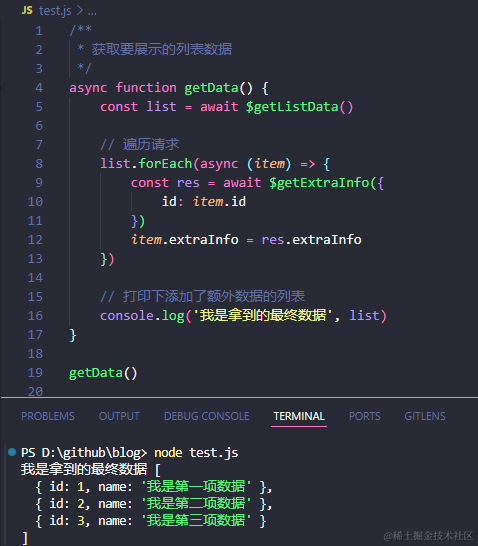
1.学习内容
本节次学习内容来自于吴恩达老师的Preprocessing Unstructured Data for LLM Applications课程,因涉及到非结构化数据的相关处理,遂做学习整理。
2.相关环境准备
2.1 建议python版本在3.9版本以上
chromadb==0.4.22
langchain==0.1.5
langchain-community==0.0.17
langchain-core==0.1.19
langchain-openai==0.0.5
openai==1.11.1
tiktoken==0.5.2
#"unstructured[md,pdf,pptx]"
unstructured-client==0.16.0
unstructured==0.12.3
unstructured-inference==0.7.23
unstructured.pytesseract==0.3.12
urllib3==1.26.18
python-dotenv==1.0.1
panel==1.3.8
ipython==8.18.1
python-pptx==0.6.23
pdf2image==1.17.0
pdfminer==20191125
opencv-python==4.9.0.80
pikepdf==8.13.0
pypdf==4.0.1
2.2 申请unstructured的key
地址:unstructured.io,新注册的用户有14天的免费使用时间,每天1000页的转换。如图:

3.准备相关素材

# Warning control
import warnings
warnings.filterwarnings('ignore')
from IPython.display import JSON
import json
from unstructured_client import UnstructuredClient
from unstructured_client.models import shared
from unstructured_client.models.errors import SDKError
from unstructured.partition.html import partition_html
from unstructured.partition.pptx import partition_pptx
from unstructured.staging.base import dict_to_elements, elements_to_json
# 初始化API
s = UnstructuredClient(
api_key_auth="XXX",
server_url="https://api.unstrXXX",
)
3.1 解析html
from IPython.display import Image
Image(filename="example_screnshoot/HTML_demo.png", height=100, width=100)
现实如图:

filename = "examples/medium_blog.html"
elements = partition_html(filename=filename)
element_dict = [el.to_dict() for el in elements]
example_output = json.dumps(element_dict[11:15], indent=2)
JSON(example_output)
[
{
"type": "Title",
"element_id": "ca4a2c78bca728f3477958ece3222e10",
"text": "Share",
"metadata": {
"category_depth": 0,
"last_modified": "2024-07-09T15:00:56",
"languages": [
"eng"
],
"file_directory": "examples",
"filename": "medium_blog.html",
"filetype": "text/html"
}
},
{
"type": "NarrativeText",
"element_id": "23a7f3e28178ea0fa2b3e98b0275d2e3",
"text": "In the vast digital universe, data is the lifeblood that drives decision-making and innovation. But not all data is created equal. Unstructured data in images and documents often hold a wealth of information that can be challenging to extract and analyze.",
"metadata": {
"last_modified": "2024-07-09T15:00:56",
"languages": [
"eng"
],
"parent_id": "ca4a2c78bca728f3477958ece3222e10",
"file_directory": "examples",
"filename": "medium_blog.html",
"filetype": "text/html"
}
},
{
"type": "NarrativeText",
"element_id": "e1b7532458a93cfc789751895884e7bb",
"text": "Enter Unstructured.io, a powerful tool to extract and efficiently transform structured data. With sixteen and counting pre-built connectors, the API can easily integrate with various data sources, including AWS S3, GitHub, Google Cloud Storage, and more.",
"metadata": {
"link_texts": [
"Unstructured.io"
],
"link_urls": [
"https://www.unstructured.io/"
],
"link_start_indexes": [
6
],
"last_modified": "2024-07-09T15:00:56",
"languages": [
"eng"
],
"parent_id": "ca4a2c78bca728f3477958ece3222e10",
"file_directory": "examples",
"filename": "medium_blog.html",
"filetype": "text/html"
}
},
{
"type": "NarrativeText",
"element_id": "a6179d69ca1a55e0a3f98c08af0034e0",
"text": "In this guide, we’ll cover the advantages of using the Unstructured API and Connector module, walk you through a step-by-step process of using it with the S3 Connector as an example, and show you how to be a part of the Unstructured community.",
"metadata": {
"last_modified": "2024-07-09T15:00:56",
"languages": [
"eng"
],
"parent_id": "ca4a2c78bca728f3477958ece3222e10",
"file_directory": "examples",
"filename": "medium_blog.html",
"filetype": "text/html"
}
}
]
3.2 解析pptx
Image(filename="example_screnshoot/pptx_slide.png", height=600, width=600)

filename = "examples/msft_openai.pptx"
elements = partition_pptx(filename=filename)
element_dict = [el.to_dict() for el in elements]
JSON(json.dumps(element_dict[:], indent=2))
输出如下:
[
{
"type": "Title",
"element_id": "e53cb06805f45fa23fb6d77966c5ec63",
"text": "ChatGPT",
"metadata": {
"category_depth": 1,
"file_directory": "examples",
"filename": "msft_openai.pptx",
"last_modified": "2024-07-09T15:01:08",
"page_number": 1,
"languages": [
"eng"
],
"filetype": "application/vnd.openxmlformats-officedocument.presentationml.presentation"
}
},
{
"type": "ListItem",
"element_id": "34a50527166e6765aa3e40778b5764e1",
"text": "Chat-GPT: AI Chatbot, developed by OpenAI, trained to perform conversational tasks and creative tasks",
"metadata": {
"category_depth": 0,
"file_directory": "examples",
"filename": "msft_openai.pptx",
"last_modified": "2024-07-09T15:01:08",
"page_number": 1,
"languages": [
"eng"
],
"parent_id": "e53cb06805f45fa23fb6d77966c5ec63",
"filetype": "application/vnd.openxmlformats-officedocument.presentationml.presentation"
}
},
{
"type": "ListItem",
"element_id": "631df69dff044f977d66d71c5cbdab83",
"text": "Backed by GPT-3.5 model (gpt-35-turbo), GPT-4 models",
"metadata": {
"category_depth": 0,
"file_directory": "examples",
"filename": "msft_openai.pptx",
"last_modified": "2024-07-09T15:01:08",
"page_number": 1,
"languages": [
"eng"
],
"parent_id": "e53cb06805f45fa23fb6d77966c5ec63",
"filetype": "application/vnd.openxmlformats-officedocument.presentationml.presentation"
}
},
{
"type": "ListItem",
"element_id": "6ac7cc52b0b2842ce7803bb176add0fb",
"text": "Trained over 175 billion machine learning parameters",
"metadata": {
"category_depth": 0,
"file_directory": "examples",
"filename": "msft_openai.pptx",
"last_modified": "2024-07-09T15:01:08",
"page_number": 1,
"languages": [
"eng"
],
"parent_id": "e53cb06805f45fa23fb6d77966c5ec63",
"filetype": "application/vnd.openxmlformats-officedocument.presentationml.presentation"
}
},
{
"type": "ListItem",
"element_id": "01133c5465c85564ab1e39568d8b51f5",
"text": "Conversation-in and message-out ",
"metadata": {
"category_depth": 0,
"file_directory": "examples",
"filename": "msft_openai.pptx",
"last_modified": "2024-07-09T15:01:08",
"page_number": 1,
"languages": [
"eng"
],
"parent_id": "e53cb06805f45fa23fb6d77966c5ec63",
"filetype": "application/vnd.openxmlformats-officedocument.presentationml.presentation"
}
},
{
"type": "ListItem",
"element_id": "1d495819227b92f341fb4b58d723a497",
"text": "Note: Chat Completion API for GPT-4 models",
"metadata": {
"category_depth": 0,
"file_directory": "examples",
"filename": "msft_openai.pptx",
"last_modified": "2024-07-09T15:01:08",
"page_number": 1,
"languages": [
"eng"
],
"parent_id": "e53cb06805f45fa23fb6d77966c5ec63",
"filetype": "application/vnd.openxmlformats-officedocument.presentationml.presentation"
}
},
{
"type": "ListItem",
"element_id": "e450241caa0f39c30939a474bcff06ac",
"text": "GPT-4 is multimodal (e.g., images + text)",
"metadata": {
"category_depth": 0,
"file_directory": "examples",
"filename": "msft_openai.pptx",
"last_modified": "2024-07-09T15:01:08",
"page_number": 1,
"languages": [
"eng"
],
"parent_id": "e53cb06805f45fa23fb6d77966c5ec63",
"filetype": "application/vnd.openxmlformats-officedocument.presentationml.presentation"
}
}
]
3.3 解析pdf
Image(filename="example_screnshoot/cot_paper.png", height=600, width=600)

filename = "examples/CoT.pdf"
with open(filename, "rb") as f:
files=shared.Files(
content=f.read(),
file_name=filename,
)
req = shared.PartitionParameters(
files=files,
strategy='hi_res',
pdf_infer_table_structure=True,
languages=["eng"],
)
try:
resp = s.general.partition(req)
print(json.dumps(resp.elements[:3], indent=2))
except SDKError as e:
print(e)
JSON(json.dumps(resp.elements, indent=2))
输出如下:
[
{
"type": "Title",
"element_id": "826446fa7830f0352c88808f40b0cc9b",
"text": "B All Experimental Results",
"metadata": {
"filetype": "application/pdf",
"languages": [
"eng"
],
"page_number": 1,
"filename": "CoT.pdf"
}
},
{
"type": "NarrativeText",
"element_id": "055f2fa97fbdee35766495a3452ebd9d",
"text": "This section contains tables for experimental results for varying models and model sizes, on all benchmarks, for standard prompting vs. chain-of-thought prompting.",
"metadata": {
"filetype": "application/pdf",
"languages": [
"eng"
],
"page_number": 1,
"parent_id": "826446fa7830f0352c88808f40b0cc9b",
"filename": "CoT.pdf"
}
},
{
"type": "NarrativeText",
"element_id": "9bf5af5255b80aace01b2da84ea86531",
"text": "For the arithmetic reasoning benchmarks, some chains of thought (along with the equations produced) were correct, except the model performed an arithmetic operation incorrectly. A similar observation was made in Cobbe et al. (2021). Hence, we can further add a Python program as an external calculator (using the Python eval function) to all the equations in the generated chain of thought. When there are multiple equations in a chain of thought, we propagate the external calculator results from one equation to the following equations via string matching. As shown in Table 1, we see that adding a calculator significantly boosts performance of chain-of-thought prompting on most tasks.",
"metadata": {
"filetype": "application/pdf",
"languages": [
"eng"
],
"page_number": 1,
"parent_id": "826446fa7830f0352c88808f40b0cc9b",
"filename": "CoT.pdf"
}
},
{
"type": "NarrativeText",
"element_id": "46381dc72867b437cb990fc7734840ee",
"text": "Table 1: Chain of thought prompting outperforms standard prompting for various large language models on five arithmetic reasoning benchmarks. All metrics are accuracy (%). Ext. calc.: post-hoc external calculator for arithmetic computations only. Prior best numbers are from the following. a: Cobbe et al. (2021). b & e: Pi et al. (2022), c: Lan et al. (2021), d: Pi˛ekos et al. (2021).",
"metadata": {
"filetype": "application/pdf",
"languages": [
"eng"
],
"page_number": 1,
"parent_id": "826446fa7830f0352c88808f40b0cc9b",
"filename": "CoT.pdf"
}
},
{
"type": "Table",
"element_id": "3d22e4ba38f71ed038e9a72e4e8e225d",
"text": "Prior best Prompting N/A (finetuning) 55a GSM8K SVAMP ASDiv 57.4b 75.3c AQuA 37.9d MAWPS 88.4e UL2 20B Standard Chain of thought 4.4 (+0.3) + ext. calc 4.1 6.9 10.1 12.5 (+2.4) 16.9 (+0.9) 23.6 (+3.1) 28.3 16.0 20.5 34.3 23.6 16.6 19.1 (+2.5) 42.7 LaMDA 137B Standard Chain of thought 14.3 (+7.8) + ext. calc 6.5 17.8 29.5 37.5 (+8.0) 46.6 (+6.5) 20.6 (-4.9) 42.1 40.1 25.5 53.4 20.6 43.2 57.9 (+14.7) 69.3 GPT-3 175B (text-davinci-002) Chain of thought 46.9 (+31.3) 68.9 (+3.2) 71.3 (+1.0) 35.8 (+11.0) 87.1 (+14.4) Standard 15.6 65.7 70.3 24.8 72.7 + ext. calc 49.6 70.3 71.1 35.8 87.5 Codex (code-davinci-002) Chain of thought 63.1 (+43.4) 76.4 (+6.5) 80.4 (+6.4) 45.3 (+15.8) 92.6 (+13.9) Standard 19.7 69.9 74.0 29.5 78.7 + ext. calc 65.4 77.0 80.0 45.3 93.3 PaLM 540B Standard Chain of thought 56.9 (+39.0) 79.0 (+9.6) 73.9 (+1.8) 35.8 (+10.6) 93.3 (+14.2) + ext. calc 17.9 69.4 72.1 25.2 79.2 79.8 58.6 72.6 35.8 93.5",
"metadata": {
"text_as_html": "<table><thead><tr><th></th><th>Prompting</th><th>GSMBK</th><th>SVAMP</th><th>ASDiv</th><th>AQUA</th><th>MAWPS</th></tr></thead><tbody><tr><td>Prior best</td><td>(finetuning)</td><td>55¢</td><td>57.4°</td><td>75.3¢</td><td>37.9¢</td><td>88.4¢</td></tr><tr><td rowspan=\"3\">UL2 20B</td><td>Standard</td><td>4.1</td><td>10.1</td><td>16.0</td><td>20.5</td><td>16.6</td></tr><tr><td>Chain of thought</td><td>4.4 (+0.3)</td><td>12.5 2.4</td><td>16.9 (+0.9)</td><td>23.6 (+3.1)</td><td>19.1 (2.5</td></tr><tr><td>+ ext. cale</td><td>.9</td><td>283</td><td>343</td><td>23.6</td><td>4.7</td></tr><tr><td rowspan=\"3\">LaMDA 137B</td><td>Standard</td><td>6.5</td><td>29.5</td><td>40.1</td><td>25.5</td><td>432</td></tr><tr><td>Chain of thought</td><td>14.3 (+7.8)</td><td>37.5 +8.0)</td><td>46.6 (+6.5)</td><td>20.6 (-4.9)</td><td>57.9 (+14.7)</td></tr><tr><td>+ ext. cale</td><td>78</td><td>42.</td><td>534</td><td>20.6</td><td>69.3</td></tr><tr><td>GPT-3 175B</td><td>Standard</td><td>15.6</td><td>65.7</td><td>70.3</td><td>24.8</td><td>72.7</td></tr><tr><td rowspan=\"2\">(text-davinci-002)</td><td>Chain of thought</td><td>46.9 (+31.3)</td><td>68.9 +3.2)</td><td>71.3 (+1.0)</td><td>35.8 (+11.0)</td><td>87.1 (+14.4)</td></tr><tr><td>+ ext. cale</td><td>49.6</td><td>0.3</td><td>71.1</td><td>358</td><td>875</td></tr><tr><td>Codex</td><td>Standard</td><td>19.7</td><td>69.9</td><td>74.0</td><td>29.5</td><td>8.7</td></tr><tr><td rowspan=\"2\">(code-davinci-002)</td><td>Chain of thought</td><td>63.1 (+434)</td><td>76.4 (+6.5)</td><td>80.4 (+6.4)</td><td>45.3 (+15.8)</td><td>92.6 (+13.9)</td></tr><tr><td>+ ext. cale</td><td>65.4</td><td>77.0</td><td>80.0</td><td>453</td><td>933</td></tr><tr><td rowspan=\"3\">PalLM 540B</td><td>Standard</td><td>17.9</td><td>69.4</td><td>72.1</td><td>252</td><td>79.2</td></tr><tr><td>Chain of thought</td><td>56.9 +39.0)</td><td>79.0 (+9.6)</td><td>73.9 (+1.8)</td><td>35.8 (+10.6)</td><td>93.3 (+142)</td></tr><tr><td>+ ext. cale</td><td>58.6</td><td>79.8</td><td>726</td><td>358</td><td>935</td></tr></tbody></table>",
"filetype": "application/pdf",
"languages": [
"eng"
],
"page_number": 1,
"parent_id": "826446fa7830f0352c88808f40b0cc9b",
"filename": "CoT.pdf"
}
},
{
"type": "PageNumber",
"element_id": "0301f13983c12f215df253d2e16300d0",
"text": "20",
"metadata": {
"filetype": "application/pdf",
"languages": [
"eng"
],
"page_number": 1,
"filename": "CoT.pdf"
}
}
]
4.总结
上述案例可以实现对非机构化文档的标准化,随后就可以对数据进行愉快的处理了。课程具体学习地址见参考链接1。
参考
- Preprocessing Unstructured Data for LLM Applications
- https://unstructured.io/