近年来多模态大语言模型(MLLMs)在视觉理解任务中取得了长足进步。然而,大多数模型仍局限于处理低分辨率图像,这限制了它们在需要详细视觉信息的任务中的表现。针对这一问题,上海交通大学的研究团队推出了MG-LLaVA(Multi-Granularity LLaVA),这是一种基于多粒度指令调整的创新多模态大语言模型。MG-LLaVA凭借其出色的性能,在多个视觉大模型评测榜单中取得了领先成绩。
MG-LLaVA的核心亮点在于引入了多粒度视觉流,同时处理低分辨率、高分辨率和物体中心的特征。这一设计显著提升了模型的视觉处理能力。具体来说,MG-LLaVA增加了一个高分辨率视觉编码器来捕捉细粒度细节,并通过一个卷积门控融合网络将这些细节与基础视觉特征融合。此外,研究人员还利用离线检测器识别的边界框,引入了物体级特征,进一步增强了模型的物体识别能力。
通过在公开可用的多模态数据集上进行指令调优,MG-LLaVA展现出了卓越的感知技能。研究人员还尝试了从3.8B到34B不同规模的语言编码器,全面评估了模型的性能。在多项基准测试中,MG-LLaVA的表现超越了同等参数规模的现有MLLMs,充分证明了其出色的效果。
论文标题:
MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
论文链接:
https://arxiv.org/pdf/2406.17770

视觉大模型的"近视"困境
近年来,GPT-4V等多模态大语言模型(MLLMs)在视觉语言理解、视觉推理和交互等领域取得了显著进展。然而,这些模型面临着一个共同的挑战:它们大多只能处理低分辨率图像,这限制了它们在需要精细视觉信息的任务中的表现。
就像一个"近视"的观察者,当前的视觉大模型难以捕捉图像中的细节信息。例如,它们可能无法准确识别小物体,或难以描述复杂场景中的精细特征。这种局限性严重影响了模型在实际应用中的表现。

为了解决这个问题,研究人员提出了各种策略来增强视觉编码器的能力,如使用多样化的数据集训练、采用高分辨率图像输入等。然而,这些方法往往会增加计算成本,或者无法全面利用多粒度的视觉信息。
针对这一挑战,上海交通大学的研究团队开发了MG-LLaVA(Multi-Granularity LLaVA)。这个创新模型通过引入多粒度视觉流框架,同时处理低分辨率、高分辨率和物体级特征,大大提升了模型的视觉理解能力。
MG-LLaVA在各种视觉语言任务中都表现出色,尤其是在涉及物体识别的任务中。与现有模型相比,MG-LLaVA展现出了显著的性能提升。
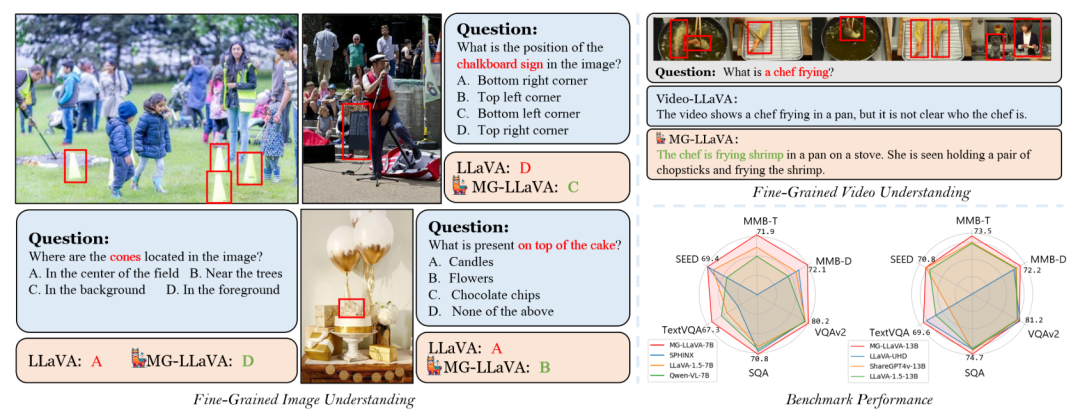
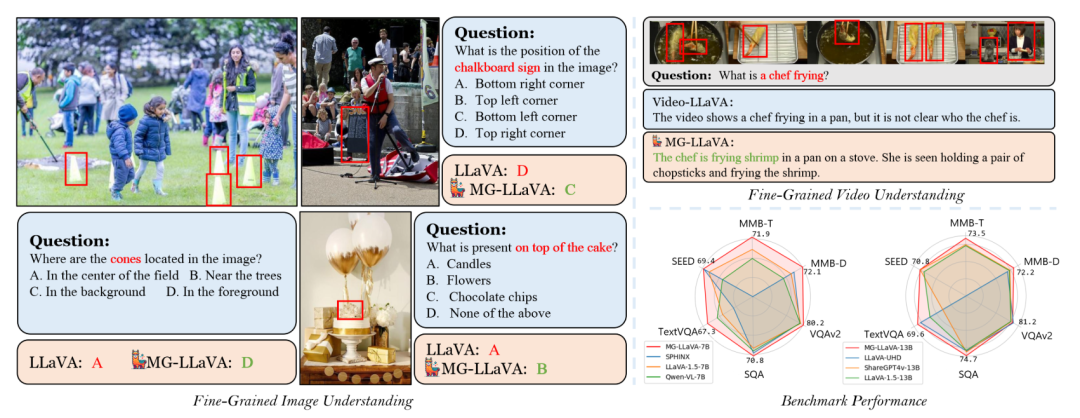
下图进一步说明了MG-LLaVA与现有MLLMs的区别。传统模型通常只使用单一分辨率的视觉输入,而MG-LLaVA能够同时处理多个粒度的视觉信息,包括物体级、低分辨率和高分辨率输入。这种多粒度处理方式使MG-LLaVA能够更全面、更精确地理解视觉内容。
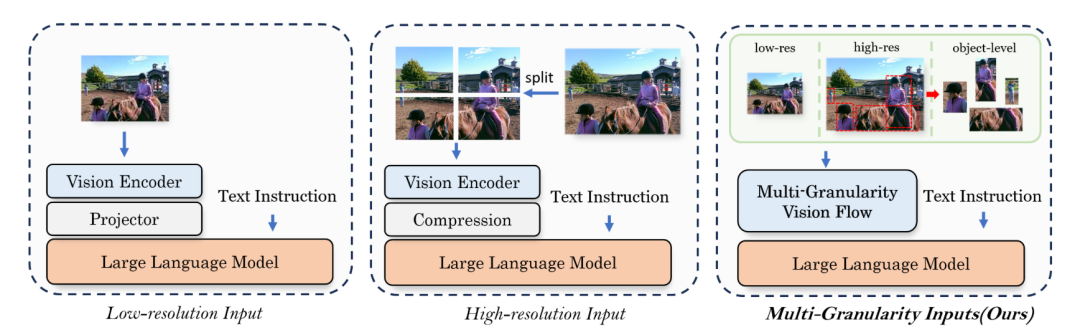
通过这种创新设计,MG-LLaVA不仅克服了现有视觉大模型的"近视"困境,还为提升多模态AI的视觉理解能力开辟了新的研究方向。接下来,让我们深入了解MG-LLaVA的具体实现方法。
MG-LLaVA的多粒度视觉流框架
MG-LLaVA的核心创新在于其多粒度视觉流(Multi-Granularity Vision Flow)框架。这个框架能够同时处理不同分辨率的图像输入和物体级特征,从而实现更全面的视觉理解。MG-LLaVA主要包含以下几种主要技术。
多粒度视觉编码
MG-LLaVA的视觉处理流程包含三个主要分支:
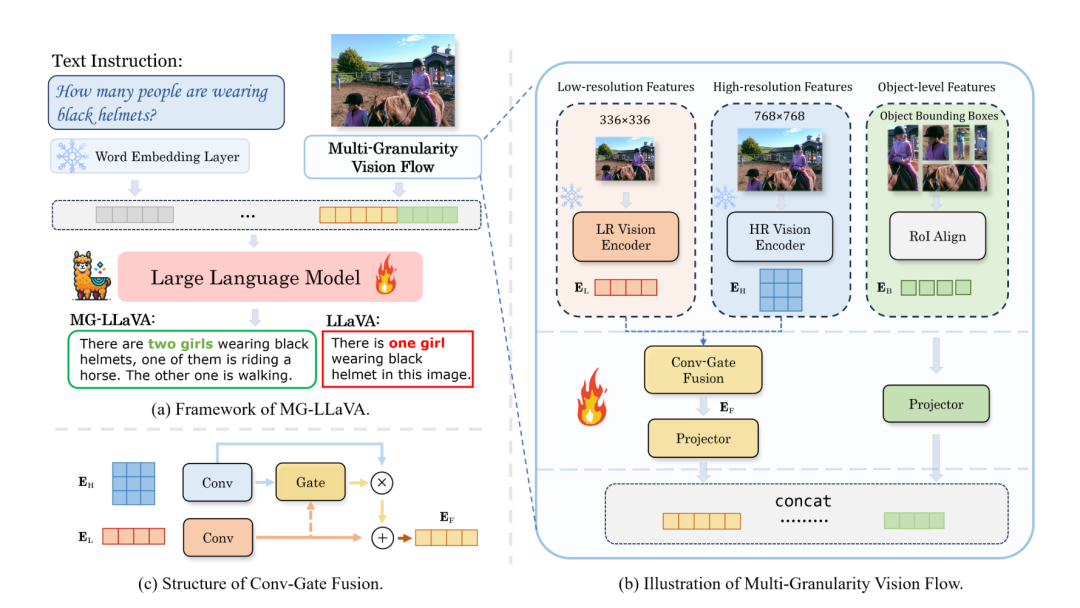
低分辨率分支
低分辨率分支负责捕捉图像的全局信息和整体结构,这个分支的优势在于其扩大的感受野,能够有效捕捉图像的整体语义信息。
-
使用CLIP预训练的ViT-Large-14-336模型作为低分辨率视觉编码器()。
-
输入处理:接收低分辨率图像 ,通常设置为336×336像素。
-
特征生成:产生低分辨率特征 ,其中 是视觉token数量, 是特征维度。
-
计算过程:
高分辨率分支
高分辨率分支专注于提取图像的细粒度特征和局部细节,这个分支能够捕捉到更多的图像细节,有助于提高模型在需要精细视觉信息的任务中的表现。
-
视觉编码器:采用LAION预训练的ConvNext-Large-320作为高分辨率视觉编码器()。
-
输入处理:接收高分辨率图像 ,分辨率设置为768×768像素。
-
特征生成:产生高分辨率特征 ,其中 和 分别是特征图的高度和宽度。
-
计算过程:
物体级特征分支
物体级特征分支旨在提取图像中具体物体的特征,这个分支使模型能够关注图像中的特定物体,增强了模型的物体识别和定位能力。
-
物体检测:使用预训练的开放词汇检测器(如OWL-ViT v2)识别图像中的物体边界框。
-
特征提取:对高分辨率特征图进行RoI Align操作,提取每个物体的特征。
-
特征处理:通过平均池化处理得到物体级特征序列 , 是检测到的物体数量。
-
计算过程:其中, 是上采样并连接的多尺度高分辨率特征, 是边界框集合.
Conv-Gate特征融合
为了有效整合低分辨率和高分辨率特征,MG-LLaVA采用了一个轻量级的Conv-Gate融合网络:
其中,Conv表示1D卷积操作,G是门控层。这种融合方式能够在保持计算效率的同时,有效结合不同分辨率的视觉信息。
特征对齐与输入处理
MG-LLaVA的特征对齐与输入处理是将多粒度视觉特征有效整合并与语言模型对接的关键环节。融合后的特征E_F和物体级特征E_B分别通过独立的投影器进行处理: 和 。
将处理后的特征与文本嵌入E_T连接,作为语言模型的输入:
通过这种多粒度处理和融合方法,MG-LLaVA能够同时利用图像的全局信息、局部细节和物体级特征,从而实现更全面、更精确的视觉理解。这种方法不仅克服了传统视觉大模型仅依赖单一分辨率输入的局限性,还能有效处理真实世界中复杂多样的视觉场景。
模型训练
MG-LLaVA的训练过程分为两个阶段:
预训练阶段
-
冻结所有视觉编码器和语言模型。
-
只训练融合模块、视觉投影器和物体特征投影器。
-
目的是优化特征融合和对齐能力。
指令调优阶段:
-
保持视觉编码器冻结。
-
微调其他组件,以增强多模态理解能力。
训练目标函数为:

其中,XA是目标答案,VL和 VH分别是低分辨率和高分辨率输入,B是物体边界框集合,T是文本输入。
推理流程
MG-LLaVA的推理过程如下所示:
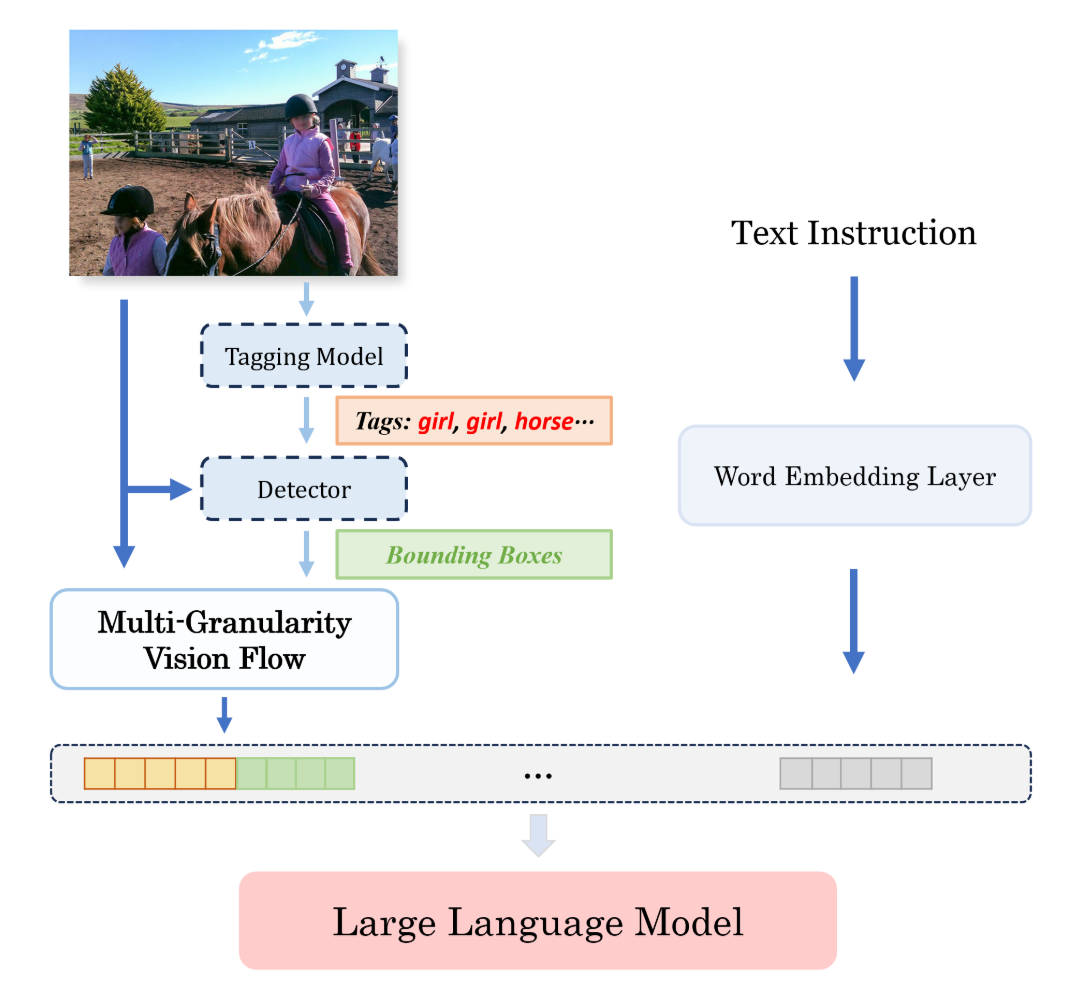
首先,RAM模型为输入图像生成物体标签,这些标签随后被OWL-ViT v2检测器用于生成精确的物体边界框。接着,MG-LLaVA同时处理图像的低分辨率和高分辨率版本,并结合边界框信息提取多粒度视觉特征。最后,模型将这些视觉特征与用户的文本查询整合,由语言模型生成最终响应。这种多层次的处理方法使MG-LLaVA能够全面理解复杂的视觉场景,从而在各种视觉任务中表现出色。
这种精心设计的特征对齐与输入处理方法使MG-LLaVA能够充分利用多粒度视觉信息,实现了视觉和语言信息的有效融合。这不仅提高了模型在各种视觉理解任务中的表现,还增强了其处理复杂、高分辨率视觉场景的能力。通过整合全局结构、局部细节和物体级信息,MG-LLaVA展现出了优越的视觉感知和理解能力。
MG-LLaVA的表现
研究团队在多个权威的视觉理解基准测试上对模型进行了评估,MG-LLaVA都表现出令人惊讶的效果。
下表展示了MG-LLaVA在多个视觉感知基准测试上的结果:
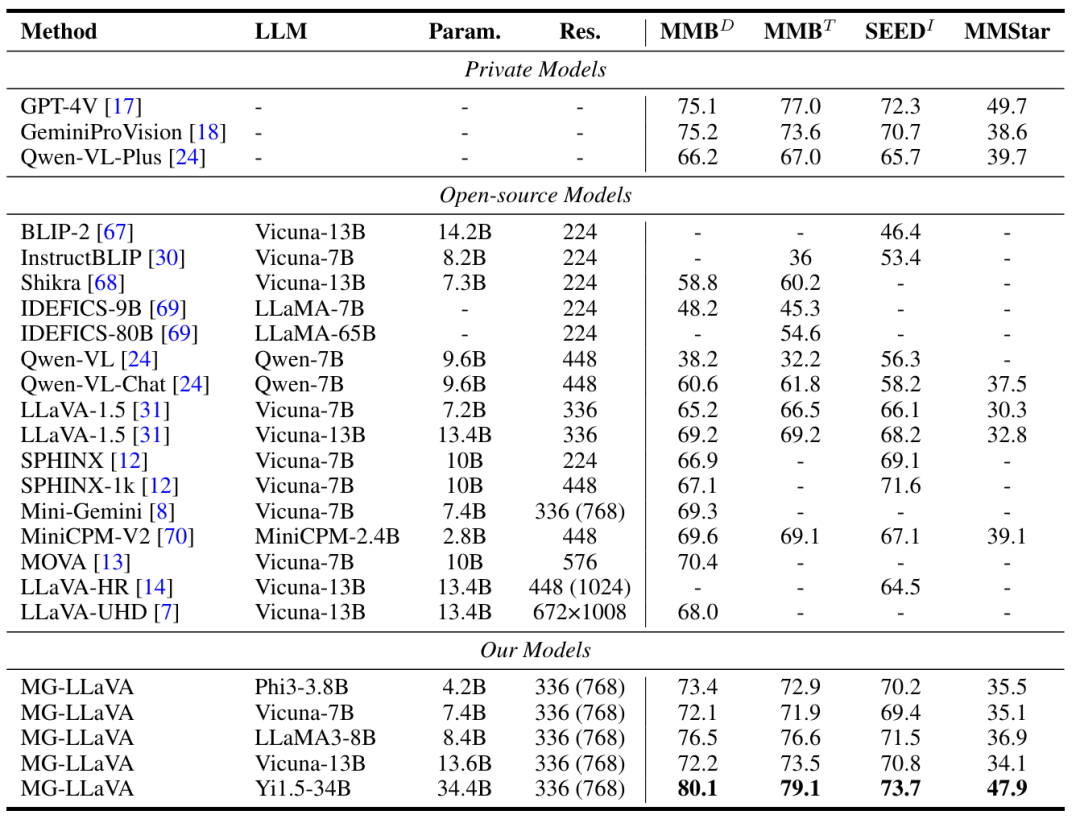
在MMBench-Dev和MMBench-Test上,MG-LLaVA-Yi1.5-34B分别达到了80.1%和79.1%的准确率,超过了GPT-4V。在SEEDBench-Image上,MG-LLaVA-Yi1.5-34B达到73.7%的准确率,同样优于GPT-4V。即使是参数较少的MG-LLaVA-Phi3-3.8B,也在MMBench-Dev上达到了73.4%的准确率,超过了许多参数更多的模型(MOVA等)。
MG-LLaVA在视觉问答上展现出经验的效果:在TextVQA上,MG-LLaVA-Yi1.5-34B达到70.0%的准确率;在DocVQA、ScienceQA-Image和AI2D等任务上,MG-LLaVA也都取得了优秀成绩。

同样的效果也出现在视频问答任务上,在MSVD-QA和MSRVTT-QA上,MG-LLaVA分别达到71.5%和59.8%的准确率,超过了之前的Video-LLaVA模型。

下图通过柱状图直观展示了MG-LLaVA在MMBench-DEV-EN和Seed-bench的各个子任务上的表现,特别是在细粒度感知、属性推理等方面的优势。
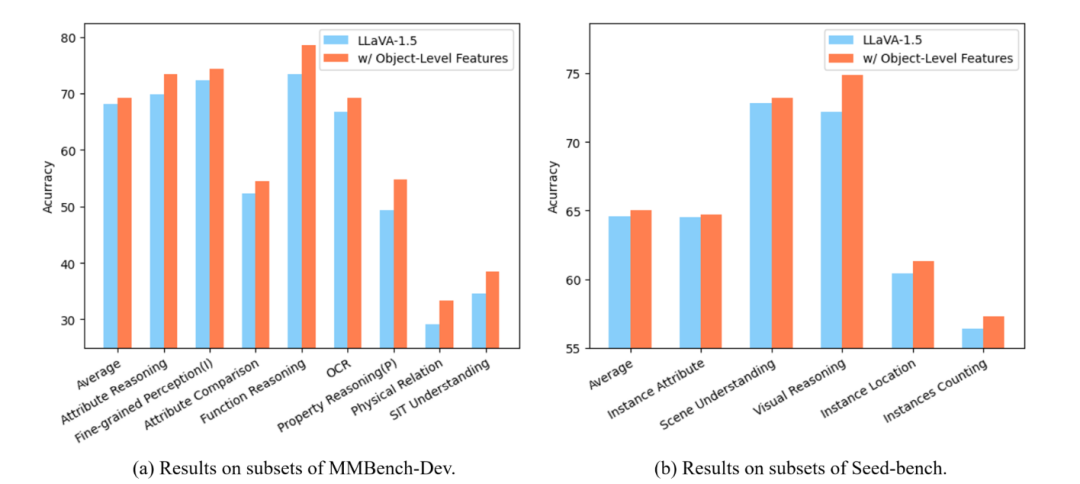
除此之外,作者还进行消融实验验证物体级特征和Conv-Gate融合模块的有效性,并且对不同特征融合方法进行了比较。


上面的表格展示了MG-LLaVA不同组件的消融实验结果,使用Vicuna-7B和Phi3-3.8B两种语言模型。从结果可以看到加物体级特征后,大多数任务性能有所提升;进一步加入Conv-Gate融合模块后,性能再次提高。说明物体级特征和Conv-Gate融合模块都对模型性能有正面影响。
总结与展望
上海交通大学研究人员提出的MG-LLaVA通过创新的多粒度视觉处理方法,在多项视觉理解任务中取得了卓越成绩,展现了视觉AI的新高度。其多粒度视觉流框架有效整合了不同尺度的图像特征,大幅提升了模型的视觉理解能力。
这一突破不仅为多模态大语言模型的发展指明了方向,也为医疗、自动驾驶等领域的应用开辟了新可能。未来,随着技术的进一步完善,MG-LLaVA有望在更广泛的场景中发挥其优势,推动AI视觉理解能力的持续提升。