一直以来,矩阵乘法(MatMul)稳居神经网络操作的主导地位,其中很大原因归结为 GPU 专门针对 MatMul 操作进行了优化。这种优化使得 AlexNet 在 ILSVRC2012 挑战赛中一举胜出,成为深度学习崛起的历史性标志。
在这当中,有个值得注意的点是,AlexNet 利用 GPU 来提高训练速度,超越了 CPU 的能力,至此,GPU 的加入使得深度学习仿佛赢得了「硬件彩票」。
尽管 MatMul 在深度学习中很流行,但不得不承认的是它占据了计算开销的主要部分,主要表现为 MatMul 在训练和推理阶段消耗大部分执行时间和内存访问。
目前为止,研究者已经开始借助其他更简单的操作替代 MatMul,主要有两种。
- 第一种策略是使用初等运算代替 MatMul,例如,在卷积神经网络 (CNN) 中,用有符号加法代替乘法;
- 第二种方法是使用二值或三值化量化,将 MatMul 值在累加之前要么翻转要么清零。比如脉冲神经网络 (SNN) 使用二值激活,而二值化网络 BNN 使用量化权重。
在语言建模方面,BitNet 等技术的出现表明量化的可扩展性, 但这种方式仍然保留了昂贵的矩阵 - 矩阵相乘(MMM)的自注意力机制。研究者尝试过多种努力,但 MatMul 操作在 GPU 上仍然是资源密集型的。
既然 MatMul 占据了 LLM 整体计算成本,且随着 LLM 向更大的嵌入维度和上下文长度扩展时,这种成本只会增加。这引发了一个问题:是否有可能完全从 LLM 中消除 MatMul 操作?

在这项工作中,来自加州大学圣克鲁兹分校等机构的研究者证明了 MatMul 操作可以完全从 LLM 中消除,同时在十亿参数尺度下保持强大的性能。

- 论文地址:arxiv.org/pdf/2406.02…
- 项目地址:github.com/ridgerchu/m…
- 论文标题:Scalable MatMul-free Language Modeling
实验表明,该研究提出的 MatMul-free 模型达到了与最先进的 Transformer 相当的性能,后者在推理期间需要更多的内存,规模至少为 2.7B 参数。
此外,论文还研究了扩展定律,发现随着模型规模的增加,MatMul-free 模型与全精度 Transformer 之间的性能差距逐渐缩小。
研究者还提供了一种高效的 GPU 模型实现方式,在训练期间相比未优化的基线模型减少了多达 61% 的内存使用。通过在推理时利用优化的内核,模型内存消耗可以比未优化的模型减少超过 10 倍。
最后,研究者在 FPGA 上构建了一个自定义硬件解决方案,他们以 13W 的功耗处理了十亿参数规模的模型,超出了人类可读的吞吐量,使 LLM 更接近大脑般的效率。
网友看后不禁感叹道:看来有大事要发生了。

不过,受到计算资源的限制,研究者还没有在非常大的模型(如参数大于100B的模型)上测试MatMul-free模型的有效性,因此其实战效果还有待观察。
方法介绍
该研究构建了首个可扩展的MatMul-free语言模型 (Matmul-free LM),通过在密集层中使用加法操作以及在自注意力类函数中使用元素级 Hadamard 乘积完成。
具体来说,三值权重消除了密集层中的 MatMul,类似于 BNN。为了从自注意力中移除 MatMul,该研究优化了门控循环单元 (GRU) ,使其仅依赖于元素级乘积,并表明该模型可与最先进的 Transformer 相媲美,同时消除了所有 MatMul 运算。
论文详细介绍 MatMul-free 语言模型(LM)的各个组成部分。
具有三值权重的 MatMul-free 密集层
在标准密集层中,输入和权重矩阵之间的 MatMul 可以表示为:

为了避免使用基于 MatMul 的密集层,该研究采用 BitNet 来替换包含 MatMul 的密集层,即使用 BitLinear 模块,这些模块使用三值权重将 MatMul 操作转换为纯加法操作。当使用三值权重时,权重矩阵 W 中的元素被限制在集合 {-1, 0, +1} 中。带有三值权重的 MatMul 可以表达为:

由于三值化权重 只能从 {−1, 0, +1} 中取值,因而 MatMul 中的乘法运算可以用简单的加法或减法运算代替:
只能从 {−1, 0, +1} 中取值,因而 MatMul 中的乘法运算可以用简单的加法或减法运算代替:

因此,三值化 MatMul 可以写成如下:

算法 1 为量化融合 RMSNorm 和 BitLinear 算法的流程图:

MatMul-free 语言模型架构
研究人员采用了 Metaformer 的观点,该观点认为 Transformer 由两部分组成:token mixer(用于混合时间信息,即自注意力机制)和 channel mixer(用于混合嵌入 / 空间信息,即前馈网络,门控线性单元 GLU )。该架构的高级概览如图 2 所示。

自注意力机制是现代语言模型中最常用的 token mixer,它依赖于三个矩阵 Q、K 和 V 之间的矩阵乘法。为了将这些操作转换为加法,研究人员至少对两个矩阵进行二值化或三值化处理。
假设所有密集层的权重都是三值的,他们将 Q 和 K 量化,得到一个三值的注意力图,从而消除自注意力中的乘法操作。但是,以这种方式训练的模型无法成功收敛。一个可能的解释是,激活值包含对性能至关重要但难以有效量化的异常值。
为了解决这一挑战,研究人员探索了不依赖于矩阵乘法的替代方法来混合 token。
通过采用结合了逐元素操作和累积的三值 RNN,可以构建一个MatMul-free 的 token mixer。在各种 RNN 架构中,GRU 因其简单高效而著称,它在比长短期记忆网络(LSTM)使用更少的门控单元和结构更简单的情况下,实现了类似的性能。因此,研究人员选择 GRU 作为构建 MatMul-free token mixer 的基础。
为了实现 MatMul-free 的通道混合,研究人员采用了门控线性单元(GLU),它在许多现代 LLM 中得到了广泛应用,包括 Llama 、Mistral 和 RWKV。一个适应了 BitLinear 的 GLU 版本可以表达如下:

这里的通道混合器仅由密集层组成,这些层已被三值化累积操作所替代。通过在 BitLinear 模块中使用三值权重,研究人员可以消除对昂贵 MatMul 的需求,这样不仅使通道混合器在计算上更加高效,同时还保持了其在跨通道混合信息方面的有效性。
实验
该研究的重点是在中等规模的语言建模任务上测试 MatMul-free 的语言模型。研究人员将两种变体的 MatMul-free 语言模型与复现的高级 Transformer 架构(基于 Llama-2 的 Transformer++)在三个模型大小上进行比较:370M、13 亿和 27 亿参数。
为了公平比较,所有模型都在 SlimPajama 数据集上进行了预训练,其中 370M 模型训练了 150 亿个 token,而 13 亿和 27 亿模型各训练了 1000 亿个 token。
模型训练使用了 8 个 NVIDIA H100 GPU。370M 模型的训练时间大约为 5 小时,13 亿模型为 84 小时,27 亿模型为 173 小时。
MatMul-free 语言模型的扩展规律
研究团队评估了MatMul-free 语言模型和 Transformer++ 在 370M、13 亿和 27 亿参数模型上的扩展规律,如图 3 所示。
为便于比较,MatMul-free LM 和 Transformer++ 中的每个操作都被同等对待。但请注意,Transformer++ 中的所有权重和激活都是 BF16 格式,而MatMul-free 语言模型中的 BitLinear 层使用三元参数,激活为 BF16。因此,MatMul-free 语言模型的平均运算成本要低于 Transformer++。

有意思的是,与 Transformer++ 相比,MatMul-free 语言模型的扩展投影显示出更陡峭的下降趋势,这表明MatMul-free语言模型在利用额外计算资源提高性能方面更为高效。
因此,MatMul-free 语言模型的扩展曲线预计将在大约 10^23 次浮点运算(FLOPs)处与 Transformer++ 的扩展曲线相交。这个计算规模大致相当于训练 Llama-3 8B(使用 1.5 万亿个 token 训练)和 Llama-2 70B(使用 2 万亿个 token 训练)所需的 FLOPs,这表明MatMul-free 语言模型不仅在效率上胜出,而且扩展时在损失方面也可能表现更好。
下游任务
学习率是语言模型训练中一个关键的超参数,当模型处于三元 / 二元权重状态时,对学习率变得更加敏感。为了确定最优学习率,研究人员使用 370M 模型,批量大小为 50k 个 token,在 1.5e−3 到 3e−2 的范围内进行了搜索。这次搜索的结果如图 4 © 所示。
结果显示,当学习率从 1.5e−3 增加到 1e−2 时,最终训练损失单调递减。只有当学习率超过 2e−2 时,模型才表现出不稳定。这一发现表明,以前使用三元权重的作品,如使用 1.5e−3 学习率的 BitNet,可能不是最优的,更高的学习率有可能带来更好的性能。
这些发现与 Deepseek LLM 的观察结果一致,后者发现传统大型语言模型(LLMs)的最佳学习率实际上比大多数 LLM 训练设置中通常报告的值要大。
有趣的是,研究人员还观察到,与使用较小学习率训练的模型相比,训练初期使用较大学习率训练的模型,在训练后期的阶段训练损失下降得更快。

研究人员根据训练时间和内存使用情况评估了他们提出的融合型 BitLinear 和传统型 BitLinear 实现,如图 4 (a-b) 所示。
实验表明,他们的融合操作器在更大的批量大小下,能够带来更快的训练速度,并减少内存消耗。当批量大小为 2 的 8 次方时,1.3B 参数模型的训练速度从每次迭代 1.52 秒提高到 1.21 秒,比 Vanilla 实现快了 25.6%。
此外,内存消耗从 82GB 减少到 32GB,内存使用减少了 61.0%。随着批量大小的增加,融合实现的性能显著提高,允许同时处理更多的样本,并减少总迭代次数。
图 4 (d) 展示了不同模型大小下,所提出的MatMul-free语言模型与 Transformer++ 在 GPU 推理内存消耗和延迟方面的比较。
在MatMul-free语言模型中,研究人员采用 BitBLAS 进行加速,以进一步提高效率。评估是在批量大小为 1,序列长度为 2048 的情况下进行的。
MatMul-free语言模型在所有模型大小上都显示出比 Transformer++ 更低的内存使用和延迟。
对于单层,MatMul-free 语言模型只需要 0.12 GB 的 GPU 内存,并且实现了 3.79 毫秒的延迟,而 Transformer++ 消耗了 0.21 GB 的内存,并且有 13.87 毫秒的延迟。随着模型大小的增加,MatMul-free 语言模型的内存和延迟优势变得更加明显。
值得注意的是,对于大于 2.7B 的模型大小,结果是使用随机初始化的权重进行模拟的。对于最大的 13B 参数模型,MatMul-free 语言模型仅使用 4.19 GB 的 GPU 内存,并且有 695.48 毫秒的延迟,而 Transformer++ 需要 48.50 GB 的内存,并表现出 3183.10 毫秒的延迟。
这些结果突出了MatMul-free语言模型所实现的效率增益,使其成为大规模语言建模任务的有希望的方法,特别是在推理期间。
为了测试MatMul-free语言模型功耗和有效性,研究人员使用 SystemVerilog 创建了一个 FPGA 加速器。概览如图 5 所示。

表 2 显示了单块(N = 1)单核实现的资源利用、功耗和性能。

通过使用完整的 512 位 DDR4 接口,并对占据核心处理时间 99% 的 TMATMUL 功能单元进行并行化,预计在保持相同时钟速率的情况下,无需额外优化或流水线化,可以实现大约 64 倍的进一步加速,如表 3 所示。

读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
资源分享

大模型AGI学习包


资料目录
- 成长路线图&学习规划
- 配套视频教程
- 实战LLM
- 人工智能比赛资料
- AI人工智能必读书单
- 面试题合集
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。
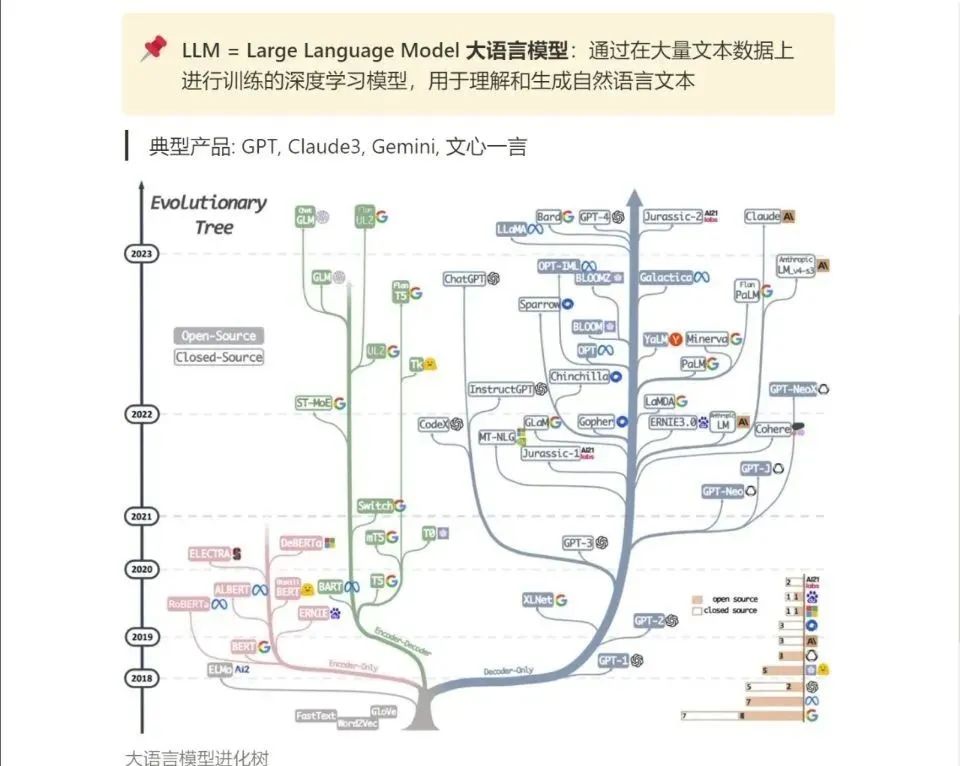
3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!



















