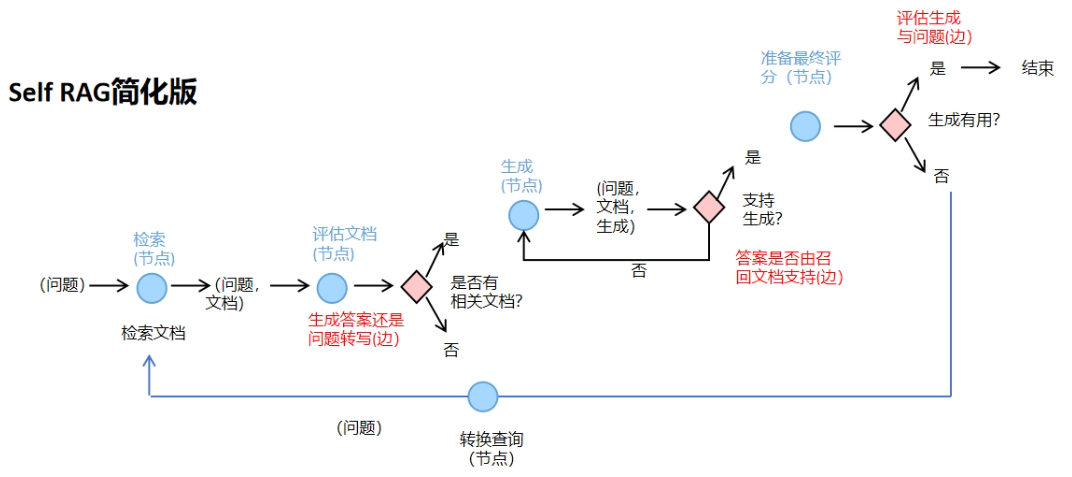
Service简介
首先Nifi中的Controller Service 和我们MVC概念中的Controller Service不是一个概念,Nifi中的Controller Service更像是和Processor同级的一个概念,它和Processor在我个人的使用经验来理解的话就是它是预制好的各种服务,可以被Processor引用或者支撑Processor,例如一个SQL读取的Processor,它得需要JDBC的连接,才能访问数据库。这里Controller Service 就可以是一个JDBC的连接池服务。
同理,Controller Service 也是支持扩展的,可以像自定义开发Processor一样,根据自己的业务需求,进行自定义的Controller Service 开发。
当我们使用某些依赖Service的组件(Processor)时,在配置中会出现选择Service或者创建新的Service的情况,这里的Service即是Nifi的Controller Service,一旦创建新的,则会生成一个以Group为范围的 “全局” Service对象,这时,再有依赖同类型Service的Processor时,可以直接选中:


Controller Service的配置
单独查看Controller Service 可以从面板空白处,右键Configure来看,如下图:

这是一个JDBC的连接池Service,它包含的属性有名称、类型、简介、启用状态、操作;从操作中可以看到配置该Service需要填写基本的各类属性;其中,Service是有启停状态的,如果想修改Service的属性内容,必须先保证该Service是停用状态,然后点击配置标识,则进入配置页面,它的配置和Processor的差不多,通过页签区别,共有三个页签:SETTING(基础属性)、PROPERTIES(使用属性)、COMMENT(页签):
SETTING 基础属性

基础属性,包含左侧的名称,名称可以进行更改,右侧包含引用此Service的Processor 列表
PROPERTIES 使用属性

核心的业务配置,此标签页的配置项根据不同的Service,配置内容不一致,具体的配置项以及使用,可以参考官方的文档;这里的是JDBC的连接池,所以基本需要连接数据库所需的URL、数据库的账号密码、数据库的驱动类名称、驱动类的依赖 jar包路径 ,这里不少Service可能都需要第三方的jar包依赖才可以使用,长期使用或生产环境下,建议将所有jar资源集中放在统一路径下。
COMMENT 页签

一个提供Service使用说明的页签,可根据自己实际需求,补充使用Service的用法以及描述
Service 的使用范围
在Nifi的基本使用中的Group的使用介绍,Group同时也对Services起作用,如果我们在一个Nifi的最外层的平面上 新增Controller Service,那么这些Service的作用域是整个Nifi的任何位置,如果我们在某个Group内创建Controller Service, 那么这个Controller Service 仅在Group范围内可以被引用,Nifi的这种机制也是方便Service的使用和维护

全局参数配置
类似于 数据库连接池、Kafka、Redis等各种组件的连接池、客户端Client的Service在实际的使用中会非常多,由此配置的Service也会非常多,于是就会产生很多次的反复配置URL、账号这一系列重复的内容,由于Nifi的特性,这些Service又和组件(Processor)一样,四散在各处,这就使得维护和运维管理变得很繁琐,调试、调整、查看的时候,要不停的各个group来回跳转、调整不同的Service的Configure;为应对此类问题,Nifi 提供了全局配置的机制来弥补。
使用变量前:

这里的 URL、Driver Class Name、Database User在实际生产环境中,可能都是固定的数据库和固定的服务,几乎不需要变得,可能只需要配置一遍就好,不需要每次创建Service都写一遍;所以可以这里可以使用上下文变量(Parameter Context)
首先,打开Parameter Context,创新一组新的变量:





之后进入Service 的管控面板(空白处右键选择Configure),先选择变量组:

再进入 CONTROLLER SERVICES 对Service的配置进行修改,将具体的RUL、Driver-name、user等参数,全部使用变量替换(变量使用‘#’符 )

DBCPConnectionPool的使用样例
下面将使用Nifi 实现一个简单的Demo,从Mysql数据库中读取部分数据,将数据进行筛选,然后将数据输出;
首先,使用ExecuteSQL组件,读取Mysql中的数据,根据上文描述,创建一个DBCPConnectionPool 的Service,然后启动 :

添加 ExecuteSQL组件,配置相关内容,根据自定义编写的SQL读取数据库内容:

随后添加 ConvertAvroToJSON 组件,这里从数据库读出的数据是不可读的,为了方便查看调试、同时也是为了后续使用groovy处理数据,所以选择转换为JSON进行处理,实际使用可以根据自身情况选择转换器:
 添加 ExecuteGroovyScript 组件,使用groovy脚本对数据进行处理,groovy的脚本内容如下:
添加 ExecuteGroovyScript 组件,使用groovy脚本对数据进行处理,groovy的脚本内容如下:

groovy内容:
import org.apache.commons.io.IOUtils;
import java.nio.charset.StandardCharsets;
import groovy.json.JsonBuilder;
import groovy.json.JsonOutput;
import groovy.json.JsonSlurper;
import groovy.json.StringEscapeUtils;
import java.util.*;
def dataJson = getInputJSONData()
if(null == dataJson){
return;
}
def rss = []
for(int i = 0; i < dataJson.size();i++){
def tem = dataJson.get(i);
//在这里可以对数据进行处理
rss.add(tem.name);
}
// 输出
if(rss.size()>0){
sendData(rss,REL_SUCCESS);
}
/**
* 读取输入流
* @author GCC
***/
def getInputJSONData(){
def flow = session.get()
if(null == flow){
log.error("the flow is null ...");
return;
}
def dataJson = null;
def jsonStr = "";
session.read(flow,{
inputStream ->
jsonStr = IOUtils.toString(inputStream, StandardCharsets.UTF_8)
} as InputStreamCallback);
try{
dataJson = new JsonSlurper().parseText(jsonStr);
}catch(Exception e){
log.error("输入流格式错误")
}
session.remove(flow);
return dataJson;
}
/**
*输出数据至后续管道
*@param result 输出的数据
*@param outStream 输出的管道
*@author GCC
***/
void sendData(def result,def outStream){
String successFlowFileStr =StringEscapeUtils.unescapeJavaScript(new JsonOutput().toJson(result).toString());
def newflow = session.create();
newflow = session.write(newflow, {
outputStream ->
outputStream.write(successFlowFileStr.getBytes(StandardCharsets.UTF_8))
} as OutputStreamCallback)
session.transfer(newflow, outStream);
}最后使用LogMessage组件作为接收数据,实际情况可以将数据转为下一处理节点或存储等等


在ExcuseGroovyScript组件中使用Service
在 ExcuseGroovyScript 组件内部使用groovy脚本处理数据时,可能需要再次读取数据库或者使用其他第三方数据来辅助处理,这时候,ExcuteGroovyScript组件支持可以引入Service,提供用户编写的groovy脚本内部使用Service;
首先需要在ExcuteGroovyScript组件的PROPERTIES 配置中新增属性:

这里,添加属性时,会让用户输入用户给该属性的命名,如果是普通命名,这里的属性仅仅作为静态数据而已,但是如果使用关键字 ‘SQL.’ 或者 'CTL.'作为名称前缀时,则能够使用Service,后续的属性值则会变成Service的选择。
在groovy的代码中,则可以通过 SQL.mysql.{method}的方式,调用Service的方法,在ExcuseScript组件中配合脚本语言进行数据的操作:
import org.apache.commons.io.IOUtils;
import java.nio.charset.StandardCharsets;
import groovy.json.JsonBuilder;
import groovy.json.JsonOutput;
import groovy.json.JsonSlurper;
import groovy.json.StringEscapeUtils;
import java.util.*;
def dataJson = getInputJSONData()
if(null == dataJson){
return;
}
def rss = []
for(int i = 0; i < dataJson.size();i++){
def tem = dataJson.get(i);
def mapdic = [:]
//使用Service查询数据库
SQL.mysql.eachRow("SELECT id,value FROM tb_dic_detail WHERE u_status = 1 "){
row->
mapdic.put(row.id.toString(),row.value.toString()); }
rss.add(tem.name);
}
// 输出
if(rss.size()>0){
sendData(rss,REL_SUCCESS);
}
/*****************************************************************公共函数*********************************************************************/
/**
* 读取输入流
* @author GCC
***/
def getInputJSONData(){
def flow = session.get()
if(null == flow){
log.error("the flow is null ...");
return;
}
def dataJson = null;
def jsonStr = "";
session.read(flow,{
inputStream ->
jsonStr = IOUtils.toString(inputStream, StandardCharsets.UTF_8)
} as InputStreamCallback);
try{
dataJson = new JsonSlurper().parseText(jsonStr);
}catch(Exception e){
log.error("输入流格式错误")
}
session.remove(flow);
return dataJson;
}
/**
*输出数据至后续管道
*@param result 输出的数据
*@param outStream 输出的管道
*@author GCC
***/
void sendData(def result,def outStream){
String successFlowFileStr =StringEscapeUtils.unescapeJavaScript(new JsonOutput().toJson(result).toString());
def newflow = session.create();
newflow = session.write(newflow, {
outputStream ->
outputStream.write(successFlowFileStr.getBytes(StandardCharsets.UTF_8))
} as OutputStreamCallback)
session.transfer(newflow, outStream);
}