目录
分页组件使用
API
组件代码示例
使用思路:
前端示例代码
html
script
后端示例代码
Controller
Impl
xml
总结

分页组件使用
使用Arco Design之前需要配置好搭建前端环境可以看我另外一篇文章:
手把手教你 创建Vue项目并引入Arco Design组件库
Arco Design Vue - <a-pagination> API 详细的可以可以点击此网站查看具体用法
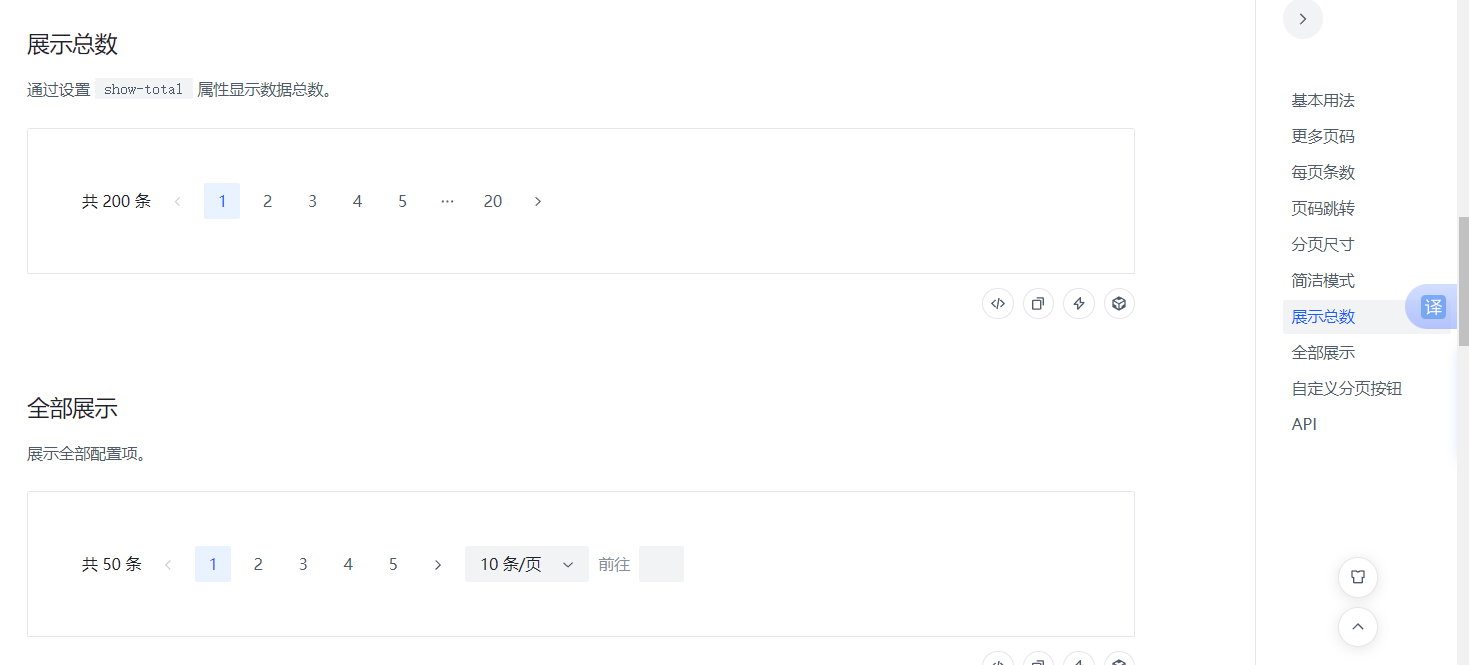
查看源代码
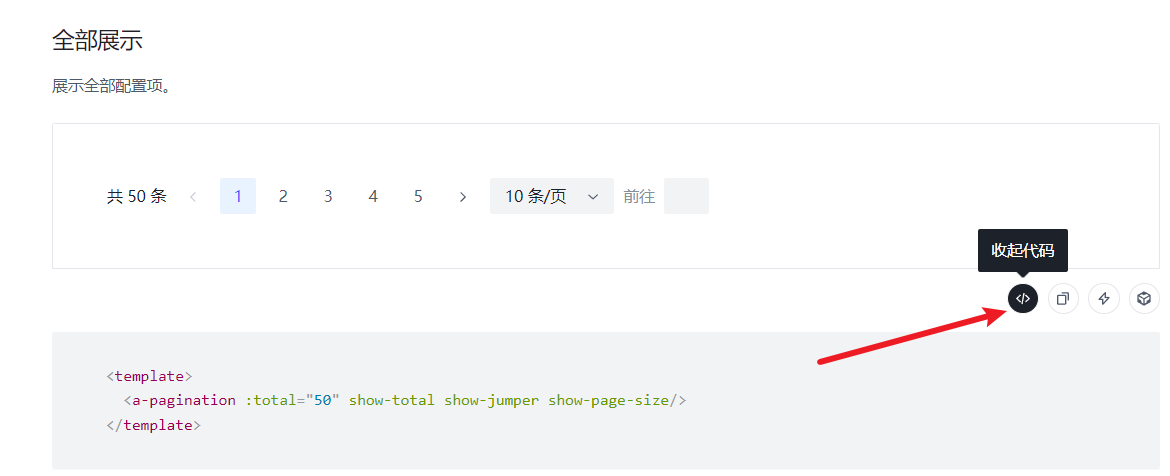
API

组件代码示例
本代码是一个小项目的示例

使用思路:
- 首先获取好总的条数 也就是实例代码中的 --- :total="total",对total进行属性绑定
- 其次获取当前页数 --- :current="currentPage"
- 最后就是获取每页显示多少页 --- :page-size="pageSize"
- 还有就是创建页面改变触发的函数 --- @change="handleChange"
前端示例代码
省略了很多代码就放了关键的分页组件代码。
html
<template>
<a-pagination @change="handleChange"
:total="total" :current="currentPage" :page-size="pageSize" show-total/>
</template>script
<script setup>
import {ref } from "vue";
import {useRouter} from 'vue-router'
import axios from "axios";
import {message} from "ant-design-vue";
import qs from "qs";
// 查询参数响应式变量
const searchParam = ref(
{
keyword: "",
internshipMonthDuration: "",
weekDay: "",
educationalRequirements: "",
employmentOpportunities: "",
corporateLevel: "",
}
)
const items = ref([])
//定义变量保存分页器的当前页数
let currentPage = ref(1);
//定义变量保存分页器的每页显示多少条 这里我设置了一个每页显示8条
let pageSize = ref(8);
//定义变量保存数据总条目数
let total = ref();
// 根据条件从后端获取数据总条数
const getRecordCount = () => {
// 使用qs.stringify() 是将js对象转换为字符串
let data = qs.stringify(searchParam.value);
axios.get('http://localhost:8080/v1/Psearch/selectRecordCount?' + data).then((res) => {
if (res.data.code === 2000) {
console.log("查询的条数为 == " + res.data.data)
total.value = res.data.data;
} else {
message.error("加载失败" + res.data.msg)
}
});
}
// 加载数据
const loadData = () => {
console.log("LoadData执行 当前查询条件searchParam.value === " + searchParam.value);
getRecordCount();
console.log("total === " + total.value)
//定义变量保存分页器的当前页数 放入查询条件中
searchParam.value.currentPage = currentPage.value;
//定义变量保存分页器的每页显示多少条 放入查询条件中
searchParam.value.pageSize = pageSize.value;
let data = qs.stringify(searchParam.value)
//分页条件查询
axios.get('http://localhost:8080/v1/Psearch/selectAllRecords?' + data).then((res) => {
if (res.data.code === 2000) {
console.log("查询的记录为 == " + res.data.data)
items.value = res.data.data;
for (const element of items.value) {
if (element.educationalRequirements === '10') {
element.educationalRequirements = '大专';
} else if (element.educationalRequirements === '20') {
element.educationalRequirements = '本科';
} else if (element.educationalRequirements === '30') {
element.educationalRequirements = '研究生';
}
}
} else {
message.error("加载失败" + res.data.msg)
}
});
}
//页面变化更新数据 点击指定页码时,page是指代这个指定的页码
const handleChange = (page) => {
//点击其他页时候更新当前页码
currentPage.value = page;
}
</script>注意!!!!!!
必须要加这个 handleChange(page) 函数,不然即时分页了,点击指定页码 不会跳转到指定页码
const handleChange = (page) => {
//点击其他页时候更新为点击的指定页码
currentPage.value = page;
}
不设置这个函数更新当前页码,点击了不会跳转到第二页
后端示例代码
Controller
@RestController
@RequestMapping("/v1/Psearch/")
@Slf4j
public class PracticeSearchController {
@Autowired
private PracticeSearchService practiceSearchService;
@GetMapping("selectRecordCount")
public JsonResult selectRecordCount(PracticeSearchRecordsParam practiceSearchRecordsParam){
log.info("前端传入搜索参数:{}",practiceSearchRecordsParam);
Integer count = practiceSearchService.selectRecordCount(practiceSearchRecordsParam);
log.info("后端返回搜索记录的总条数为:{}",count);
return JsonResult.ok(count);
}
@GetMapping("selectAllRecords")
public JsonResult selectAllRecords(PracticeSearchListParam practiceSearchListParam){
log.info("前端传入搜索参数:{}",practiceSearchListParam);
List<PracticeSearchVO> recordsList = practiceSearchService.selectAllRecords(practiceSearchListParam);
return JsonResult.ok(recordsList);
}
}Impl
@Slf4j
@Service
public class PracticeSearchServiceImpl implements PracticeSearchService {
@Autowired
private PracticeSearchMapper practiceSearchMapper;
/**
* 根据查询参数获取实践搜索记录的数量。
*
* @param param 实践搜索的参数对象,用于指定查询条件。
* @return 返回实践搜索记录的总数。
*/
@Override
public Integer selectRecordCount(PracticeSearchRecordsParam param) {
// 调用实践搜索Mapper接口,根据参数查询实践搜索记录的数量
List<PracticeSearchVO> list = practiceSearchMapper.selectRecordCount(param);
// 记录查询到的记录数,用于日志记录和问题排查
log.info("查询记录数 === " + list.size());
// 返回查询到的记录数
return list.size();
}
/**
* 根据实践搜索参数查询所有记录。
*
* @param practiceSearchListParam 实践搜索列表参数,包含分页和过滤条件。
* @return 返回符合条件的实践搜索结果列表。
*/
@Override
public List<PracticeSearchVO> selectAllRecords(PracticeSearchListParam practiceSearchListParam) {
// 获取分页大小
Integer pageSize = practiceSearchListParam.getPageSize();
// 获取当前页码
Integer currentPage = practiceSearchListParam.getCurrentPage();
// 计算数据库查询的起始位置,以实现分页查询 (前端传过来的页码是从第一页开始的所以currentPage要减 1,数据库分页是从第 0 页开始)
currentPage = (currentPage - 1) * (pageSize - 1);
// 更新当前页码,用于后续的分页处理
practiceSearchListParam.setCurrentPage(currentPage);
// 日志记录查询的分页信息
log.info("pageSize === {} currentPage === {}", pageSize, currentPage);
// 调用Mapper查询所有符合条件的记录
List<PracticeSearchVO> list = practiceSearchMapper.selectAllRecords(practiceSearchListParam);
// 日志记录查询结果
log.info("查询到的所有记录 === {}", list);
// 返回查询结果
return list;
}
}
xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.tedu.search.mapper.PracticeSearchMapper">
<select id="selectRecordCount" resultType="cn.tedu.search.pojo.vo.PracticeSearchVO">
SELECT r.title_name,r.corporate_name,r.corporate_level,r.photo_show,
p.salary,p.welfare,p.job_detail,p.educational_requirements,p.employment_opportunities,
c.cover_photo,c.company_size
FROM recruitment_information r
INNER JOIN position_detail p ON r.id = p.recruitment_information_id
INNER JOIN company c ON r.company_id = c.id
WHERE p.job_type = '实习'
<if test="keyword != null and keyword != ''">
AND (
r.title_name LIKE CONCAT('%', #{keyword}, '%')
OR r.corporate_name LIKE CONCAT('%', #{keyword}, '%')
OR p.job_detail LIKE CONCAT('%', #{keyword}, '%')
)
</if>
<if test="internshipMonthDuration != null and internshipMonthDuration != ''">
AND p.internship_month_duration = #{internshipMonthDuration}
</if>
<if test="educationalRequirements != null and educationalRequirements != ''">
AND p.educational_requirements = #{educationalRequirements}
</if>
<if test="employmentOpportunities != null and employmentOpportunities != ''">
AND p.employment_opportunities = #{employmentOpportunities}
</if>
<if test="corporateLevel != null and corporateLevel != ''">
AND r.corporate_level = #{corporateLevel}
</if>
<if test="weekDay != null">
AND p.week_day = #{weekDay}
</if>
</select>
<select id="selectAllRecords" resultType="cn.tedu.search.pojo.vo.PracticeSearchVO">
SELECT r.title_name,r.corporate_name,r.corporate_level,r.photo_show,
p.salary,p.welfare,p.job_detail,p.educational_requirements,p.employment_opportunities
,c.cover_photo,c.company_size
FROM recruitment_information r
INNER JOIN position_detail p ON r.id = p.recruitment_information_id
INNER JOIN company c ON r.company_id = c.id
WHERE p.job_type = '实习'
<if test="keyword != null and keyword != ''">
AND (
r.title_name LIKE CONCAT('%', #{keyword}, '%')
OR r.corporate_name LIKE CONCAT('%', #{keyword}, '%')
OR p.job_detail LIKE CONCAT('%', #{keyword}, '%')
)
</if>
<if test="internshipMonthDuration != null and internshipMonthDuration != ''">
AND p.internship_month_duration = #{internshipMonthDuration}
</if>
<if test="educationalRequirements != null and educationalRequirements != ''">
AND p.educational_requirements = #{educationalRequirements}
</if>
<if test="employmentOpportunities != null and employmentOpportunities != ''">
AND p.employment_opportunities = #{employmentOpportunities}
</if>
<if test="corporateLevel != null and corporateLevel != ''">
AND r.corporate_level = #{corporateLevel}
</if>
<if test="weekDay != null">
AND p.week_day = #{weekDay}
</if>
LIMIT #{currentPage},#{pageSize}
</select>
</mapper>
注:
使用分页 SQL:
假设 每页显示10条数据
查询第一页的10条记录
select * user limit 0 10 (查询第1条到第10条)
or
select * user limit 10 (查询第1条到第10条)
查询第二页的10条记录
select * user limit 10 10 (查询第11条到第20条)
limit 后面两个参数的具体含义:
LIMIT #{currentPage},#{pageSize}
limit (当前页数)* 每页显示的条数(起始数据条数), 每页最大显示的记录数(从起始数据的下一条开始的偏移量)在MyBatis中LIMIT之后的语句不允许的变量不允许进行算数运算,会报错。
如:
LIMIT (#{currentPage}-1)*#{pageSize},#{pageSize}; // 错误
LIMIT ${(currentPage-1)*pageSize},${pageSize}; (正确)
总结
- 确定好需要显示的条数(total)。
- 当前页数(currentPage),可以指定好默认是第0页,本文示例代码是从第1页开始。
- 每页显示多少条记录(pageSize ) --- 一开始就要定义不然页面加载数据时候就要报错。
- 创建好页面变化时触发的函数 handleChange(),更新点击后的页码。
演示一下最终效果啦!!!