关闭数据库
- 使用cqlsh工具
- 常见命令
- 查看集群信息
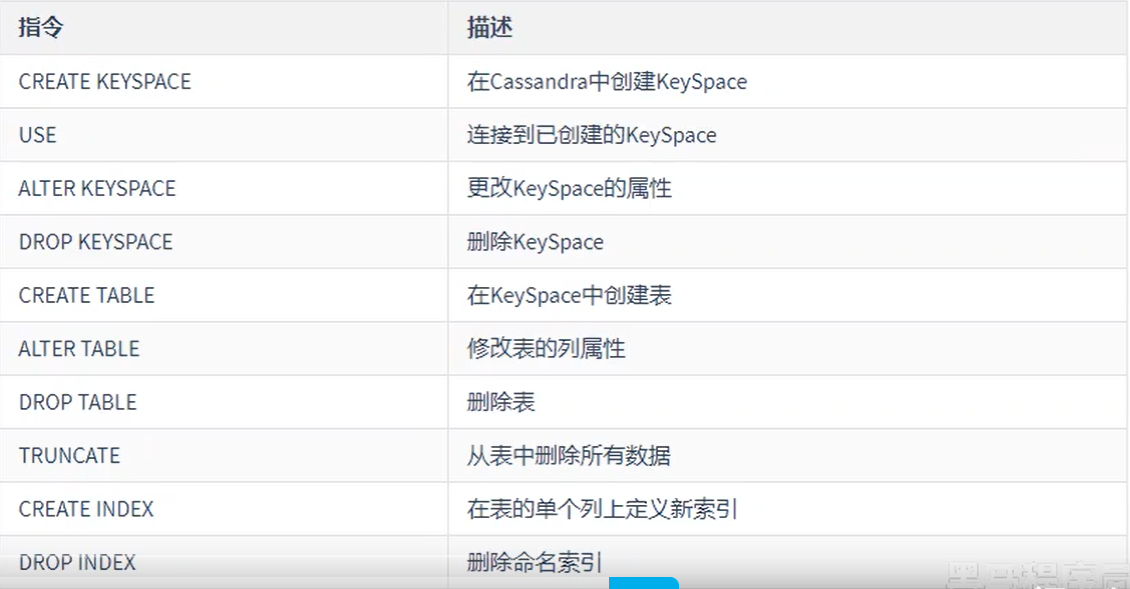
- 数据定义命令
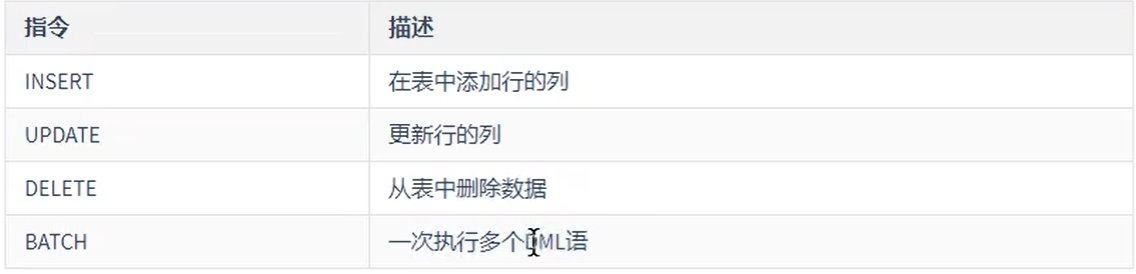
- 数据操作命令
- 操作健空间
- 创建Keyspace
- 连接健空间
- 删除健空间
- 创建表
- 主键
- 表修改
- 添加列
- 删除列
- 删除表
- 清空表
- 添加数据
- 数据过期时间
- 查询数据
- 更新数据
- 更新简单数据
- 更新set类型数据
- 添加一个元素
- 删除一个元素
- 删除所有元素
- 更新list类型数据
- 使用UPDATA命令向list插入值
- 在list前面插入值
- 在list后面插入值
- 更新map类型数据
- 使用insert和update命令
- 删除元素
- 可以用DELETE 和 UPDATE 删除Map类型中的数据
- 删除行
启动数据库
[zdaxctid@node3 bin]$ pwd
/home/database/apache-cassandra-3.11.7/bin
#启动数据库
[zdaxctid@node3 bin]$ ./cassandra
成功标志:
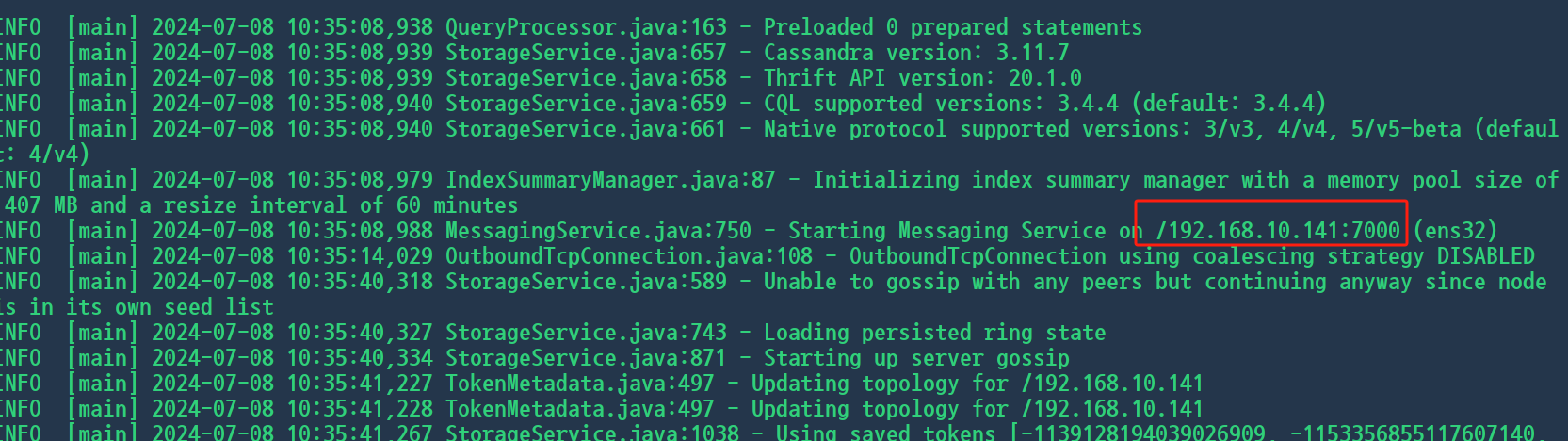
查看数据库节点启动成功状态
[zdaxctid@node3 bin]$ ./nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
DN 192.168.10.11 ? 256 100.0% 3240fa95-cc32-40f9-8c5d-ff53b9b86adc rack1
UN 192.168.10.141 405.56 KiB 256 100.0% 468c9c1c-a1d4-4eda-a59a-31793df44d10 rack1
[zdaxctid@node3 bin]$

关闭数据库
杀掉数据库进程相关的pid号即可!!
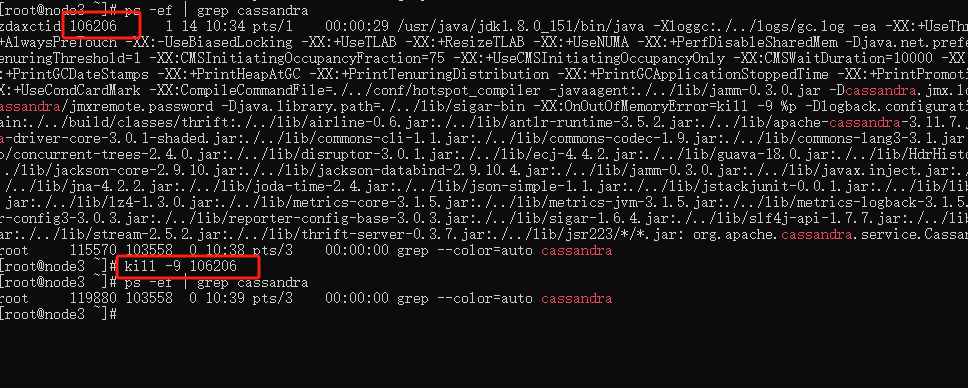
[root@node3 ~]# kill -9 106206
[root@node3 ~]# ps -ef | grep cassandra
root 119880 103558 0 10:39 pts/3 00:00:00 grep --color=auto cassandra
[root@node3 ~]#
使用cqlsh工具

[zdaxctid@node3 bin]$ ./cqlsh 192.168.10.141 9042
Connected to Test Cluster at 192.168.10.141:9042.
[cqlsh 5.0.1 | Cassandra 3.11.7 | CQL spec 3.4.4 | Native protocol v3]
Use HELP for help.
cqlsh>
常见命令
查看集群信息
cqlsh> describe cluster;
Cluster: Test Cluster
Partitioner: Murmur3Partitioner
cqlsh> DESCRIBE tables;
Keyspace system_schema
----------------------
tables triggers views keyspaces dropped_columns
functions aggregates indexes types columns
Keyspace system_auth
--------------------
resource_role_permissons_index role_permissions role_members roles
Keyspace system
---------------
available_ranges peers batchlog transferred_ranges
batches compaction_history size_estimates hints
prepared_statements sstable_activity built_views
"IndexInfo" peer_events range_xfers
views_builds_in_progress paxos local
Keyspace system_distributed
---------------------------
repair_history view_build_status parent_repair_history
Keyspace system_traces
----------------------
events sessions
Keyspace flowmonitoringsystem
-----------------------------
auth_28_tcp_alarm_value auth_28_tcp_flow auth_28_node
auth_28_alarm_config auth_28_business_number_index user
auth_28_server auth_ip_alarm_config
auth_28_link auth_28_thrice_hand_shake
auth_28_second auth_28_second_alarm_history
auth_28_mode_config auth_28_tcp_flow_alarm_history
auth_28_second_history ywzd_user
cqlsh> use system_traces;
Invalid syntax at line 1, char 18
use system_traces;
^
cqlsh> use system_traces;
cqlsh:system_traces> DESCRIBE tables
events sessions
cqlsh:system_traces> describe sessions
CREATE TABLE system_traces.sessions (
session_id uuid PRIMARY KEY,
client inet,
command text,
coordinator inet,
coordinator_port int,
duration int,
parameters map<text, text>,
request text,
started_at timestamp
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = 'tracing sessions'
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.0
AND default_time_to_live = 0
AND gc_grace_seconds = 0
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 3600000
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh:system_traces> show
Improper show command.
cqlsh:system_traces> SHOW
Improper SHOW command.
cqlsh:system_traces> quit;
[zdaxctid@node3 bin]$ ./cqlsh 192.168.10.141 9042
Connected to Test Cluster at 192.168.10.141:9042.
[cqlsh 5.0.1 | Cassandra 3.11.7 | CQL spec 3.4.4 | Native protocol v3]
Use HELP for help.
cqlsh> show
Improper show command.
cqlsh> showkey
...
... ;
SyntaxException: line 1:0 no viable alternative at input 'showkey' ([showkey]...)
cqlsh>
cqlsh> show host
Connected to Test Cluster at 192.168.10.141:9042.
cqlsh> show session
Improper show command.
cqlsh> show version
[cqlsh 5.0.1 | Cassandra 3.11.7 | CQL spec 3.4.4 | Native protocol v3]
cqlsh>
数据定义命令
数据操作命令
操作健空间
创建Keyspace
语法
cqlsh> create keyspace school with replication={'class':'SimpleStrategy','replication_factor':3};
school system_auth system_distributed flowmonitoringsystem
system_schema system system_traces
cqlsh> describe school;
CREATE KEYSPACE school WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '3'} AND durable_writes = true;
cqlsh>
连接健空间
cqlsh> use school;
cqlsh:school> alter keyspace school with replication={'class':'SimpleStrategy','replication_factor':1};
删除健空间
cqlsh:school> drop keyspace school;
cqlsh:school>
cqlsh:school>
cqlsh:school> describe keyspaces;
system_schema system system_traces
system_auth system_distributed flowmonitoringsystem
cqlsh:school>
创建表
创建语句类似于sql语句!
create table student(
id int primary key,
name text,
age int,
gender tinyint,
address text,
interest set<text>,
phone list<text>,
education map<text,text>
);
cqlsh:test> create table student(
... id int primary key,
... name text,
... age int,
... gender tinyint,
... address text,
... interest set<text>,
... phone list<text>,
... education map<text,text>
... );
Warning: schema version mismatch detected; check the schema versions of your nodes in system.local and system.peers.
cqlsh:test> describe test
CREATE KEYSPACE test WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '1'} AND durable_writes = true;
CREATE TABLE test.student (
id int PRIMARY KEY,
address text,
age int,
education map<text, text>,
gender tinyint,
interest set<text>,
name text,
phone list<text>
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh:test> describe tables;
student
cqlsh:test>
主键
create table testTab(
key_part_one int,
key_part_two int,
key_clust_one int,
key_clust_two int,
key_clust_three uuid,
name text,
primary key((key_part_one,key_part_two),key_clust_one,key_clust_two,key_clust_three)
);
cqlsh:test> use test01;
cqlsh:test01> create table testTab(
... key_part_one int,
... key_part_two int,
... key_clust_one int,
... key_clust_two int,
... key_clust_three uuid,
... name text,
... primary key((key_part_one,key_part_two),key_clust_one,key_clust_two,key_clust_three)
... );
Warning: schema version mismatch detected; check the schema versions of your nodes in system.local and system.peers.
cqlsh:test01>
cqlsh:test01>
cqlsh:test01> describe tables;
testtab
cqlsh:test01> select * from testab
... ;
InvalidRequest: Error from server: code=2200 [Invalid query] message="unconfigured table testab"
cqlsh:test01> select * from testtab;
key_part_one | key_part_two | key_clust_one | key_clust_two | key_clust_three | name
--------------+--------------+---------------+---------------+-----------------+------
(0 rows)
cqlsh:test01>
表修改
添加列
cqlsh:test> alter table testtab add email text;
cqlsh:test> describe keyspaces;
system_schema system test test01
system_auth system_distributed system_traces flowmonitoringsystem
cqlsh:test> describe tables;
testtab student
cqlsh:test> alter table testtab add email text;
Warning: schema version mismatch detected; check the schema versions of your nodes in system.local and system.peers.
cqlsh:test>
cqlsh:test> describe testtab;
CREATE TABLE test.testtab (
key_part_one int,
key_part_two int,
key_clust_one int,
key_clust_two int,
key_clust_three uuid,
email text,
name text,
PRIMARY KEY ((key_part_one, key_part_two), key_clust_one, key_clust_two, key_clust_three)
) WITH CLUSTERING ORDER BY (key_clust_one ASC, key_clust_two ASC, key_clust_three ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh:test>
删除列
cqlsh:test> alter table testtab drop email;
cqlsh:test> alter table testtab drop email;
Warning: schema version mismatch detected; check the schema versions of your nodes in system.local and system.peers.
cqlsh:test> describe testtab;
CREATE TABLE test.testtab (
key_part_one int,
key_part_two int,
key_clust_one int,
key_clust_two int,
key_clust_three uuid,
name text,
PRIMARY KEY ((key_part_one, key_part_two), key_clust_one, key_clust_two, key_clust_three)
) WITH CLUSTERING ORDER BY (key_clust_one ASC, key_clust_two ASC, key_clust_three ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh:test>
删除表
cqlsh:test> drop table testtab;
cqlsh:test> drop table testtab;
Warning: schema version mismatch detected; check the schema versions of your nodes in system.local and system.peers.
cqlsh:test>
cqlsh:test> describe tables;
student
cqlsh:test> select * from testtab;
InvalidRequest: Error from server: code=2200 [Invalid query] message="unconfigured table testtab"
cqlsh:test>
清空表
cqlsh:test> truncate student;
添加数据
INSERT INTO student (id,address,age,gender,name,interest, phone,education) VALUES (1011,'中山路21号',16,1,'Tom',{'游泳', '跑步'},['010-88888888','13888888888'],{'小学' : '城市第一小学', '中学' : '城市第一中学'})
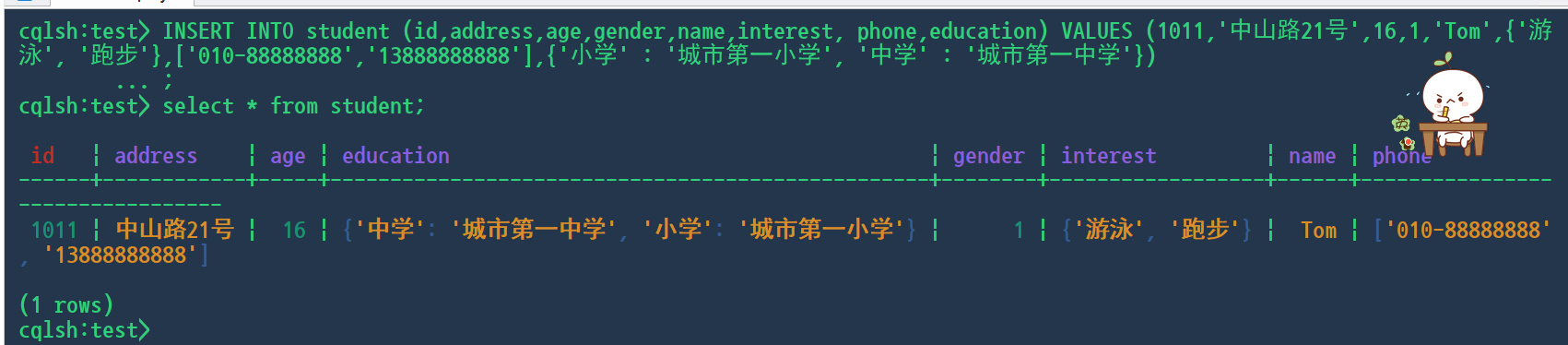
INSERT INTO student (id,address,age,gender,name,interest, phone,education) VALUES (1012,'朝阳路19号',17,2,'Jerry',{'看书', '电影'},['020-66666666','13666666666'],{'小学' :'城市第五小学','中学':'城市第六中学'});

数据过期时间
using ttl 30
数据30秒以后清空!
INSERT INTO student (id,address,age,gender,name,interest, phone,education) VALUES (1013,'朝阳路19号',17,2,'Linghu',{'看书', '电影'},['020-66666666','13666666666'],{'小学' :'城市第五小学','中学':'城市第六中学'})using ttl 30;

查询数据
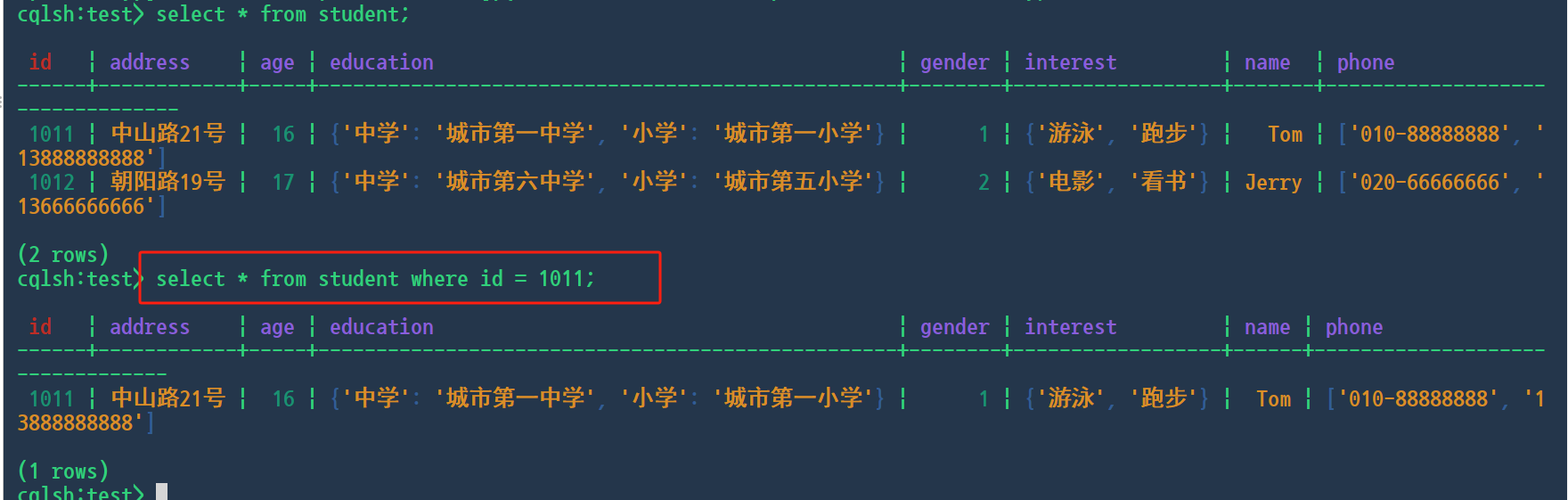
cqlsh:test> select * from student where id = 1011;
更新数据
更新简单数据
更新表中的数据:
cqlsh:test> update student set gender = 0 where id = 1011;

更新set类型数据
在student表中,interest列是set类型
添加一个元素
update和+
cqlsh:test> update student set interest = interest+{'打太极'} where id = 1011;
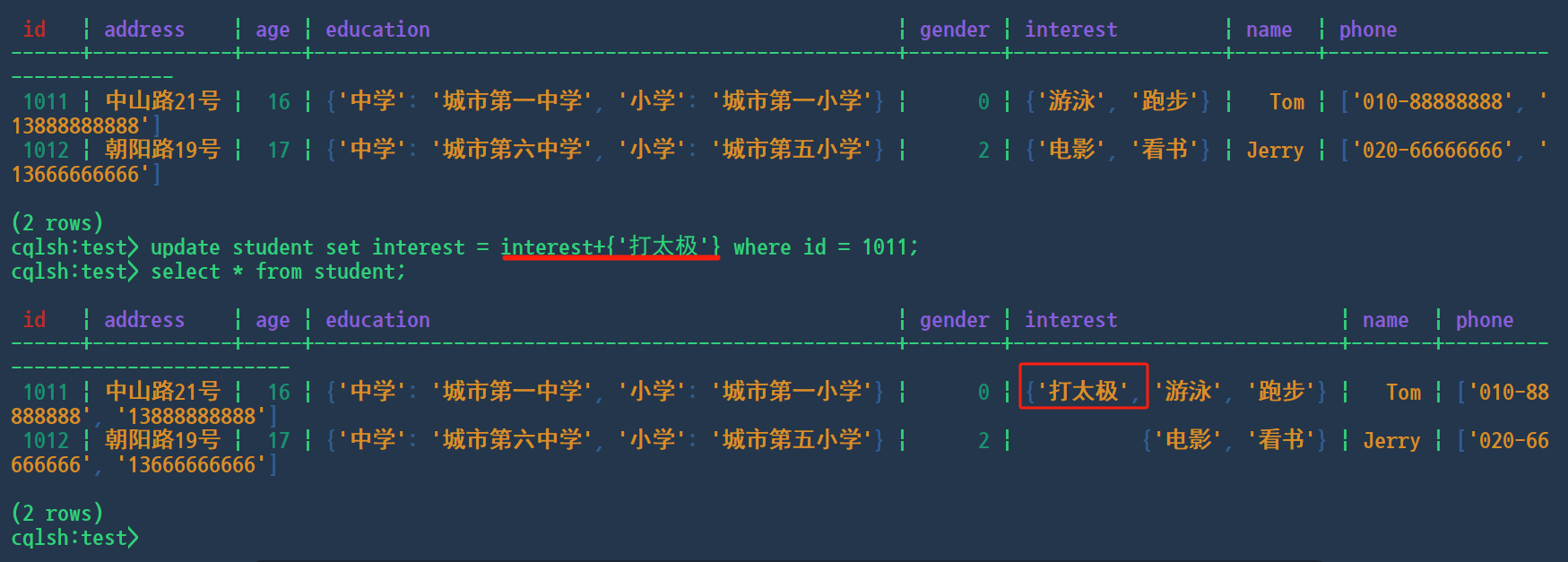
删除一个元素
update和-
cqlsh:test> update student set interest = interest-{'打太极'} where id = 1011;
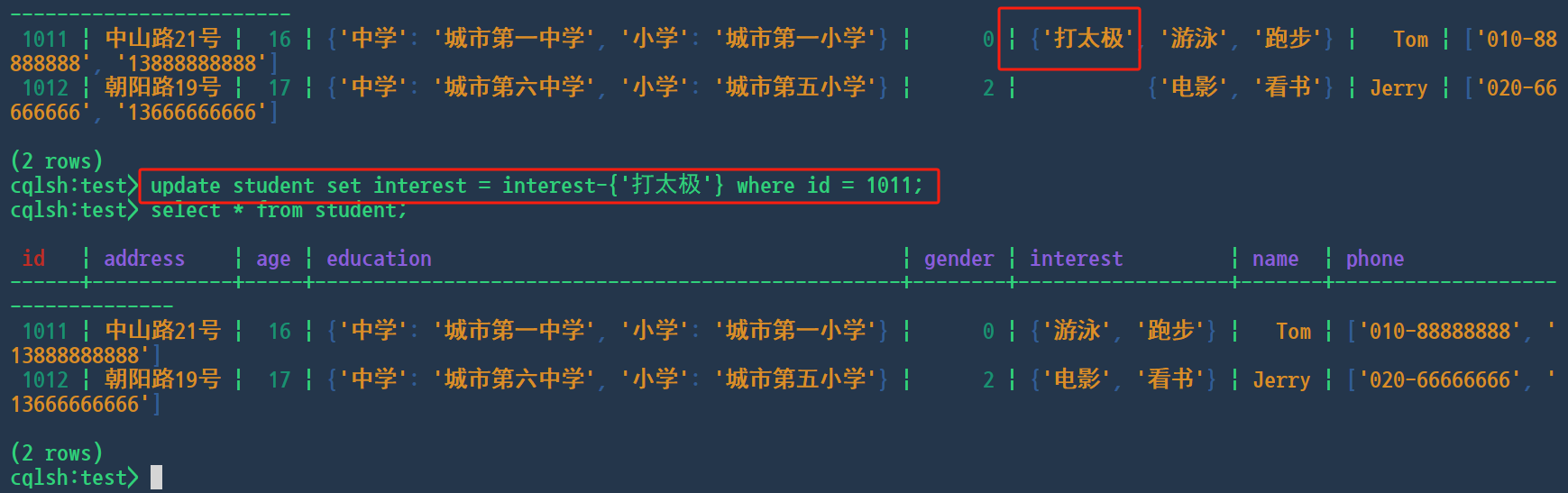
删除所有元素
update或者delete命令
UPDATE student SET interest = {} WHERE student_id = 1012;
或
DELETE interest FROM student WHERE student_id = 1012;
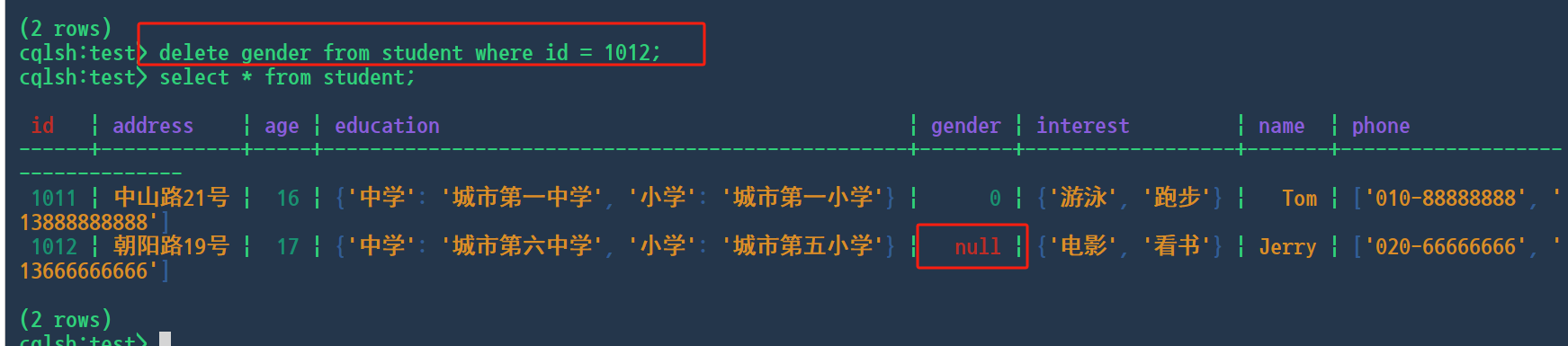
更新list类型数据
在student中phone就是list类型
使用UPDATA命令向list插入值
cqlsh:test> UPDATE student SET phone = [‘020-66666666’, ‘13666666666’,‘1714873054’] WHERE id = 1012;
在list前面插入值
cqlsh:test> UPDATE student SET phone = [ ‘030-55555555’ ] + phone WHERE id = 1012;
在list后面插入值
cqlsh:test> UPDATE student SET phone = phone + [ ‘040-33333333’ ] WHERE id = 1012;
#使用UPDATA命令向list插入值
cqlsh:test> UPDATE student SET phone = ['020-66666666', '13666666666','1714873054'] WHERE id = 1012;
cqlsh:test> select * from student;
id | address | age | education | gender | interest | name | phone
------+------------+-----+--------------------------------------------------+--------+------------------+-------+-----------------------------------------------
1011 | 中山路21号 | 16 | {'中学': '城市第一中学', '小学': '城市第一小学'} | 0 | {'游泳', '跑步'} | Tom | ['010-88888888', '13888888888']
1012 | 朝阳路19号 | 17 | {'中学': '城市第六中学', '小学': '城市第五小学'} | null | {'电影', '看书'} | Jerry | ['020-66666666', '13666666666', '1714873054']
(2 rows)
#在list前面插入值
cqlsh:test> UPDATE student SET phone = [ '030-55555555' ] + phone WHERE id = 1012;
cqlsh:test> select * from student;
id | address | age | education | gender | interest | name | phone
------+------------+-----+--------------------------------------------------+--------+------------------+-------+---------------------------------------------------------------
1011 | 中山路21号 | 16 | {'中学': '城市第一中学', '小学': '城市第一小学'} | 0 | {'游泳', '跑步'} | Tom | ['010-88888888', '13888888888']
1012 | 朝阳路19号 | 17 | {'中学': '城市第六中学', '小学': '城市第五小学'} | null | {'电影', '看书'} | Jerry | ['030-55555555', '020-66666666', '13666666666', '1714873054']
(2 rows)
#在list后面插入值
cqlsh:test> UPDATE student SET phone = phone + [ '040-33333333' ] WHERE id = 1012;
cqlsh:test> select * from student;
id | address | age | education | gender | interest | name | phone
------+------------+-----+--------------------------------------------------+--------+------------------+-------+-------------------------------------------------------------------------------
1011 | 中山路21号 | 16 | {'中学': '城市第一中学', '小学': '城市第一小学'} | 0 | {'游泳', '跑步'} | Tom | ['010-88888888', '13888888888']
1012 | 朝阳路19号 | 17 | {'中学': '城市第六中学', '小学': '城市第五小学'} | null | {'电影', '看书'} | Jerry | ['030-55555555', '020-66666666', '13666666666', '1714873054', '040-33333333']
(2 rows)
cqlsh:test>
更新map类型数据
map输出顺序取决于map类型。
使用insert和update命令
cqlsh:test> update student set education = {'中学':'桐梓一中','小学':'南天门'} where id = 1012;
cqlsh:test> select * from student;
id | address | age | education | gender | interest | name | phone
------+------------+-----+--------------------------------------------------+--------+------------------+-------+-------------------------------------------------------------------------------
1011 | 中山路21号 | 16 | {'中学': '城市第一中学', '小学': '城市第一小学'} | 0 | {'游泳', '跑步'} | Tom | ['010-88888888', '13888888888']
1012 | 朝阳路19号 | 17 | {'中学': '桐梓一中', '小学': '南天门'} | null | {'电影', '看书'} | Jerry | ['030-55555555', '020-66666666', '13666666666', '1714873054', '040-33333333']
(2 rows)
cqlsh:test>
删除元素
可以用DELETE 和 UPDATE 删除Map类型中的数据
使用DELETE删除数据可以用DELETE 和 UPDATE 删除Map类型中的数据
使用DELETE删除数据
cqlsh:test> delete education['中学'] from student where id = 1012;
cqlsh:test> select * from student;
id | address | age | education | gender | interest | name | phone
------+------------+-----+--------------------------------------------------+--------+------------------+-------+-------------------------------------------------------------------------------
1011 | 中山路21号 | 16 | {'中学': '城市第一中学', '小学': '城市第一小学'} | 0 | {'游泳', '跑步'} | Tom | ['010-88888888', '13888888888']
1012 | 朝阳路19号 | 17 | {'小学': '南天门'} | null | {'电影', '看书'} | Jerry | ['030-55555555', '020-66666666', '13666666666', '1714873054', '040-33333333']
(2 rows)
cqlsh:test>
删除行
删除student中student_id=1012 的数据
cqlsh:test> delete from student where id = 1012;
cqlsh:test> select * from student;
id | address | age | education | gender | interest | name | phone
------+------------+-----+--------------------------------------------------+--------+------------------+------+---------------------------------
1011 | 中山路21号 | 16 | {'中学': '城市第一中学', '小学': '城市第一小学'} | 0 | {'游泳', '跑步'} | Tom | ['010-88888888', '13888888888']
(1 rows)
cqlsh:test>
create table authtype(
id int primary key,
auth_type text,
foreing key (auth_type) references hostinfo (id)
);
delete from student where id = 1012;
cqlsh:test> select * from student;
id | address | age | education | gender | interest | name | phone
------±-----------±----±-------------------------------------------------±-------±-----------------±-----±--------------------------------
1011 | 中山路21号 | 16 | {‘中学’: ‘城市第一中学’, ‘小学’: ‘城市第一小学’} | 0 | {‘游泳’, ‘跑步’} | Tom | [‘010-88888888’, ‘13888888888’]
(1 rows)
cqlsh:test>





![[Spring] Spring Web MVC基础理论](https://i-blog.csdnimg.cn/direct/e25efd1e5b60426dbaa51f3db4ad9d59.png)