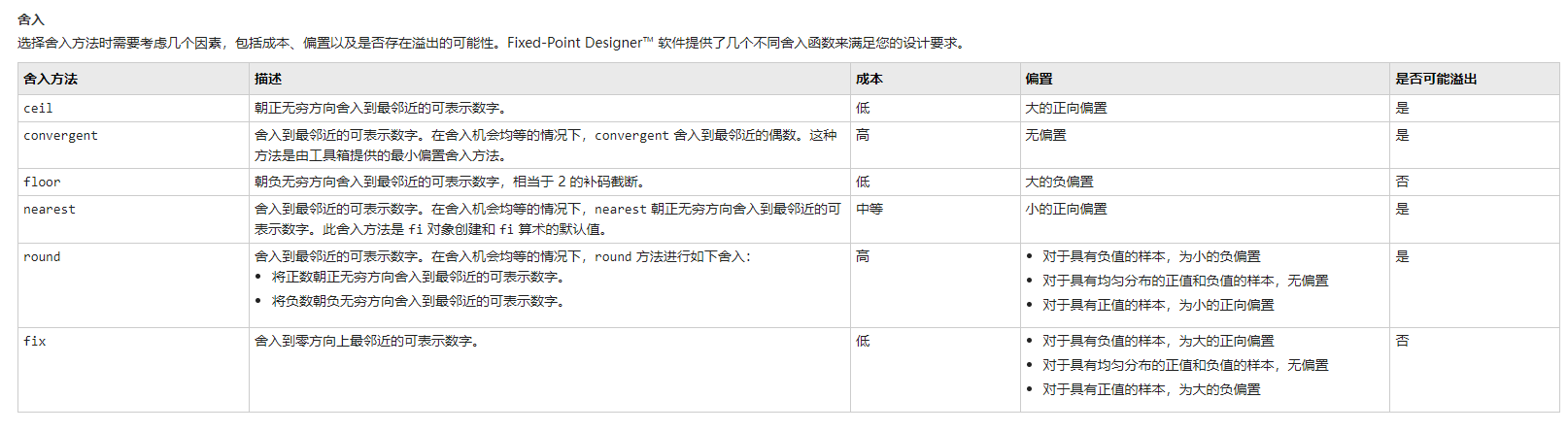
本文介绍了一种名为“Embarrassingly Easy Text-to-Speech(E2 TTS)”的文本转语音系统。
该系统通过将输入文本转换为填充标记字符序列,并基于音频填充值任务训练流匹配基mel频谱生成器,实现了人类水平的自然度和最先进的说话人相似性和可理解性。
与许多先前的工作不同,它不需要额外组件或复杂技术的支持。尽管简单,但E2 TTS在零样本TTS能力方面取得了与先前工作相当甚至超越的效果,包括Voicebox和NaturalSpeech 3。
此外,E2 TTS的简单性也允许灵活地表示输入。本文还提出了几种E2 TTS变体以提高推理时的可用性。
地址:https://arxiv.org/pdf/2406.18009
代码:https://aka.ms/e2tts/
方法改进
相较于传统的语音合成方法,E2 TTS 的改进主要体现在以下两个方面:
使用字符序列替代音素序列:E2 TTS 将音素序列替换为字符序列,避免了需要进行音素转写、音素对齐和音素时长模型等额外处理的需求。
增加了两个扩展功能:第一个扩展功能(E2 TTS X1)消除了在推理中对音频提示进行转录的需求;第二个扩展功能(E2 TTS X2)允许用户在句子中的特定单词上明确指定发音。
解决的问题
E2 TTS 主要解决了以下几个问题:
零样本语音合成:传统的语音合成方法通常需要大量的样本数据进行训练,而 E2 TTS 可以在没有样本数据的情况下进行语音合成。
简化模型结构:E2 TTS 通过使用字符序列替代音素序列,简化了模型结构,减少了额外的处理需求。
支持新的单词发音:E2 TTS X2 扩展功能允许用户在句子中的特定单词上明确指定发音,从而满足个性化需求。
论文实验
E2 TTS模型使用了Transformer架构和U-Net风格的skip连接,具有出色的零样本语音合成能力。
实验数据和模型配置。
实验数据来源于Libriheavy和LibriSpeech-PC等数据集,包括50,000小时的英语语音和200,000小时的额外数据。模型采用了Transformer架构,其中包括24层、16个注意力头、1024维嵌入维度、4096维线性层维度和0.1的dropout率。该模型用于将log mel滤波器组特征转换为波形,使用的BigVGAN-vocoder模型在测试中表现良好。
评估数据和指标。
评估数据来源于LibriSpeech-PC数据集,包括1,132个音频样本和39个演讲者。评估指标包括单词错误率(WER)和相似度评分(SIM-o)。此外,还进行了客观和主观评估,分别通过计算平均值来得出结果。
实验结果和分析。
作者对四种模型进行了比较,包括Voicebox、VALL-E和NaturalSpeech 3。结果显示,E2 TTS模型在所有方面都优于这些基准模型,包括更好的WER、更高的自然度和更好的说话人相似度。此外,E2 TTS还可以扩展到不同的应用场景,例如不需要音频转录和指定新术语的发音。最后,作者还分析了E2 TTS模型的行为,包括训练进度、音频提示长度和改变语速的影响









![[计网初识1] TCP/UDP](https://img-blog.csdnimg.cn/20200420235146636.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzE0Mjc5Nw==,size_16,color_FFFFFF,t_70#pic_center)