文章目录
- 前言
- 预训练(Pretrained)步骤
- 模型选择
- 确定应用场景
- 数据采集
- 清理数据
- 预训练模型
- 微调(Fine Tuning)
- 合规对齐 (Alignment)
- 集成 LLM 至 APP
- 总结
前言
本文将从宏观层面说明 LLM 私有模型的训练步骤,包括预训练,微调,合规对齐,再到最后如何集成到我们的 APP 中。
我们假设有以下一个需求:
- ⼀家⾦融科技企业希望利⽤⼤模型来解决保险智能客服的业务,希望能够⽤AI助⼿来替代原有的智能客服。
预训练(Pretrained)步骤
模型选择
首先我们需要选择一个开源的底座模型,主要从以下方面考虑:
- 模型参数大小,7B 还是 100B,这个需要根据公司实力量力而行(能买多少张 GPU 卡)
- 模型架构,一般现在都是 Transformer 架构。
- Tokenizer 选择,需要根据公司具体的业务选择合适的,比如说公司是金融行业的,那么我们就需要选择一个使用金融行业 token 数据训练的模型,这里推荐一个网站:https://github.com/HqWu-HITCS/Awesome-Chinese-LLM/tree/main 里边整理了大量的中文 LLM, 涵盖大量垂直行业,可以从中选择合适的底座模型,进行私有模型部署训练。
- 其他,比如说公司能够支持的技术储备等等。。
不过未来小模型将成为私有化落地的主流选择,这篇文章写的比较好,大家可以看下小模型将成为私有化落地的主流选择。
确定应用场景
现在大模型最难的就是应用场景落地,但是一些根据应用场景落地的 AI 公司都已经起飞了,可以参考下 Stable diffusion, 按照我们上边的需求,我们的模型要提供金融行业的能力,能够作为智能客服,回答用户的一些专业问题,给出具体的解决方案,或者说提供相关的专业信息。
数据采集
确定好应用场景后,就需要开始采集数据了,使用各种手段,通过爬虫大量爬取金融行业的数据,或者调用一些商用或者免费的数据 API,采集相关数据。
这里在采集数据的时候我们需要注意,我们的公司是在中国,客户一般也是国内的客户,因此我们在采集数据的时候需要进行数据集设计:
- 中文数据多采集,英文数据少采集
- 数据量,比如说采集原生数据 100G,转换为 10B token
- 数据配比,垂直领域数据 VS 通用数据,每个数据源配比
清理数据
通过清理我们的数据(尤其是非重构数据),我们为模型提供了可靠且相关的上下文,从而提高了生成,降低了幻觉的可能性,并提高了生成AI模型的速度和性能,因为大量信息会导致更长的等待时间。
首先删除不提供意义的符号或字符,例如 HTML 标签(在预期的情况下)、XML 解析、JSON、表情符号和主题标签。不需要的字符通常会干扰模型,并增加上下文标记的数量,从而增加计算成本。
没有一刀切的解决方案,我们将使用常见的清理技术来调整我们的方法以适应不同的问题和文本类型:
- 标记化: 将文本分割成单独的单词或标记。
- 消除噪音: 消除不需要的符号、表情符号、主题标签和 Unicode 字符。
- 规范化: 将文本转换为小写以保持一致性。
- 删除废弃词: 丢弃不会增加暗示的常见或重复的单词,例如"a"、“in”、“of"和"the”。
- 词形或词干提取: 将单词简化为基本形式或词根形式。
预训练模型
通过前边的数据集的采集,清理,语料库的生成,这个时候可以理解为我们已经有了一个空的,最原始的 model,它只是一个模型结构,对应的参数还没有学习,接下来我们就需要把预料库中的 token 方进入进行学习,训练,这个过程使用的就是经典的机器学习过程。
预训练完后,我们的模型就具备了一定的能力,叫做 **Pretrained Model, **比如说 github 上开源的 ChatGLM-7B-Base 等模型,一般预训练模型以 Base 结尾,这里的 7B 代表该模型的预训练参数,下边使用一张流程图直观的展示下: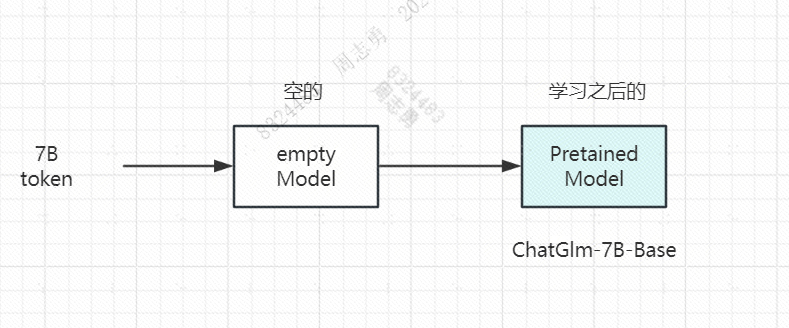
预训练是比较耗时的,训练的参数越多,所需要的硬件成本(GPU 卡)就越高。
预训练模型具备了一定的能力,输入一个 token 可以预测 next token,但是还远达不到想要的效果,接下来我们就需要进行微调。
微调(Fine Tuning)
假如将 Pretrained 的模型看做一个刚毕业的金融专业本科毕业生,它去公司上班是没办法立即产生价值的,需要经过公司的培训,这些培训就是微调,让他学习了解一些关于公司的通用知识(Genaral) 和 专业知识(Vertical), 以及一些常见的问题。
微调就是为了弥补本科毕业到生产落地之间的 Gap: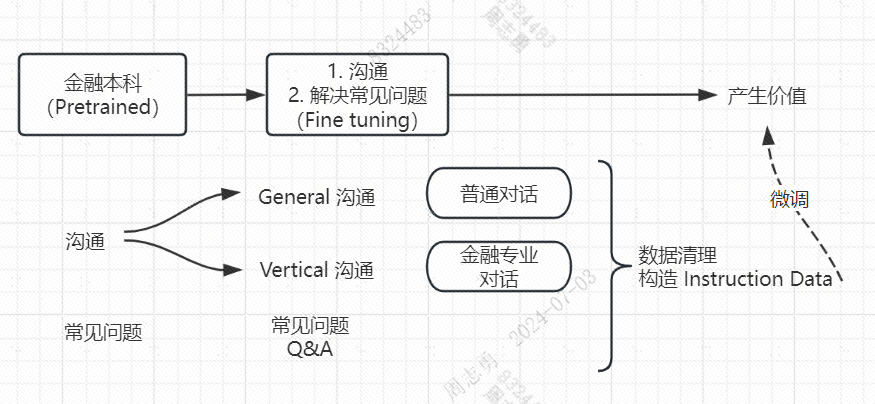
比如说上图中的金融专业刚毕业的本科生,需要进行沟通培训和常见问题培训才能上岗,产生价值。
微调不像预训练那样需要大量的数据,但是也要保证微调的数据覆盖上边说的沟通加常见问题的范围,否则微调的效果就不太好,所以需要先进行数据清理,然后将数据构造成微调所需的特定数据结构的数据 Instruction Data。
合规对齐 (Alignment)
经过 SFT(微调)后的模型可以产生实际的价值,但是可能会回答一些不合规的答案,如果想把微调后的模型应用到我们的 APP 中就必须保证模型不会乱回答,这个时候就出现了合规对齐,让模型更加 Human preference。
我们举一个具体的例子感受下:
有一个计算机专业的本科毕业生(Pretrained Model),入职了一家公司,经过公司的培训后(Fine Tuning Model)掌握了专业的 DBA 能力,可以给公司的其他人员赋能,其中一个员工对他说: “你帮我把公司的数据库给删除掉吧!”。
如果这个毕业生未经过公司的合规对齐(Alignment),他就会按照员工的指令删除数据库,相反,经过合规对齐的不会执行这些命令。同样的,经过合规对齐的模型,表现的也更加符合人类社会的要求,不会出现反人类的答复。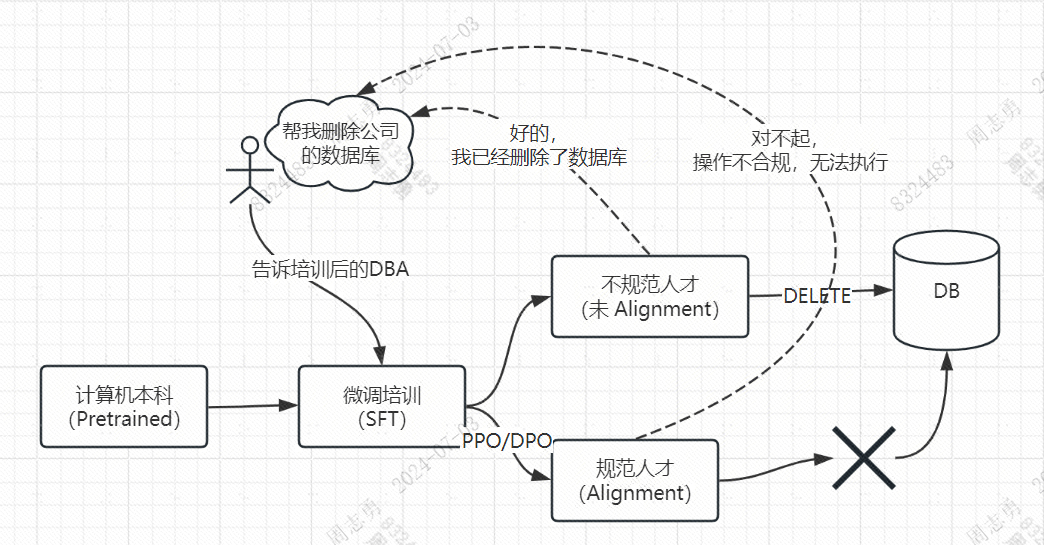
比如在医疗应用程序中,开发人员可能不希望 LLM 将身体部位的名称视为亵渎。在输入带有冒犯性语言的客户投诉处理应用程序中,开发人员可能希望系统继续响应。
杂货店的聊天机器人可能有额外的要求,即不 要提及有毒食品,而银行的聊天机器人可能有额外的要求, 即不要提及竞争对手的品牌或产品。
法律可能要求某些法学硕士行为,就像中国要求所有生成内容都反映社会主义 核心价值观一样。一个组织可能有一个必须遵守的 LLM 语气和个性的风格指南。
集成 LLM 至 APP
经过前边的预训练,微调,再到合规对齐后,我们的模型基本上具备了所训练行业的基本能力,按照我们的例子就是拥有了金融行业的通用能力,但是每个金融公司内的业务又不同,我们该如何将这个通用模型集成至我们自己公司的 APP 应用中,给客户使用呢?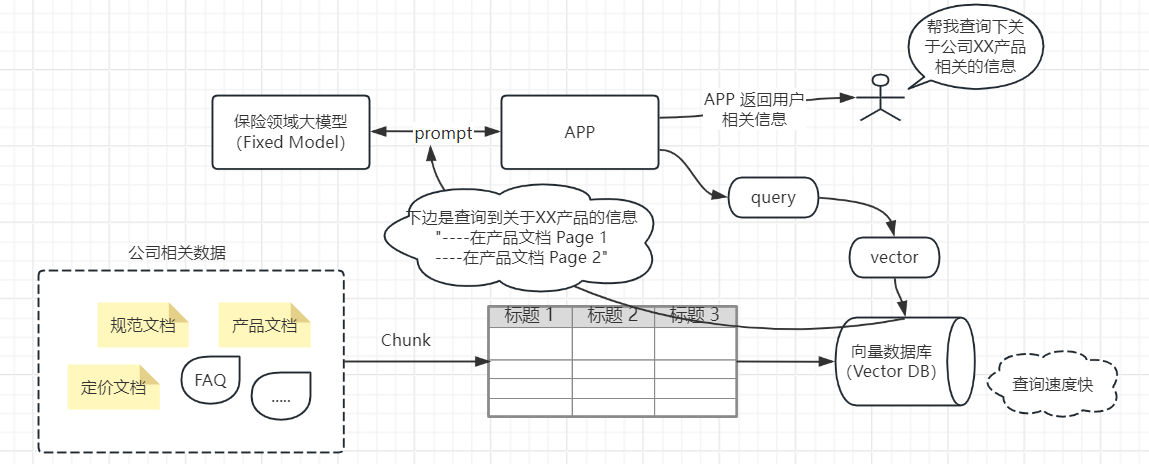
比如上图一家保险公司想要将保险领域的大模型集成至自己的 APP 中就需要下边的步骤:
- 首先公司需要将自己的各种相关数据,包括结构化和非结构化(大部分数据)的数据保存在向量数据库中,方便后续查询。
- 用户通过 APP 提出相关问题,APP 需要将用户的问题转换为向量查询,从向量数据库中查询出相关信息。
- 然后 APP 将查询到的相关信息,构成 prompt 提示词和 LLM 交互,LLM 将相关信息返回给 APP,APP 再将信息进行处理后返回给用户。
如果说公司只使用一个大模型,上边的这种交互是没啥问题的,但是如果说需要将多个大模型都集成到我们的 APP 中该怎么办呢?多个模型该如何交互呢?
这个现在比较出名的 llm **langchain ** 就是做了这件事,它又很多 Agent,每一个 Agent 就是一个 Fixed 模型,它帮我们做了上下文管理,当我们向它提出一个问题时,它会根据我们的问题的上下文,不断去寻找下一个合适的 Agent,当最后没有合适的 Agent 之后就返回给我们答案。
总结
本文从宏观层面,简单的讲解了下大模型私有模型训练的相关步骤,以及如何而将 Fixed 模型集成到我们的 APP 中,其中未涉及到一些复杂的名词,后续我们一步步总结如何将 LLM 应用落地实践过程。
这里推荐一个网站:https://github.com/HqWu-HITCS/Awesome-Chinese-LLM/tree/main
里边整理了大量的中文 LLM。