作者:运维有术星主 随着人工智能、机器学习、AI 大模型技术的迅猛发展,我们对计算资源的需求也在不断攀升。特别是对于需要处理大规模数据和复杂算法的 AI 大模型,GPU 资源的使用变得至关重要。对于运维工程师而言,掌握如何在 Kubernetes 集群上管理和配置 GPU 资源,以及如何高效部署依赖这些资源的应用,已成为一项不可或缺的技能。
今天,我将带领大家深入了解如何在 KubeSphere 平台上,利用 Kubernetes 强大的生态和工具,实现 GPU 资源的管理和应用部署。以下是本文将要探讨的三个核心主题:
- 集群扩容与 GPU 节点集成:我们将通过 KubeKey 工具,扩展 Kubernetes 集群并增加具备 GPU 能力的 Worker 节点,为 AI 应用提供必要的硬件支持。
- GPU 资源的 Kubernetes 集成:使用 Helm 安装和配置 NVIDIA GPU Operator,这是 NVIDIA 官方提供的一个解决方案,旨在简化 Kubernetes 集群中 GPU 资源的调用和管理。
- 实战部署:Ollama 大模型管理工具:我们将在 KubeSphere 上部署 Ollama,一个专为 AI 大模型设计的管理工具,以验证 GPU 资源是否能够被正确调度和高效使用。
通过阅读本文,您将获得 Kubernetes 上 管理 GPU 资源的知识和技巧,帮助您在云原生环境中,充分利用 GPU 资源,推动 AI 应用的快速发展。
KubeSphere 最佳实战「2024」 系列文档的实验环境硬件配置和软件信息如下:
实战服务器配置(架构1:1复刻小规模生产环境,配置略有不同)
| 主机名 | IP | CPU | 内存 | 系统盘 | 数据盘 | 用途 |
|---|---|---|---|---|---|---|
| ksp-registry | 192.168.9.90 | 4 | 8 | 40 | 200 | Harbor 镜像仓库 |
| ksp-control-1 | 192.168.9.91 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-2 | 192.168.9.92 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-control-3 | 192.168.9.93 | 4 | 8 | 40 | 100 | KubeSphere/k8s-control-plane |
| ksp-worker-1 | 192.168.9.94 | 4 | 16 | 40 | 100 | k8s-worker/CI |
| ksp-worker-2 | 192.168.9.95 | 4 | 16 | 40 | 100 | k8s-worker |
| ksp-worker-3 | 192.168.9.96 | 4 | 16 | 40 | 100 | k8s-worker |
| ksp-storage-1 | 192.168.9.97 | 4 | 8 | 40 | 300+ | ElasticSearch/Ceph/Longhorn/NFS/ |
| ksp-storage-2 | 192.168.9.98 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-storage-3 | 192.168.9.99 | 4 | 8 | 40 | 300+ | ElasticSearch//Ceph/Longhorn |
| ksp-gpu-worker-1 | 192.168.9.101 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla M40 24G) |
| ksp-gpu-worker-2 | 192.168.9.102 | 4 | 16 | 40 | 100 | k8s-worker(GPU NVIDIA Tesla P100 16G) |
| ksp-gateway-1 | 192.168.9.103 | 2 | 4 | 40 | 自建应用服务代理网关/VIP:192.168.9.100 | |
| ksp-gateway-2 | 192.168.9.104 | 2 | 4 | 40 | 自建应用服务代理网关/VIP:192.168.9.100 | |
| ksp-mid | 192.168.9.105 | 4 | 8 | 40 | 100 | 部署在 k8s 集群之外的服务节点(Gitlab 等) |
| 合计 | 15 | 56 | 152 | 600 | 2000 |
实战环境涉及软件版本信息
- 操作系统:openEuler 22.03 LTS SP3 x86_64
- KubeSphere:v3.4.1
- Kubernetes:v1.28.8
- KubeKey: v3.1.1
- Containerd:1.7.13
- NVIDIA GPU Operator:v24.3.0
- NVIDIA 显卡驱动:550.54.15
1. 前置条件
1.1 准备带有显卡的 Worker 节点
鉴于资源和成本的限制,我没有高端物理主机和显卡来做实验。只能增加两台配备入门级 GPU 显卡的虚拟机,作为集群的 Worker 节点。
- 节点 1,配置 GPU NVIDIA Tesla M40 24G 显卡。唯一优点 24G 大显存,性能低。
- 节点 2,配置 GPU NVIDIA Tesla P100 16G 显卡。显存小,但是速度快于 M40、P40 等显卡。
尽管这些显卡在性能上不及高端型号,但它们足以应对大多数学习和开发任务,在资源有限的情况下,这样的配置为我提供了宝贵的实践机会,让我能够深入探索 Kubernetes 集群中 GPU 资源的管理和调度策略。
1.2 操作系统初始化配置
请参考 Kubernetes 集群节点 openEuler 22.03 LTS SP3 系统初始化指南,完成操作系统初始化配置。
初始化配置指南中没有涉及操作系统升级的任务,在能联网的环境初始化系统的时候一定要升级操作系统,然后重启节点。
2. 使用 KubeKey 扩容 GPU Worker 节点
接下来我们使用 KubeKey 将新增加的 GPU 节点加入到已有的 Kubernetes 集群,参考官方说明文档,整个过程比较简单,仅需两步。
- 修改 KubeKey 部署时使用的集群配置文件
- 执行增加节点的命令
2.1 修改集群配置文件
在 Control-1 节点,切换到部署用的 kubekey 目录,修改原有的集群配置文件,我们实战中使用的名字为 ksp-v341-v1288.yaml,请根据实际情况修改 。
主要修改点:
- spec.hosts 部分:增加新的 worker 节点的信息。
- spec.roleGroups.worker 部分:增加新的 worker 节点的信息
修改后的示例如下:
apiVersion: kubekey.kubesphere.io/v1alpha2
kind: Cluster
metadata:
name: opsxlab
spec:
hosts:
......(保持不变)
- {name: ksp-gpu-worker-1, address: 192.168.9.101, internalAddress: 192.168.9.101, user: root, password: "OpsXlab@2024"}
- {name: ksp-gpu-worker-2, address: 192.168.9.102, internalAddress: 192.168.9.102, user: root, password: "OpsXlab@2024"}
roleGroups:
......(保持不变)
worker:
......(保持不变)
- ksp-gpu-worker-1
- ksp-gpu-worker-2
# 下面的内容保持不变2.2 使用 KubeKey 增加节点
在增加节点之前,我们再确认一下当前集群的节点信息。
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 24h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 24h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 24h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 24h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 24h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 24h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13接下来我们执行下面的命令,使用修改后的配置文件将新增的 Worker 节点加入集群。
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yaml上面的命令执行后,KubeKey 先检查部署 Kubernetes 的依赖及其它配置是否符合要求。通过检查后,系统将提示您确认安装。输入 yes 并按 ENTER 继续部署。
部署完成需要大约 5 分钟左右,具体时间看网速、机器配置、增加的节点数量。
部署完成后,您应该会在终端上看到类似于下面的输出。
......
19:29:26 CST [AutoRenewCertsModule] Generate k8s certs renew script
19:29:27 CST success: [ksp-control-2]
19:29:27 CST success: [ksp-control-1]
19:29:27 CST success: [ksp-control-3]
19:29:27 CST [AutoRenewCertsModule] Generate k8s certs renew service
19:29:29 CST success: [ksp-control-3]
19:29:29 CST success: [ksp-control-2]
19:29:29 CST success: [ksp-control-1]
19:29:29 CST [AutoRenewCertsModule] Generate k8s certs renew timer
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST success: [ksp-control-3]
19:29:30 CST [AutoRenewCertsModule] Enable k8s certs renew service
19:29:30 CST success: [ksp-control-3]
19:29:30 CST success: [ksp-control-2]
19:29:30 CST success: [ksp-control-1]
19:29:30 CST Pipeline[AddNodesPipeline] execute successfully3. 扩容后集群状态验证
3.1 KubeSphere 管理控制台验证集群状态
我们打开浏览器访问 Control-1 节点的 IP 地址和端口 30880,登陆 KubeSphere 管理控制台的登录页面。
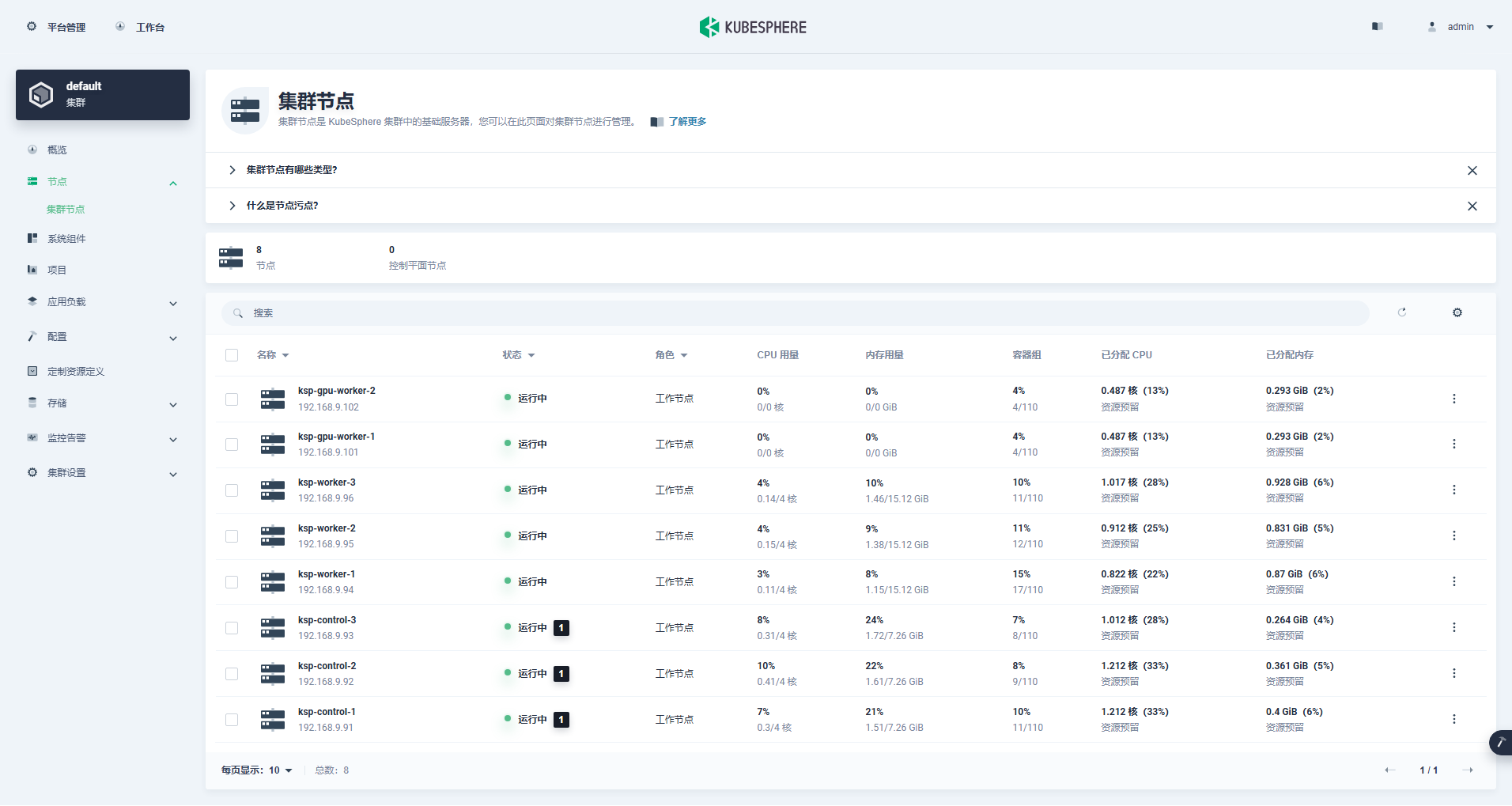
进入集群管理界面,单击左侧「节点」菜单,点击「集群节点」查看 Kubernetes 集群可用节点的详细信息。
3.2 Kubectl 命令行验证集群状态
- 查看集群节点信息
在 Control-1 节点运行 kubectl 命令获取 Kubernetes 集群的节点信息。
kubectl get nodes -o wide在输出结果中可以看到,当前的 Kubernetes 集群有 8个节点,并详细展示每个节点的名字、状态、角色、存活时间、Kubernetes 版本号、内部 IP、操作系统类型、内核版本和容器运行时等信息。
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ksp-control-1 Ready control-plane 25h v1.28.8 192.168.9.91 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-2 Ready control-plane 25h v1.28.8 192.168.9.92 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-control-3 Ready control-plane 25h v1.28.8 192.168.9.93 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-1 Ready worker 59m v1.28.8 192.168.9.101 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-gpu-worker-2 Ready worker 59m v1.28.8 192.168.9.102 <none> openEuler 22.03 (LTS-SP3) 5.10.0-199.0.0.112.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-1 Ready worker 25h v1.28.8 192.168.9.94 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-2 Ready worker 25h v1.28.8 192.168.9.95 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13
ksp-worker-3 Ready worker 25h v1.28.8 192.168.9.96 <none> openEuler 22.03 (LTS-SP3) 5.10.0-182.0.0.95.oe2203sp3.x86_64 containerd://1.7.13至此,我们完成了利用 Kubekey 在现有的 3个 Master 节点和 3个 Worker 节点组成的 Kubernetes 集群中增加 2 个 Worker 节点的全部任务。
接下来我们安装 NVIDIA 官方出品的 NVIDIA GPU Operator,实现 K8s 调度 Pod 使用 GPU 资源。
4. 安装配置 NVIDIA GPU Operator
4.1 安装 NVIDIA 显卡驱动
NVIDIA GPU Operator 支持自动安装显卡驱动,但是只 CentOS 7、8 和 Ubuntu 20.04、22.04 等版本,并不支持 openEuler,所以需要手工安装显卡驱动。
请参考 KubeSphere 最佳实战:openEuler 22.03 LTS SP3 安装 NVIDIA 显卡驱动,完成显卡驱动安装。
4.2 前提条件
Node Feature Discovery (NFD) 检测功能检查。
$ kubectl get nodes -o json | jq '.items[].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'上面的命令执行结果为 true, 说明 NFD 已经在集群中运行。如果NFD已经在集群中运行,那么在安装 Operator 时必须禁用部署 NFD。
说明: 使用 KubeSphere 部署的 K8s 集群默认不会安装配置 NFD。
4.3 安装 NVIDIA GPU Operator
- 添加 NVIDIA Helm repository
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update- 安装 GPU Operator
使用默认配置文件,禁用自动安装显卡驱动功能,安装 GPU Operator。
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false注意: 由于安装的镜像比较大,所以初次安装过程中可能会出现超时的情形,请检查你的镜像是否成功拉取!可以考虑使用离线安装解决该类问题。
- 使用自定义 values 安装 GPU Operator(可选,离线或是自定义配置时使用)
helm install -f gpu-operator-values.yaml -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false正确执行输出结果如下:
$ helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false
NAME: gpu-operator
LAST DEPLOYED: Tue Jul 2 21:40:29 2024
NAMESPACE: gpu-operator
STATUS: deployed
REVISION: 1
TEST SUITE: None4.4 命令行检查 GPU Operator 部署状态
执行安装 GPU Operator 的命令后请耐心等待所有镜像成功拉取,所有 Pod 都处于 Running 状态。
- 命令行检查 pods 状态
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-czdf5 1/1 Running 0 15m
gpu-feature-discovery-q9qlm 1/1 Running 0 15m
gpu-operator-67c68ddccf-x29pm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-gc-57457b6d8f-zjqhr 1/1 Running 0 15m
gpu-operator-node-feature-discovery-master-5fb74ff754-fzbzm 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-68459 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-74ps5 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-dpmg9 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-jvk4t 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-k5kwq 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-ll4bk 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-p4q5q 1/1 Running 0 15m
gpu-operator-node-feature-discovery-worker-rmk99 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-9zcnj 1/1 Running 0 15m
nvidia-container-toolkit-daemonset-kcz9g 1/1 Running 0 15m
nvidia-cuda-validator-l8vjb 0/1 Completed 0 14m
nvidia-cuda-validator-svn2p 0/1 Completed 0 13m
nvidia-dcgm-exporter-9lq4c 1/1 Running 0 15m
nvidia-dcgm-exporter-qhmkg 1/1 Running 0 15m
nvidia-device-plugin-daemonset-7rvfm 1/1 Running 0 15m
nvidia-device-plugin-daemonset-86gx2 1/1 Running 0 15m
nvidia-operator-validator-csr2z 1/1 Running 0 15m
nvidia-operator-validator-svlc4 1/1 Running 0 15m- 查看节点可分配的 GPU 资源
$ kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7
Capacity:
cpu: 4
ephemeral-storage: 35852924Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 15858668Ki
nvidia.com/gpu: 1
pods: 110说明: 重点关注
nvidia.com/gpu:字段的值。
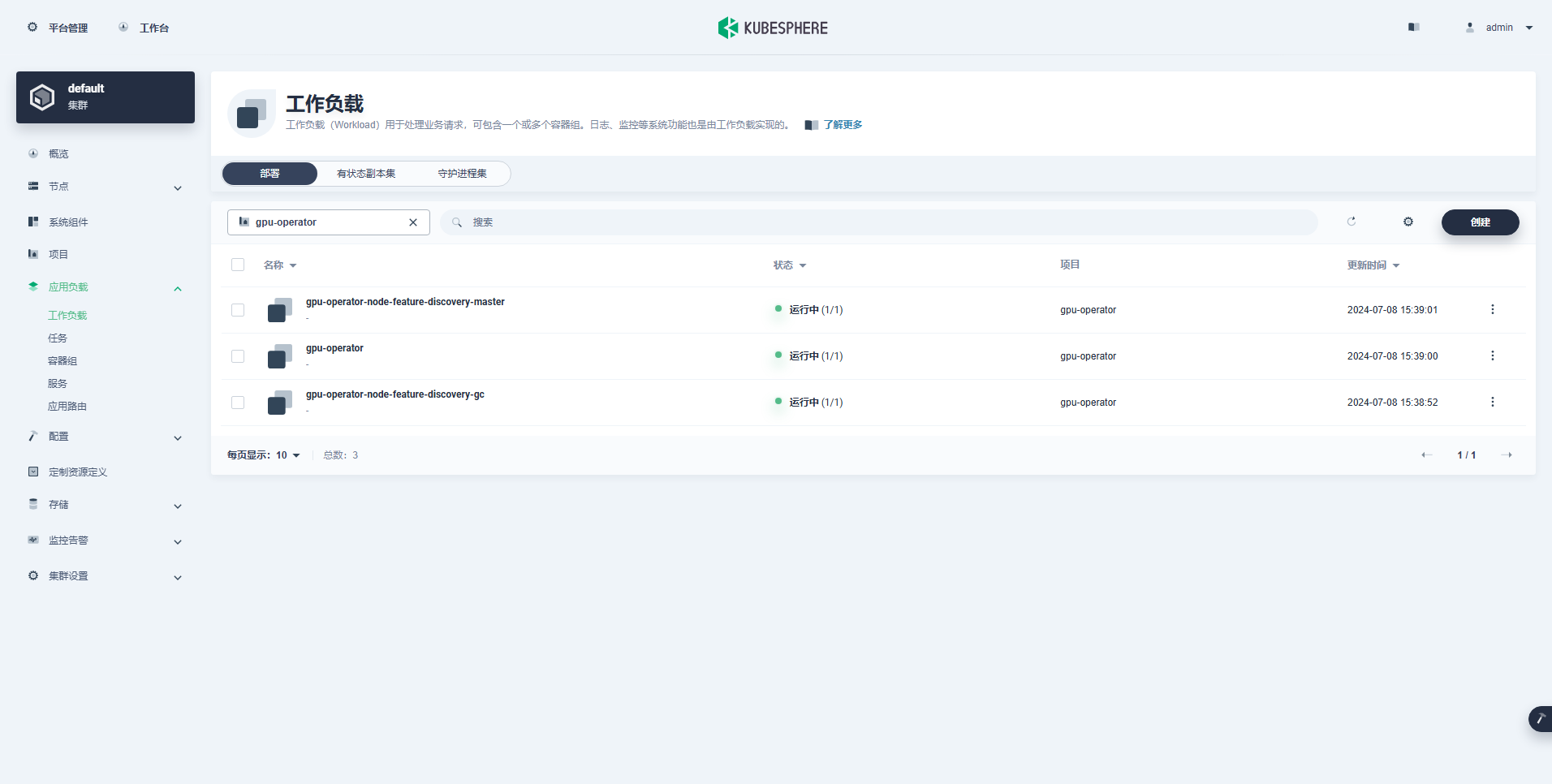
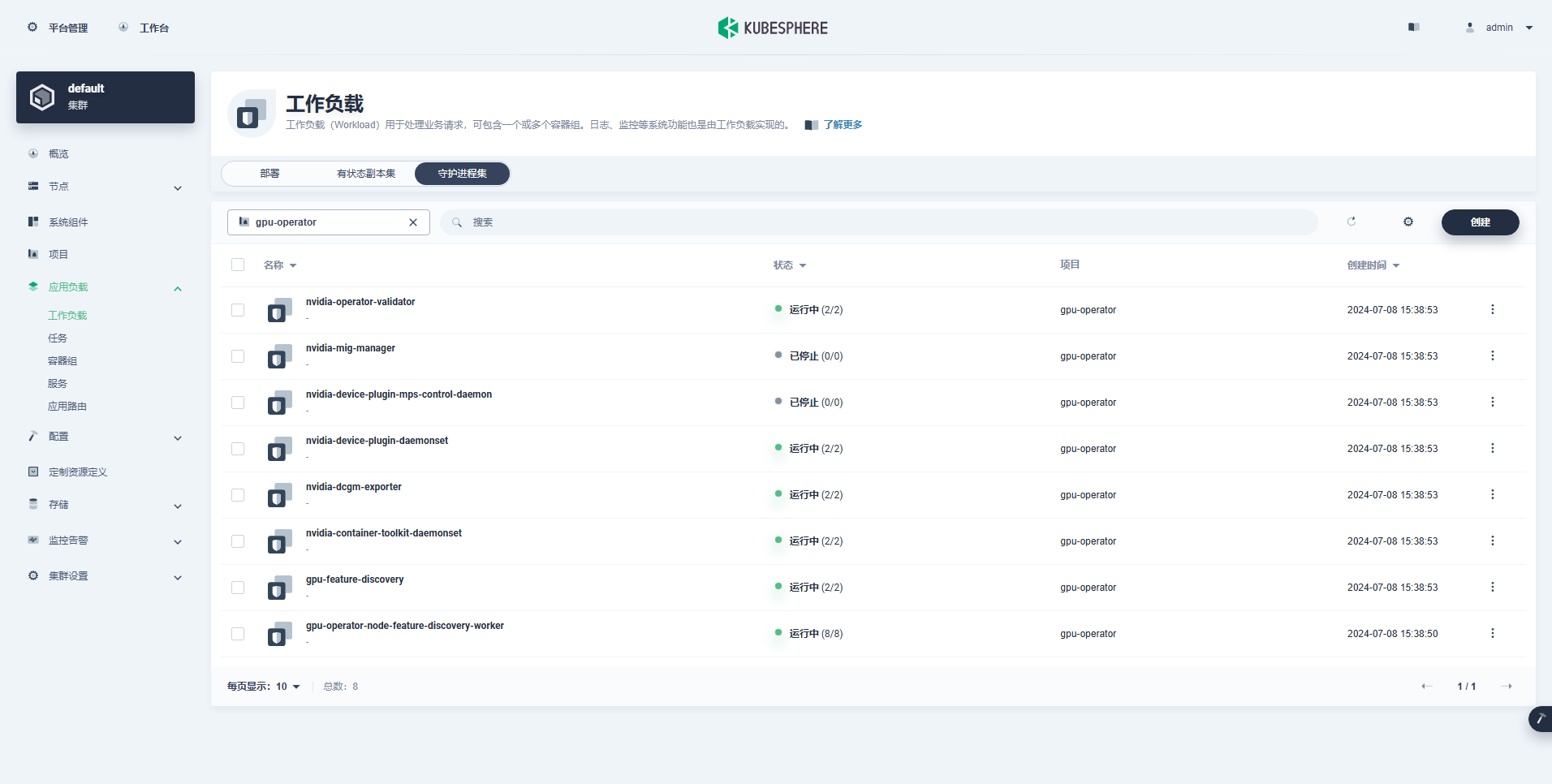
4.5 KubeSphere 控制台查看 GPU Operator 部署状态
创建成功的工作负载如下:
- Deployments
- Daemonsets
5. GPU 功能验证测试
5.1 测试示例1-验证测试 CUDA
GPU Operator 正确安装完成后,使用 CUDA 基础镜像,测试 K8s 是否能正确创建使用 GPU 资源的 Pod。
- 创建资源清单文件,
vi cuda-ubuntu.yaml
apiVersion: v1
kind: Pod
metadata:
name: cuda-ubuntu2204
spec:
restartPolicy: OnFailure
containers:
- name: cuda-ubuntu2204
image: "nvcr.io/nvidia/cuda:12.4.0-base-ubuntu22.04"
resources:
limits:
nvidia.com/gpu: 1
command: ["nvidia-smi"]- 创建资源
kubectl apply -f cuda-ubuntu.yaml- 查看创建的资源
从结果中可以看到 pod 创建在了 ksp-gpu-worker-2 节点(该节点显卡型号 Tesla P100-PCIE-16GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
cuda-ubuntu2204 0/1 Completed 0 73s 10.233.99.15 ksp-gpu-worker-2 <none> <none>
ollama-79688d46b8-vxmhg 1/1 Running 0 47m 10.233.72.17 ksp-gpu-worker-1 <none> <none>- 查看 Pod 日志
kubectl logs pod/cuda-ubuntu2204正确执行输出结果如下:
$ kubectl logs pod/cuda-ubuntu2204
Mon Jul 8 11:10:59 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla P100-PCIE-16GB Off | 00000000:00:10.0 Off | 0 |
| N/A 40C P0 26W / 250W | 0MiB / 16384MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+- 清理测试资源
kubectl apply -f cuda-ubuntu.yaml5.2 测试示例 2-官方 GPU Applications 示例
执行一个简单的 CUDA 示例,用于将两个向量(vectors)相加。
- 创建资源清单文件,
vi cuda-vectoradd.yaml
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1- 执行命令创建 Pod
$ kubectl apply -f cuda-vectoradd.yaml- 查看 Pod 执行结果
Pod 创建成功,启动后会运行 vectorAdd 命令并退出。
$ kubectl logs pod/cuda-vectoradd正确执行输出结果如下:
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done- 清理测试资源
kubectl delete -f cuda-vectoradd.yaml6. KubeSphere 部署 Ollama
通过上面的验证测试,证明可以在 K8s 集群上创建使用 GPU 的 Pod 资源,接下来我们结合实际使用需求,利用 KubeSphere 在 K8s 集群创建一套大模型管理工具 Ollama。
6.1 创建部署资源清单
本示例属于简单测试,存储选择了 hostPath 模式,实际使用中请替换为存储类或是其他类型的持久化存储。
- 创建资源清单,
vi deploy-ollama.yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePort特殊说明: KubeSphere 的管理控制台支持图形化配置 Deployment 等资源使用 GPU 资源,配置示例如下,感兴趣的朋友可以自行研究。
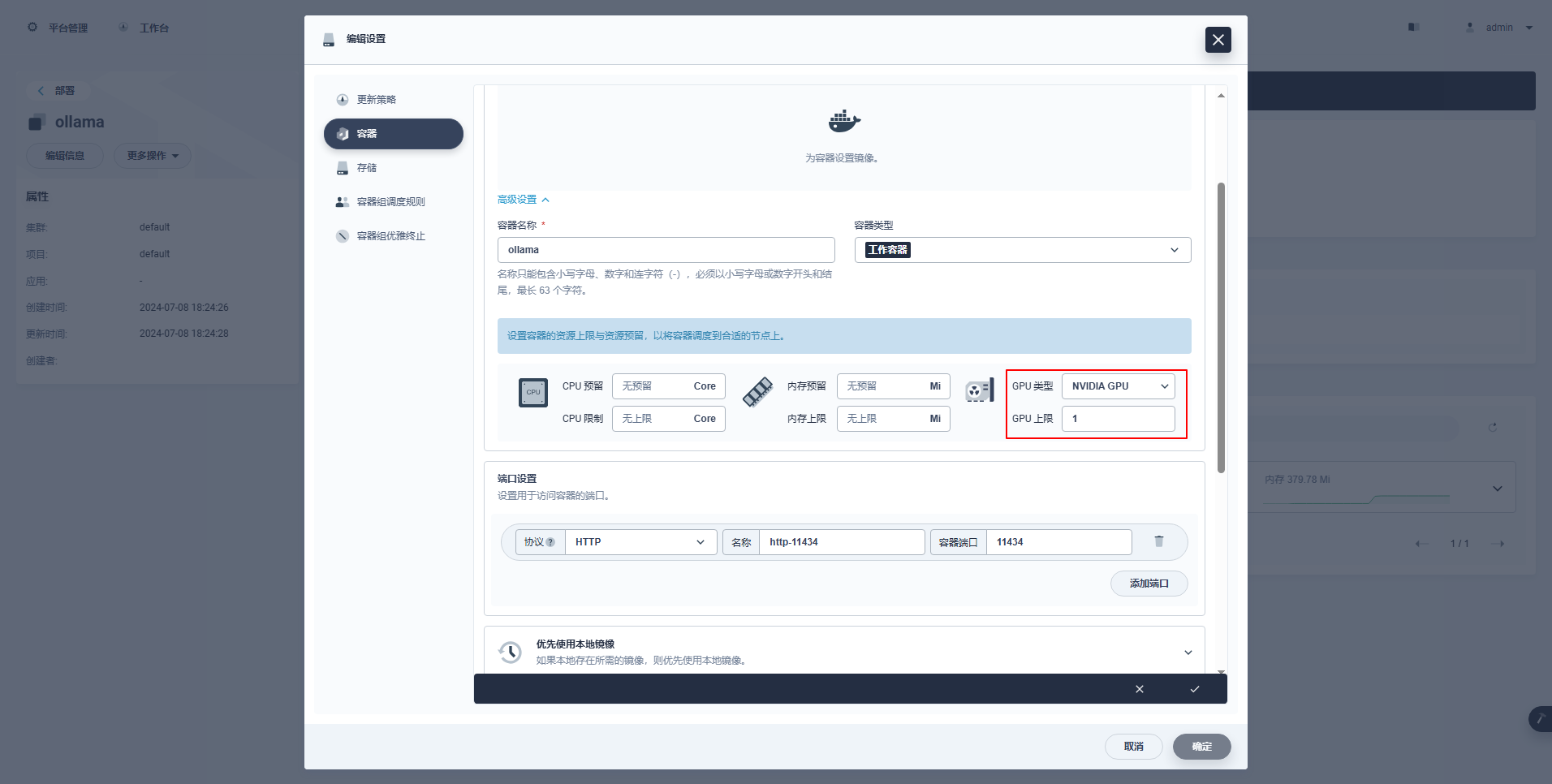
6.2 部署 Ollama 服务
- 创建 Ollama
kubectl apply -f deploy-ollama.yaml- 查看 Pod 创建结果
从结果中可以看到 pod 创建在了 ksp-gpu-worker-1 节点(该节点显卡型号 Tesla M40 24GB)。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k 1/1 Running 0 12s 10.233.72.17 ksp-gpu-worker-1 <none> <none>- 查看容器 log
[root@ksp-control-1 ~]# kubectl logs ollama-79688d46b8-vxmhg
2024/07/08 18:24:27 routes.go:1064: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST:http://0.0.0.0:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE: OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS:/root/.ollama/models OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://*] OLLAMA_RUNNERS_DIR: OLLAMA_SCHED_SPREAD:false OLLAMA_TMPDIR: ROCR_VISIBLE_DEVICES:]"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:730 msg="total blobs: 5"
time=2024-07-08T18:24:27.829+08:00 level=INFO source=images.go:737 msg="total unused blobs removed: 0"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=routes.go:1111 msg="Listening on [::]:11434 (version 0.1.48)"
time=2024-07-08T18:24:27.830+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2414166698/runners
time=2024-07-08T18:24:32.454+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60101]"
time=2024-07-08T18:24:32.567+08:00 level=INFO source=types.go:98 msg="inference compute" id=GPU-9e48dc13-f8f1-c6bb-860f-c82c96df22a4 library=cuda compute=5.2 driver=12.4 name="Tesla M40 24GB" total="22.4 GiB" available="22.3 GiB"6.3 拉取 Ollama 使用的大模型
- Ollama 拉取模型
本示例为了节省时间,采用阿里开源的 qwen2 1.5b 小尺寸模型作为测试模型。
kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b正确执行输出结果如下:
[root@ksp-control-1 ~]# kubectl exec -it ollama-79688d46b8-vxmhg -- ollama pull qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕█████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕█████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕█████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕█████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕█████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success- 查看模型文件的内容
在 ksp-gpu-worker-1 节点执行下面的查看命令
$ ls -R /data/openebs/local/ollama/
/data/openebs/local/ollama/:
id_ed25519 id_ed25519.pub models
/data/openebs/local/ollama/models:
blobs manifests
/data/openebs/local/ollama/models/blobs:
sha256-405b56374e02b21122ae1469db646be0617c02928fd78e246723ebbb98dbca3e
sha256-62fbfd9ed093d6e5ac83190c86eec5369317919f4b149598d2dbb38900e9faef
sha256-c156170b718ec29139d3653d40ed1986fd92fb7e0959b5c71f3c48f62e6636f4
sha256-c9f5e9ffbc5f14febb85d242942bd3d674a8e4c762aaab034ec88d6ba839b596
sha256-f02dd72bb2423204352eabc5637b44d79d17f109fdb510a7c51455892aa2d216
/data/openebs/local/ollama/models/manifests:
registry.ollama.ai
/data/openebs/local/ollama/models/manifests/registry.ollama.ai:
library
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library:
qwen2
/data/openebs/local/ollama/models/manifests/registry.ollama.ai/library/qwen2:
1.5b6.4 模型能力测试
- 调用接口测试
curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'- 测试结果
$ curl http://192.168.9.91:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "用20个字,介绍你自己" }
]
}'
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.011798927Z","message":{"role":"assistant","content":"我"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.035291669Z","message":{"role":"assistant","content":"是一个"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.06360233Z","message":{"role":"assistant","content":"人工智能"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.092411266Z","message":{"role":"assistant","content":"助手"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.12016935Z","message":{"role":"assistant","content":","},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.144921623Z","message":{"role":"assistant","content":"专注于"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.169803961Z","message":{"role":"assistant","content":"提供"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.194796364Z","message":{"role":"assistant","content":"信息"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.21978104Z","message":{"role":"assistant","content":"和"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.244976103Z","message":{"role":"assistant","content":"帮助"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.270233992Z","message":{"role":"assistant","content":"。"},"done":false}
{"model":"qwen2:1.5b","created_at":"2024-07-08T09:54:48.29548561Z","message":{"role":"assistant","content":""},"done_reason":"stop","done":true,"total_duration":454377627,"load_duration":1535754,"prompt_eval_duration":36172000,"eval_count":12,"eval_duration":287565000}6.5 查看 GPU 分配信息
- 查看 Worker 节点已分配的 GPU 资源
$ kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 487m (13%) 2 (55%)
memory 315115520 (2%) 800Mi (5%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
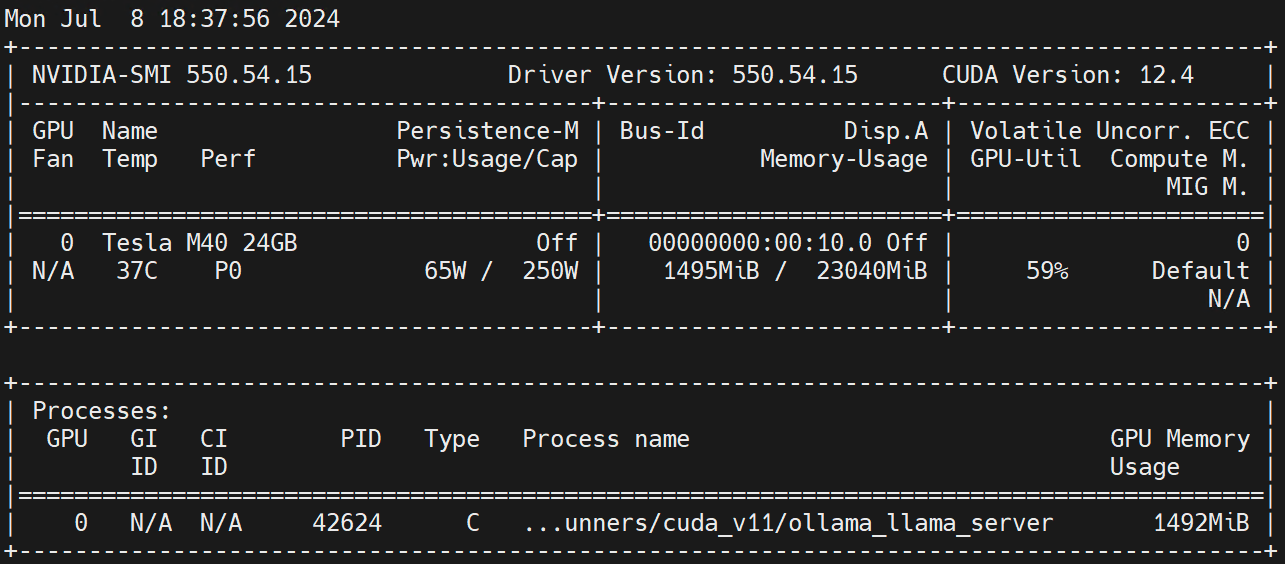
nvidia.com/gpu 1 1- Ollama 运行时物理 GPU 使用情况
在 Worker 节点上执行 nvidia-smi -l 观察 GPU 的使用情况。
免责声明:
- 笔者水平有限,尽管经过多次验证和检查,尽力确保内容的准确性,但仍可能存在疏漏之处。敬请业界专家大佬不吝指教。
- 本文所述内容仅通过实战环境验证测试,读者可学习、借鉴,但严禁直接用于生产环境。由此引发的任何问题,作者概不负责!
本文由博客一文多发平台 OpenWrite 发布!

![[C++初阶]list类的初步理解](https://i-blog.csdnimg.cn/direct/64dd9700e866428e9a418ea57a03c155.png)