1. TensorFlow
TensorFlow 是一个开源的机器学习框架,由 Google Brain 团队开发。它用于数据流图的计算,尤其擅长深度学习任务。在 TensorFlow 中,数据流图(Data Flow Graph)是其核心概念之一,它定义了计算的依赖关系和执行顺序。数据流图由一组节点(Nodes)和边(Edges)组成。节点表示计算操作(如加法、乘法),而边表示数据张量在这些操作之间的传递。
数据流图
-
节点(Nodes):
-
操作节点(Operation Nodes):表示具体的计算操作,如矩阵乘法、变量初始化等。每个操作节点接收一个或多个输入,并产生一个或多个输出。
-
数据节点(Data Nodes):通常表示变量(Variables)、常量(Constants)、占位符(Placeholders)等,它们存储和提供数据张量供操作节点使用。
-
-
边(Edges):
-
边表示张量在节点之间的流动。张量是 TensorFlow 中的数据基本单位,类似于多维数组。
-
数据流图的优势
-
高效执行:
-
数据流图可以通过静态优化和调度来提高计算效率。TensorFlow 会分析整个图结构,并自动优化计算顺序和资源使用。
-
-
可移植性:
-
图的定义和执行是分离的。定义好的图可以在不同设备(CPU、GPU、TPU)上执行,甚至可以在不同平台(本地计算、云计算)上迁移。
-
-
并行计算:
-
数据流图自然支持并行计算。独立的计算操作可以同时执行,这对于提高大型模型的训练速度特别重要。
-
以下是tensorflow的应用领域:
① 深度学习
-
图像分类:如使用卷积神经网络(CNN)进行图像识别和分类。
-
对象检测:如使用YOLO或SSD进行对象检测。
-
图像生成:如使用生成对抗网络(GAN)生成逼真的图像。
-
自然语言处理(NLP):如使用循环神经网络(RNN)或Transformer进行文本生成、情感分析和机器翻译。
② 机器学习
-
回归:如线性回归和多项式回归用于预测连续变量。
-
分类:如支持向量机(SVM)和决策树用于分类任务。
-
聚类:如K均值聚类用于数据分组。
-
降维:如主成分分析(PCA)用于特征降维。
③ 强化学习
-
策略梯度方法:如PPO(Proximal Policy Optimization)和A3C(Asynchronous Advantage Actor-Critic)。
-
Q学习方法:如DQN(Deep Q-Network)和Double DQN。
④ 其他应用领域
-
时间序列预测:如使用LSTM(长短期记忆网络)进行股价预测和气象预测。
-
推荐系统:如基于协同过滤和神经网络的推荐系统。
-
语音识别和合成:如使用CTC(Connectionist Temporal Classification)进行语音识别和使用Tacotron进行语音合成。
-
医学图像处理:如使用深度学习进行医学影像的分割和诊断。
-
机器人控制:如使用强化学习进行机器人路径规划和控制。
-
自动驾驶:如结合计算机视觉和强化学习进行自动驾驶系统的开发。
⑤ TensorFlow扩展和工具
-
TensorFlow Extended(TFX):用于生产环境中的机器学习工作流管理。
-
TensorFlow Lite:用于在移动设备和嵌入式设备上运行机器学习模型。
-
TensorFlow.js:在浏览器和Node.js中运行机器学习模型。
-
TensorFlow Hub:用于发布、发现和重用机器学习模型。
2. TensorFlow 与其他数值计算库的区别
TensorFlow 的一个重要特点是它的符号化计算图执行模式,这使得它可以在计算图中描述复杂的数学模型,并且可以通过自动微分来计算梯度,从而用于优化模型。这种机制也使得 TensorFlow 在分布式计算和部署方面具有优势。
相比之下,NumPy 是一个基于数组的数学库,它主要用于数组操作和数学计算,但它不支持符号化计算图和自动微分。因此,NumPy 在某些方面的功能上无法与 TensorFlow 相提并论,特别是在深度学习和神经网络领域的模型训练和优化方面。
TensorFlow 比 NumPy 更快的原因主要有以下几点:
-
并行计算: TensorFlow 可以利用计算图的结构进行优化,将计算操作分配到不同的设备上进行并行计算,包括 CPU、GPU 或 TPU。这种并行计算可以显著加速计算过程,特别是在大规模数据和复杂模型的情况下。
-
硬件加速: TensorFlow 支持 GPU 和 TPU 加速,这些硬件加速器可以执行大规模的矩阵乘法和其他计算密集型操作,比 CPU 更高效。
-
优化的底层实现: TensorFlow 在底层使用了高度优化的 C++ 实现,以及针对不同硬件的特定优化。相比之下,NumPy 主要是基于 Python 的实现,因此在处理大规模数据时可能效率较低。
-
延迟执行和图优化: 在 TensorFlow 1.x 中,计算图的延迟执行机制允许 TensorFlow 进行图级别的优化和变换,以提高执行效率。而在 TensorFlow 2.x 中,默认启用了即时执行模式,但仍然可以通过构建静态计算图来实现优化。
3. TensorFlow 基本使用
① 安装 TensorFlow
在开始使用 TensorFlow 之前,需要先安装它。可以通过以下命令安装:
pip install tensorflow
② 创建张量
TensorFlow 中的核心数据结构是张量(Tensor)。张量是多维数组,可以通过以下方式创建:
import tensorflow as tf
# 创建一个常量张量
a = tf.constant(2.0)
b = tf.constant(3.0)
# 创建一个变量张量
v = tf.Variable([[1.0, 2.0], [3.0, 4.0]])
print(a)
print(b)
print(v)
③ 基本操作
可以对张量进行各种操作,如加减乘除:
c = a + b
d = a * b
print(c)
print(d)
④ 自动微分
TensorFlow 的一个强大功能是自动微分,可以方便地计算导数。
# 定义一个简单的函数
def f(x):
return x**2 + 2*x + 1
# 创建一个变量
x = tf.Variable(3.0)
# 使用GradientTape记录操作
with tf.GradientTape() as tape:
y = f(x)
# 计算导数
dy_dx = tape.gradient(y, x)
print(dy_dx) # 输出应该是8.0
⑤ 构建和训练神经网络
下面是一个简单的神经网络,用于处理MNIST手写数字识别任务:
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
# 加载数据
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 构建模型
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
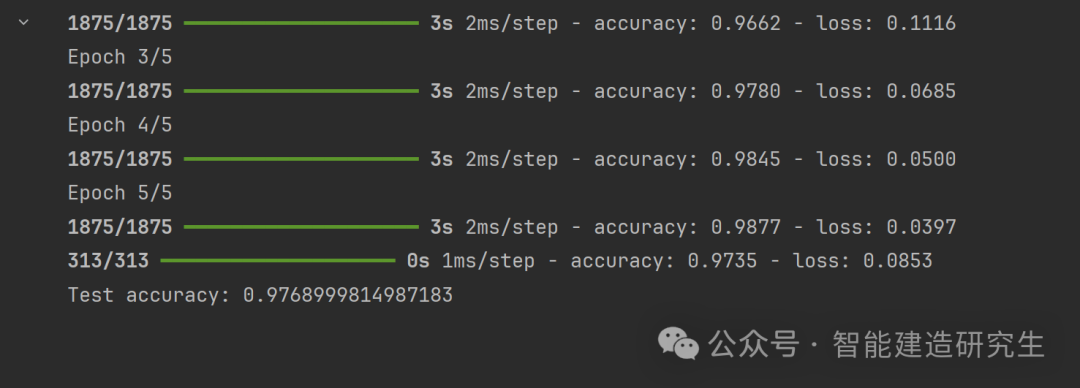
model.fit(x_train, y_train, epochs=5)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f'Test accuracy: {test_acc}')
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!