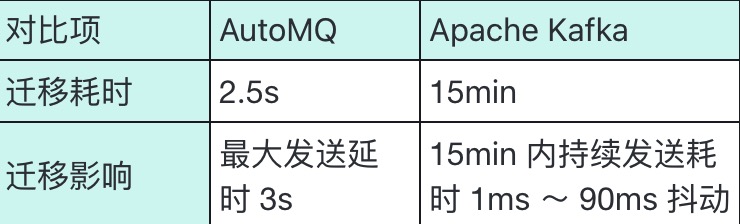
代码
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void atomicAddAndGet(int *result, int *valueToAdd) {
// 原子加法
int addedValue = atomicAdd(result, *valueToAdd);
// 通过原子操作后读取值,确保是加法后的值
addedValue += *valueToAdd;
printf("Thread %d: Added value: %d\n", threadIdx.x, addedValue);
}
int main() {
int result = 0;
int valueToAdd = 5;
int *d_result, *d_valueToAdd;
// 在GPU上分配内存
cudaMalloc((void**)&d_result, sizeof(int));
cudaMalloc((void**)&d_valueToAdd, sizeof(int));
// 将数据从主机内存复制到GPU内存
cudaMemcpy(d_result, &result, sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_valueToAdd, &valueToAdd, sizeof(int), cudaMemcpyHostToDevice);
// 启动CUDA核函数
atomicAddAndGet << <1, 32 >> > (d_result, d_valueToAdd);
// 将结果从GPU内存复制回主机内存
cudaMemcpy(&result, d_result, sizeof(int), cudaMemcpyDeviceToHost);
// 输出结果
printf("Result after atomic addition: %d\n", result);
// 释放GPU上的内存
cudaFree(d_result);
cudaFree(d_valueToAdd);
return 0;
}
结果