「AI秘籍」系列课程:
-
人工智能应用数学基础
-
人工智能Python基础
-
人工智能基础核心知识
-
人工智能BI核心知识
-
人工智能CV核心知识
如何创建美国选举结果的时间序列分级统计图
数据地址为源地址,如果失效请与我联系。
2024 年美国大选将至,关于此次选举据说非常戏剧,两位最大可能的提名候选人跟 2020 年如出一辙。不过,本次大选数据咱们是暂时没办法获得了,就拿 2020 年的那次数据来看看。
2020 年美国大选带来了高度紧张的气氛、毫无根据的欺诈指控,最重要的是,带来了一些很棒的可视化效果。至少对数据科学家来说,这很重要。似乎你无论在哪里都看不到一些新颖的选举结果呈现方式。那么为什么不再添加一些呢?在本教程中,你将学习如何使用 Python 创建一些自己的可视化效果。
你将学习如何创建两张 1976 年至 2016 年美国总统选举结果的交互式分级统计图。第一张地图有一个时间滑块。当你移动滑块时,地图将发生变化,以显示给定年份每个州的结果。对于第二张地图,每个州都变成了一个按钮。你可以单击该州以查看随时间变化的投票趋势。我将介绍代码,你可以在GitHub上找到完整的项目1。你也可以下载地图2,你应该能够在浏览器中打开和浏览它们。

Python 包
我们将使用folium3构建地图。这是一个非常有用的包,可用于创建简单的地理空间数据可视化。除了 folium 之外,我们还将使用一些其他 Python 包。你可以使用以下代码导入它们。请确保你已先安装所有包。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt, mpld3
%matplotlib inline
import json
import datetime
from shapely.geometry import Polygon, mapping
import geopandas as gpd
import folium
from folium.plugins import TimeSliderChoropleth
数据源
美国形状文件
我们需要的第一个数据集是美国的 shapefile4。shapefile是一种用于存储地理空间矢量数据的文件格式。在我们的例子中,我们有一组坐标,它们定义了美国每个州的边界。我们将数据读入为GeoPandas 数据框。数据框的51行中的每一行都给出了州的名称和坐标(即几何图形)。
# Get US states shapefile
us_shape = gpd.read_file(data_path + '/States_shapefile/States_shapefile.shp')
us_shape = us_shape[['State_Name','geometry']]
us_shape.head()
---
State_Name geometry
0 ALABAMA POLYGON ((-85.07007 31.9807, -85.11515 31.9074...
1 ALASKA MULTIPOLYGON (((-161.33379 58.73325, -161.3824...
2 ARIZONA POLYGON ((-114.52063 33.02771, -114.55909 33.0...
3 ARKANSAS POLYGON ((-94.46169 34.19677, -94.45262 34.508...
4 CALIFORNIA MULTIPOLYGON (((-121.66522 38.16929, -121.7823...
让我们使用此 Shapefile 创建第一张 folium 地图。在下面的代码中,我们初始化地图。通过设置 location=[50.77500, -100],地图在打开时将聚焦于美国。然后,我们使用美国 Shapefile 和 GeoJson 函数向地图添加分级统计图。在图 1 中,你可以看到此代码创建的地图。Shapefile 为我们提供了工作基础,但我们需要另一个用于选举结果的数据集。
# plot the shape file with folium
m = folium.Map(location=[50.77500, -100],zoom_start=3)
choropleth =folium.GeoJson(data= us_shape.to_json())
m.add_child(choropleth)
选举结果数据集
对于选举结果,我们使用麻省理工学院选举数据和科学实验室提供的数据集5。它包含 1976 年至 2020 年美国总统选举结果。该数据集包含该年每个州、年份和参选候选人的行。为了让事情变得简单一点,我们应该先将此数据集转换为不同的格式。
# Get election data
election = pd.read_csv(data_path + "/U.S. President 1976–2020/1976-2020-president.csv" )
election.replace('democratic-farmer-labor','democrat',inplace=True)
election.head()
---
year state state_po state_fips state_cen state_ic office candidate party_detailed writein candidatevotes totalvotes version notes party_simplified
0 1976 ALABAMA AL 1 63 41 US PRESIDENT CARTER, JIMMY DEMOCRAT False 659170 1182850 20210113 NaN DEMOCRAT
1 1976 ALABAMA AL 1 63 41 US PRESIDENT FORD, GERALD REPUBLICAN False 504070 1182850 20210113 NaN REPUBLICAN
2 1976 ALABAMA AL 1 63 41 US PRESIDENT MADDOX, LESTER AMERICAN INDEPENDENT PARTY False 9198 1182850 20210113 NaN OTHER
3 1976 ALABAMA AL 1 63 41 US PRESIDENT BUBAR, BENJAMIN ""BEN"" PROHIBITION False 6669 1182850 20210113 NaN OTHER
4 1976 ALABAMA AL 1 63 41 US PRESIDENT HALL, GUS COMMUNIST PARTY USE False 1954 1182850 20210113 NaN OTHER
使用下面的代码,我们将数据集转换为嵌套字典。对于每一年,我们都有一个以州名作为键的字典。对于每个州,都有一个字典给出民主党和共和党候选人的投票数。字典的形式如下:
{
<year>: {
<state> : {'dem':<#votes>, 'rep':<#votes>},
<state> : {'dem':<#votes>, 'rep':<#votes>},
...},
...
}
# Transform election data
states = set(election['state'])
results = {}
for year in range(1976,2024,4):
result = {}
for state in states:
state_year = election[(election.year == year)
& (election.state == state)]
dem = max(state_year[state_year.party_simplified == 'DEMOCRAT']['candidatevotes'])
rep = max(state_year[state_year.party_simplified == 'REPUBLICAN']['candidatevotes'])
result[state] = {'dem':dem, 'rep':rep}
results[year] = result
results
---
{1976: {'TEXAS': {'dem': 2082319, 'rep': 1953300},
...
'MISSOURI': {'dem': 998387, 'rep': 927443}},
1980: {'TEXAS': {'dem': 1881147, 'rep': 2510705},
...
2020: {'TEXAS': {'dem': 5259126, 'rep': 5890347},
...
'MISSOURI': {'dem': 1253014, 'rep': 1718736}}}
数据可视化
在开始介绍交互式地图之前,让我们先使用这些数据集来创建一个简单的等值线图。我们首先需要定义两个函数。state_style 函数返回一个用于定义州的颜色和边界的字典。如果某个州在某一年投票给民主党,则该州将变为蓝色;如果投票给共和党,则该州将变为红色。该函数返回的字典略有不同,具体取决于它是被 style_dictionary 还是 style_function 使用。
def state_style(state,year,function=False):
"""
Returns the style for a state in a given year
"""
state_results = results[year][state]
#Set state colour
if state_results['dem'] >= state_results['rep']:
color = '#4f7bff' #blue
else:
color = '#ff5b4f' #red
#Set state style
if function == False:
# Format for style_dictionary
state_style = {
'opacity': 1,
'color': color,
}
else:
# Format for style_fucntion
state_style = {
'fillOpacity': 1,
'weight': 1,
'fillColor': color,
'color': '#000000'}
return state_style
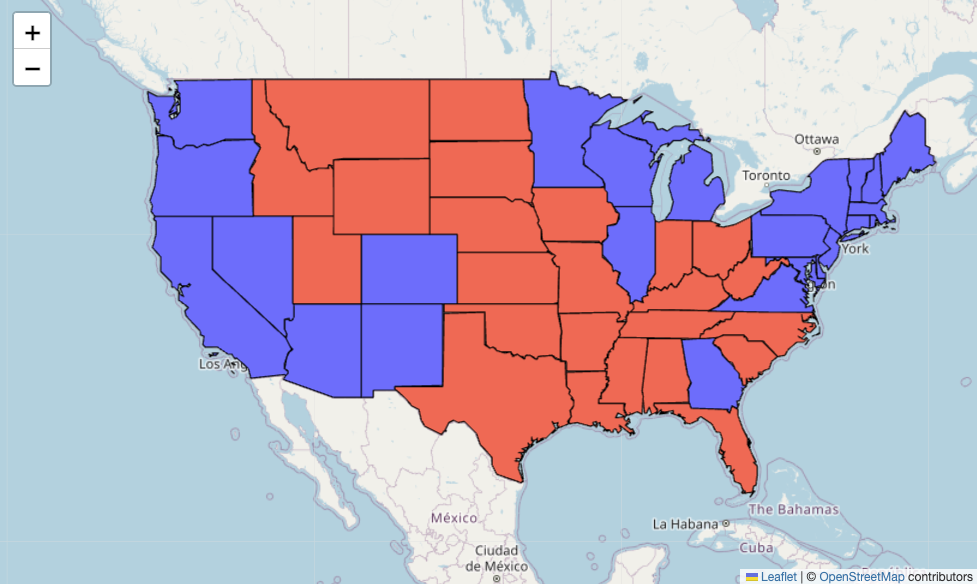
对于此等值线图,我们将使用 style_function。 GeoJson 包使用此函数将 GeoJson 特征映射到样式。在我们的例子中,GeoJson 特征将包含有关州的信息(即名称和几何形状)。这些特征由 GeoJson 包传递给 style_function。通过设置 year=2020,我们使用 2020 年选举的结果来定义每个州的样式。
def style_function(feature):
"""
style_function used by the GeoJson folium function
"""
state = feature['properties']['State_Name']
style = state_style(state,year=2020,function=True)
return style
现在,我们可以使用这些函数来创建我们的第一个等值线图。代码与我们用于创建第一张地图的代码非常相似。唯一的区别是我们现在将 style_function 传递给 GeoJson 函数。如上所述,这会根据选举结果为每个州赋予一种颜色。生成的地图如图 2 所示。现在,让我们看看如何改进这张地图并使其更具交互性。
# plot the choropleth
m = folium.Map(location=[50.77500, -100],zoom_start=3)
choropleth =folium.GeoJson(data= us_shape.to_json(),style_function=style_function)
m.add_child(choropleth)
地图 1:分级统计图滑块
我们首先创建一个带有时间滑块的等值线地图。这是使用 TimeSliderChoropleth 函数完成的。此函数假定所有日期都采用 Unix 时间格式(即时间戳)。因此,我们使用year_to_ts函数将选举年份转换为时间戳。例如,2020 年将转换为 “1577808000”。
def year_to_ts(year):
"""
Convert year to timestamp
"""
time = datetime.datetime(year, 1, 1, 0, 0).strftime('%s')
if len(time)==9: time ='0{}'.format(time)
return time
我们需要定义的第二个函数style_dictionary返回一个样式字典。这与style_function类似,只是我们现在处理的是时间序列数据。因此,对于每个州,我们需要定义其从 1976 年到 2016 年每年的样式。style_dictionary函数返回一个嵌套字典,形式如下:
{
<ID>: {
<timestamp> : {'opacity':1, 'color':<hex_color>},
<timestamp> : {'opacity':1, 'color':<hex_color>},
...},
...
}
上面提到的 ID 是分配给每个州的唯一 ID。它由.to_json()函数自动分配。TimeSliderChoropleth 使用这些 ID 将州映射到其样式。因此,为了确保我们有正确的映射,我们首先创建从 ID 到州名的映射。这在下面的第 7 行到第 13 行中完成。该函数的其余部分使用上面看到的形式创建字典。
def style_dictionary():
"""
style_dictionary used by the TimeSliderChoropleth folium function
"""
# get ids used by TimeSliderChoropleth
ID = {}
state_json = json.loads(us_shape.to_json())
for state in state_json['features']:
state_id = state['id']
state_name = state['properties']['State_Name']
ID[state_name] = state_id
#create style dictionary
style_dic= {}
for state in states:
state_dic = {}
for year in range(1976,2024,4):
time = year_to_ts(year)
state_dic[time] = state_style(state,year)
style_dic[ID[state]] = state_dic
return style_dic
现在我们准备创建地图了。同样,代码与之前类似,只是我们使用了 TimeSliderChoropleth 函数并传入了样式字典。代码的结果可以在图 3 中看到。你将能够滑动地图顶部的条形图来查看随时间变化的选举结果。例如,从 2012 年到 2020 年,我们可以看到几个州变成红色。这导致共和党候选人获胜。
# Create time slider map
m = folium.Map(location=[50.77500, -100],zoom_start=3)
ts = TimeSliderChoropleth(us_shape.to_json(), style_dictionary())
m.add_child(ts)
m.save("../figures/us_election_map1.html")
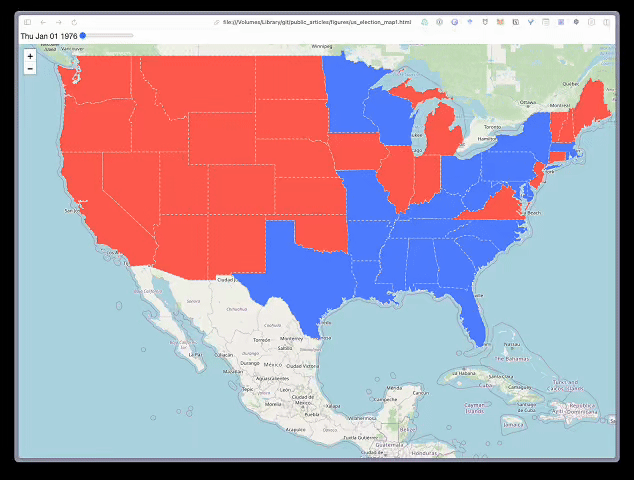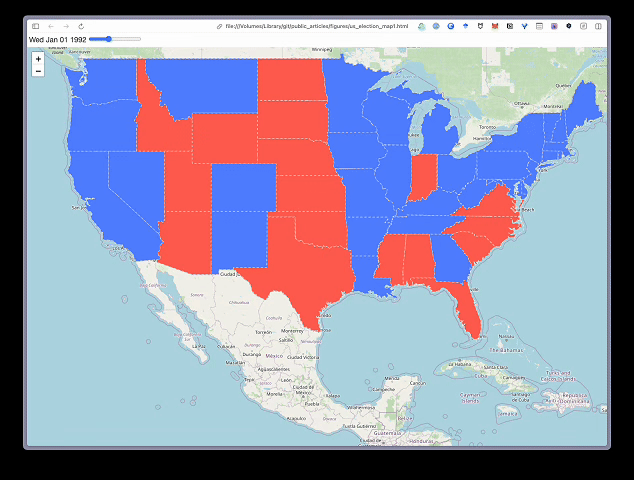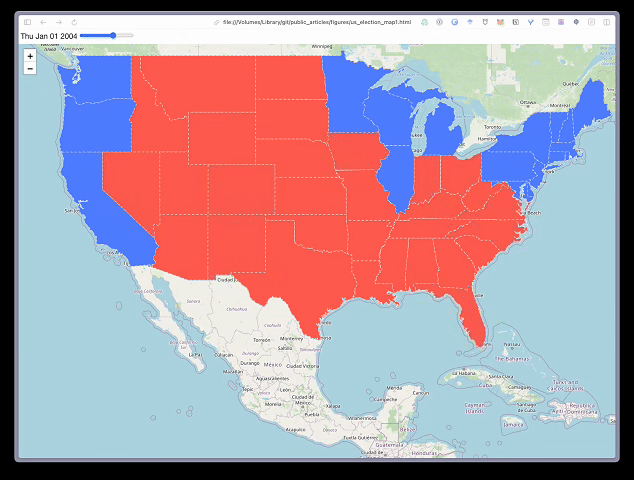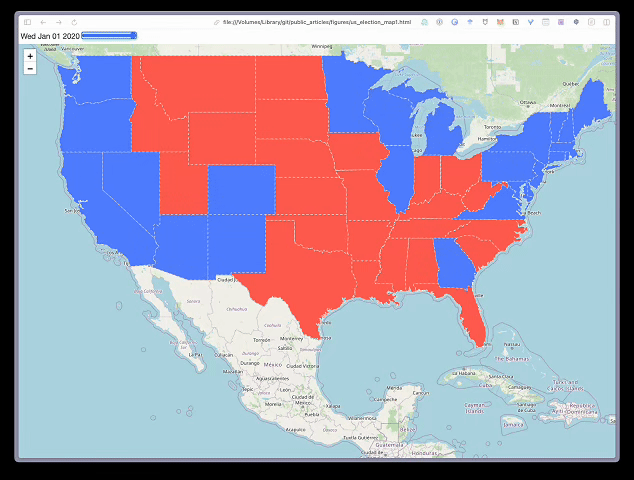
我们应该在上面的第 6 行提到保存地图的代码。此行将地图保存为 HTML 文件。你可以在任何浏览器中打开并浏览它。如果你使用的是 jupyter 笔记本,地图也会显示在代码块下方。如果地图太复杂,笔记本可能无法呈现它。在这种情况下,你必须保存地图并在浏览器中打开它,然后才能看到它。
地图 2:分级统计图按钮
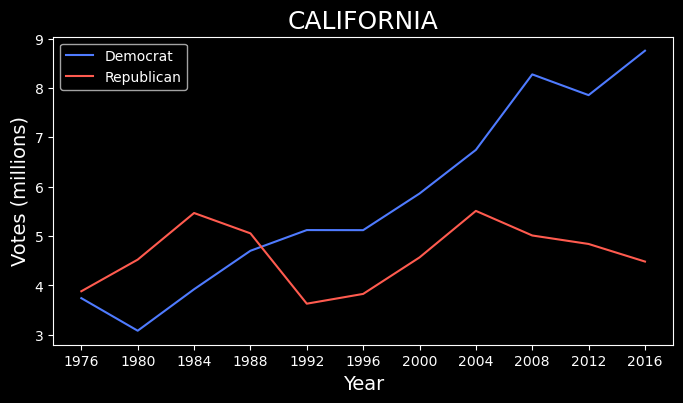
对于下一张地图,我们将把每个州变成一个按钮。你可以单击该州以查看随时间变化的投票趋势。首先,要创建这些趋势图,我们使用以下代码。getFigure 函数为给定的州创建标准 matplotlib 图表。在最后几行中,我们将图表转换为 HTML 并将其添加到 IFrame。这样它就可以嵌入到我们的 folium 地图中。你可以在图 5 中看到为加利福尼亚州制作的图表示例。
def getFigure(state):
"""
Plot voting trends from a given state
"""
#Get number of votes
years = range(1976,2024,4)
dems = []
reps =[]
for year in years:
result = results[year][state]
dems.append(result['dem']/1000000)
reps.append(result['rep']/1000000)
#Plot number of votes
fig = plt.figure(figsize=(8,4))
plt.plot(years,dems,label='Democrat',color='#4f7bff')
plt.plot(years,reps,label='Republican',color='#ff5b4f')
plt.title(state,size = 18)
plt.ticklabel_format(style='plain')
plt.xlabel('Year',size =14)
plt.xticks(years)
plt.ylabel('Votes (millions)',size =14)
plt.legend(loc =0)
#Add figure to iframe
html = mpld3.fig_to_html(fig)
iframe = folium.IFrame(html=html,width = 600, height = 300)
return iframe
在创建按钮等值线图之前,我们必须定义最后一个函数。highlight_style 函数用于定义鼠标悬停在某个状态上时的样式。发生这种情况时,该状态将变得略微阴影化。这使我们能够在单击鼠标之前看到鼠标处于什么状态。
def highlight_style(feature):
"""
style_function used when choropleth button
is highighted
"""
return {'fillOpacity': 0.2,
'weight': 1,
'fillColor': '#000000',
'color': '#000000'}
最后,为了创建地图,我们首先使用 2020 年的结果创建一个分级统计图。我们使用与图 2 中的地图完全相同的代码来执行此操作。然后,使用每个州的几何图形,我们创建一个州标记并向每个标记添加一个弹出窗口。每个弹出窗口都包含上面讨论的嵌入式图表之一。单击标记时,将显示弹出窗口,我们将能够看到投票趋势。
# plot the shape file with folium
m = folium.Map(location=[50.77500, -100],zoom_start=5,max_zoom=5) #Initialize map
choropleth =folium.GeoJson(data= us_shape.to_json(),
style_function=style_function)
m.add_child(choropleth)
# Create popup button for each state
for i in range(len(us_shape)):
geometry = us_shape.loc[i]['geometry']
state_name = us_shape.loc[i]['State_Name']
popup = folium.Popup(getFigure(state_name),max_width=1000)
state_marker = folium.GeoJson(data=mapping(geometry),
highlight_function = highlight_style)
state_marker.add_child(popup)
m.add_child(state_marker)
m.save("../figures/us_election_map2.html")
你可以在图 4 中看到此代码的结果。你可以看到将鼠标悬停在某个州上方会如何突出显示该州。还可以单击德克萨斯州和加利福尼亚州以显示其趋势。在笔记本中查看此地图可能会有些困难。在这种情况下,请将其保存为 HTML 文件并在浏览器中打开。

本文到这里就要结束了,与本文不同,2024 年美国大选尚未开始。届时,会有很多新的数据可供使用,我们将能够使用 20204 年的数据更新可视化。我们会看到各州的颜色发生变化,趋势是否发生变化。这些变化的原因很复杂。像这样的可视化是帮助我们理解它们的一个很好的步骤。
茶桁的公开文章代码仓库, https://github.com/hivandu/public_articles ↩︎
地图 HTML 文件: https://github.com/hivandu/public_articles/tree/main/maps ↩︎
Folium, https://python-visualization.github.io/folium/ ↩︎
shapefile, https://alicia.data.socrata.com/Government/States-21basic/jhnu-yfrj/data ↩︎
选举数据, https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/42MVDX ↩︎