获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读
本文介绍了一种名为“LLaMA-MoE”的方法,通过将现有的大型语言模型(LLMs)转化为混合专家网络(MoE),从而解决了训练MoE时遇到的数据饥饿和不稳定性问题。该方法基于著名的LLaMA-2 7B模型,并将其参数分为多个专家,然后对转换后的MoE模型进行持续预训练以进一步提高性能。实验结果表明,在使用200B个标记进行训练后,LLaMA-MoE-3.5B模型在激活参数相似的情况下显著优于密集模型。
下载地址和项目代码见文末
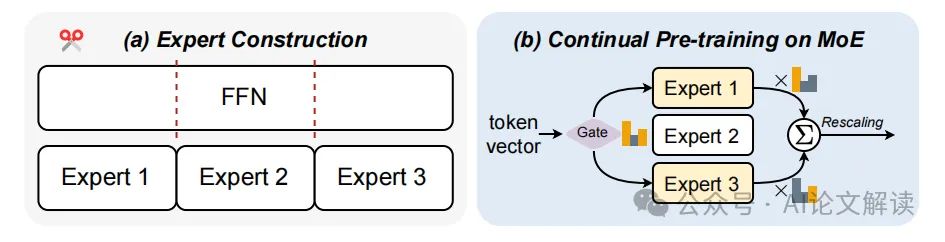
图1:构建LLaMA-MoE模型的主要框架。(a)LLaMA中的原始ffn被分为不同的专家。(b)在转换后的LLaMA-MoE中,隐藏状态是由部分选择的专家而不是所有的专家进行处理的。
专家构建
1. 概述
专家构建是将原始Feed-Forward Networks (FFNs)的参数划分为多个专家。传统的FFN层包含大量参数,这些参数可以被分解为多个子集,每个子集称为一个专家。通过这种方法,可以减少每次计算所需的激活参数数量,从而在保证模型性能的同时显著降低计算成本。
2. 参数划分方法
在构建专家时,常用的两种方法是独立神经元划分和共享神经元划分。
独立神经元划分:这种方法将FFN中的神经元均匀地划分为多个子集,每个子集独立组成一个专家。例如,可以通过随机划分或基于聚类的方法来实现这种划分。随机划分是将所有神经元随机分配给不同的专家,而聚类方法则基于神经元的特征将其分配给不同的专家。
共享神经元划分:与独立神经元划分不同,共享神经元划分允许多个专家共享部分神经元。这种方法可以通过评估神经元的重要性来决定哪些神经元需要共享。共享神经元的目标是保留模型的表示能力,同时减少计算资源的消耗。
3. 实践案例
在LLaMA-MoE模型的构建过程中,研究人员尝试了多种参数划分方法,最终发现随机划分方法(IndependentRandom)在保持模型性能方面效果最佳。这种方法简单而高效,有助于平衡不同专家之间的负载,避免某些专家过度频繁使用而其他专家很少被激活的问题。
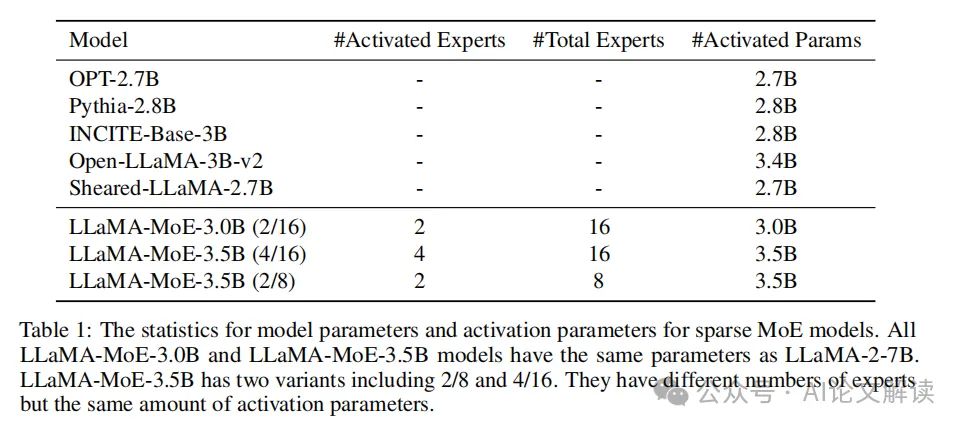
持续预训练
1. 必要性
由于转换后的MoE模型在结构上与原始的密集模型(dense model)有所不同,直接使用转换后的模型可能会导致性能下降。为了恢复和提升模型的语言建模能力,必须对转换后的MoE模型进行持续预训练。
2. 预训练策略
在持续预训练阶段,研究人员使用了两种主要的数据采样策略:静态数据采样和动态数据采样。
静态数据采样:使用固定的采样权重,从预定义的数据集中提取训练数据。这种方法简单直接,但可能无法充分适应不同训练阶段的需求。
动态数据采样:根据模型在训练过程中的表现动态调整采样权重,以更好地优化模型性能。尽管这种方法可以提高训练效率,但也增加了计算复杂度。
3. 数据过滤
为了提高训练数据的质量,研究人员在预训练前对数据进行了过滤,去除了约50%的广告内容和约15%的非流利文本。这一策略有助于加快模型的收敛速度,提高训练效果。
增强推理能力
1. 激活部分模型参数
在处理具体任务时,MoE模型通过激活部分模型参数来提高推理能力。每个输入token仅激活与其最相关的几个专家,从而减少了不必要的计算。这种稀疏激活方式不仅提高了计算效率,还能在保持高性能的同时降低推理成本。
2. 性能提升
实验证明,经过200B tokens的预训练后,LLaMA-MoE-3.5B模型在多个下游任务上显著优于具有相同激活参数的密集模型。这一结果表明,通过适当的专家划分和持续预训练,MoE模型能够在保持语言能力的同时显著提升推理性能。
提高可解释性
1. 部分参数激活
由于每次仅有部分参数被激活,MoE模型在决策过程中的激活路径更加清晰。这使得研究人员能够更容易地追踪和解释模型的行为,了解模型是如何处理和响应不同输入的。
2. 实例分析
在实验中,研究人员观察到深层网络层比浅层网络层有更强的路由偏好,这意味着深层网络层捕捉更多任务特定的特征,而浅层网络层则更关注通用特征。这一发现有助于进一步优化专家划分策略,提高模型的整体性能。
降低计算成本
MoE(Mixture-of-Experts)模型相比传统的密集模型,通过只激活部分参数来处理输入,可以显著降低计算成本。传统的密集模型在处理每一个输入时都需要使用所有参数,这样随着模型容量的增加,计算成本也会急剧上升。而MoE模型则通过引入专家网络和门控网络,只激活一部分专家,从而降低了计算成本。
例如,LLaMA-MoE模型在构建过程中,将原始LLaMA模型的FFN(Feed-Forward Network)分割成多个专家网络。这种分割方法在维持模型性能的前提下,显著减少了需要激活的参数量,进而减少了计算开销。通过训练200B tokens,LLaMA-MoE-3.5B模型在激活参数量相当的情况下,显著优于类似的密集模型。
工程应用
MoE模型在需要高效推理的实际应用中展现出巨大的潜力。例如,在实时翻译和智能助手等场景中,计算成本的降低和推理效率的提高尤为重要。MoE模型可以根据输入动态选择合适的专家,从而实现快速而准确的推理。
以实时翻译为例,传统模型可能需要大量计算资源来处理复杂的语言转换,而MoE模型则能够通过激活少量专家,快速处理翻译任务,降低延迟并提高响应速度。同样地,在智能助手中,MoE模型可以根据用户的不同需求,动态分配计算资源,从而提供更加个性化和高效的服务。
理论研究
在模型架构设计和优化方面,MoE模型提供了新的思路和方法。传统模型在扩展过程中面临着计算成本急剧上升的挑战,而MoE模型通过稀疏激活部分参数,为解决这一问题提供了有效的途径。
研究表明,通过将密集模型的FFN参数随机分割成多个专家,并在每一层引入MoE模块,可以在保持模型性能的同时,减少计算开销。例如,独立随机拆分方法在实验中取得了最佳性能。与其他方法相比,该方法在专家和门控网络同时训练时,可以减少偏差,快速恢复模型的语言能力。
非重叠随机拆分法
非重叠随机拆分法通过随机拆分原始FFN的参数来构建专家,这种方法在实践中取得了显著效果。具体而言,给定一个包含所有中间神经元索引的集合U,通过将U随机分割成等大小的子集,从而构建出多个专家网络。这种方法能够在保持模型原有表示能力的基础上,减少计算复杂度。
在LLaMA-MoE模型的构建中,采用了非重叠随机拆分法,将FFN层中的中间神经元均匀分割成多个子集,每个子集对应一个专家网络。实验结果表明,该方法不仅在减少计算成本方面表现出色,还能够在持续预训练阶段快速恢复模型的语言能力。研究还发现,对专家输出进行重新缩放操作,可以显著提升MoE模型的性能。
通过这些研究和实践,MoE模型不仅在理论上提供了新的研究方向,还在实际应用中展现出了显著优势,为未来的大规模语言模型发展提供了重要参考。
共享神经元方法
共享神经元方法通过结构化裁剪来保留模型的部分表示能力,这种方法主要分为内部共享和外部共享两种策略。
1. 内部共享
内部共享策略主要是通过对神经元的重要性进行排序,并根据排序结果选择部分神经元进行共享。具体来说,首先对每个神经元进行重要性评估,可以使用一阶泰勒展开来度量每个神经元对损失变化的影响。然后,根据这些重要性分数,将最重要的神经元在不同的专家间共享,而其余神经元则分配给特定的专家。这种方法可以在不显著降低模型表示能力的情况下,实现有效的参数裁剪和共享。
2. 外部共享
外部共享策略则是在不同专家间直接共享部分神经元,而不进行重要性排序。这种方法通过预先定义的规则,将一些神经元设定为共享神经元,并将其余神经元分配给特定专家。这种方法的优点在于实现简单且计算开销较小,但可能在某些情况下无法达到内部共享策略所带来的性能提升。
数据采样权重
在训练过程中,数据采样权重的选择对模型的收敛速度和最终性能有重要影响。我们研究了静态和动态两种数据采样策略,以期获得最快的收敛速度和最佳的性能提升。
1. 静态采样
静态采样策略是指在训练过程中使用固定的采样权重,不随时间变化。这种方法的优点在于实现简单且计算开销较小,但可能无法适应数据分布的动态变化。
2. 动态采样
动态采样策略则会在训练过程中不断调整采样权重,以适应当前模型的训练需求和数据分布变化。具体来说,可以每隔一段时间(例如每2.5B tokens)调整一次采样权重,根据当前模型在不同数据域上的表现进行调整。这种方法虽然计算开销较大,但可以显著提升模型的收敛速度和性能。
数据过滤
为了加快模型的收敛速度,我们对训练数据进行了严格的质量过滤。具体来说,我们过滤掉了低质量的文本数据,如广告和不流畅的文本。
1. 广告过滤
广告通常包含大量冗余和无关信息,对模型的训练效果影响较大。我们通过特定的规则和算法,过滤掉了大约50%的广告数据,从而提升了数据集的整体质量。
2. 不流畅文本过滤
不流畅的文本通常表现为语法错误、拼写错误或逻辑不连贯。我们使用自然语言处理技术,过滤掉了大约15%的不流畅文本数据,从而进一步提升了模型的训练效率和效果。
实验设置
我们的实验在112个A100 (80G) GPU上进行训练,最大学习率为2e-4。训练数据集采用了SlimPajama,该数据集经过清洗和去重处理,包含627B tokens的数据。训练过程中,我们设置了全局批次大小为15M tokens,最大上下文长度为4096。在经过100步的热身训练后,学习率逐步下降到2e-5,采用余弦调度策略。整个训练过程中,我们对每个模型进行了13.6k步(约200B tokens)的训练。
通过以上方法和设置,我们成功构建并训练了LLaMA-MoE模型,并在多项任务中显著超越了同类模型。
实验结果
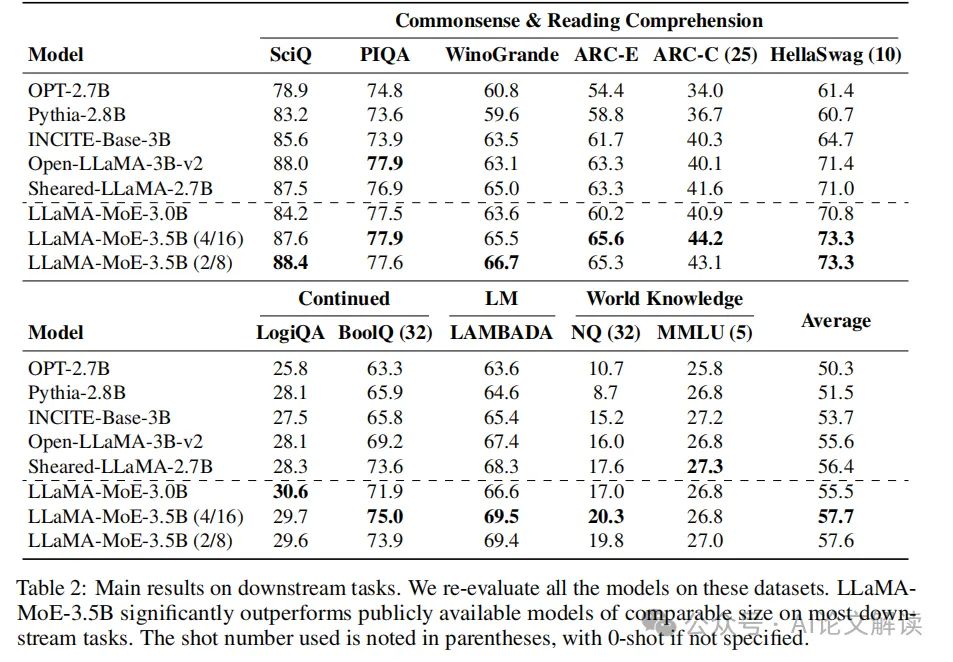
LLaMA-MoE-3.5B在多个下游任务上的表现显著优于其他具有相似激活参数的开源模型,如Sheared-LLaMA和Open-LLaMA-3B-v2。具体来说,LLaMA-MoE-3.5B(4/16)在各种任务中的平均分数超过了最具竞争力的模型Sheared-LLaMA 1.3分。此外,LLaMA-MoE-3.0B与Open-LLaMA-3B-v2表现相当。
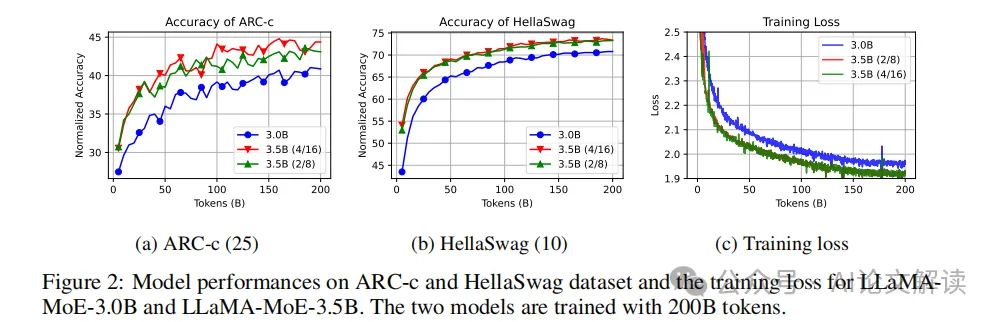
在ARC-c和HellaSwag数据集上的表现显示,随着训练过程的推进,模型的性能稳步提升。尽管ARC-c的结果波动较大,但HellaSwag提供了较为平滑的结果。训练损失方面,LLaMA-MoE-3.0B和LLaMA-MoE-3.5B分别收敛到1.95和1.90,这两个模型激活的参数较少,因此损失较LLaMA-2 7B略高。
专家构建方法对比
在实验中,我们比较了四种不同的专家构建方法。结果显示,非重叠随机拆分法(IndependentRandom)表现最佳。这种方法在训练200B tokens后,表现出最佳的平均分数。相比之下,共享神经元构建方法(SharingInter和SharingInner)在初始阶段表现良好,但随着训练的进行,其性能显著下降。
我们还进行了专家输出重新缩放的消融研究,结果表明,重新缩放操作显著提高了MoE模型的性能。这表明,专家构建方法对模型最终性能有着重要影响,而重新缩放操作则进一步提升了专家的表现能力。
数据采样策略
在数据采样策略的比较中,静态采样权重策略(StaticSheared)在性能上优于动态采样策略。尽管StaticSheared在训练损失上并不是最低的,但其在下游任务上的表现最佳。动态采样权重策略(DynamicUniform和DynamicLLaMA)在训练损失上波动较大,显示出不稳定性。
在数据采样权重的变化中,我们发现不同策略对不同领域的数据有不同的权重分配。静态采样策略的权重在整个训练过程中保持不变,而动态采样策略的权重则随着训练的进行逐渐变化。这表明,数据采样策略的选择对模型的训练效率和最终性能有着重要影响。
数据过滤策略
数据过滤策略在提高模型性能方面也起到了关键作用。通过过滤掉广告和不流畅文本,训练损失显著降低。具体而言,过滤掉广告数据的方法在下游任务上的表现不如过滤不流畅文本的方法。这可能是由于广告数据中的知识和信息较多,被过滤掉的数量较大,从而影响了模型的性能。
基于这些结果,我们最终选择使用过滤掉不流畅文本的数据集进行训练。尽管没有引入新的数据集,但通过过滤部分低质量数据,我们加快了模型的收敛速度,并提高了模型的整体表现。
地址:https://arxiv.org/pdf/2406.16554
代码:https://github.com/pjlab-sys4nlp/llama-moe