1.嵌入(Input Embedding)
让我用一个更具体的例子来解释输入嵌入(Input Embedding)。
背景
假设我们有一个非常小的词汇表,其中包含以下 5 个词:
- "I"
- "love"
- "machine"
- "learning"
- "!"
假设我们想把这句话 "I love machine learning !" 作为输入。
步骤 1:创建词汇表(Vocabulary)
我们给每个词分配一个唯一的索引号:
- "I" -> 0
- "love" -> 1
- "machine" -> 2
- "learning" -> 3
- "!" -> 4
步骤 2:创建嵌入矩阵(Embedding Matrix)
假设我们选择每个词的向量维度为 3(实际应用中维度会更高)。我们初始化一个大小为 5x3 的嵌入矩阵,如下所示:
嵌入矩阵(Embedding Matrix):
[
[0.1, 0.2, 0.3], // "I" 的向量表示
[0.4, 0.5, 0.6], // "love" 的向量表示
[0.7, 0.8, 0.9], // "machine" 的向量表示
[1.0, 1.1, 1.2], // "learning" 的向量表示
[1.3, 1.4, 1.5] // "!" 的向量表示
]步骤 3:查找表操作(Lookup Table Operation)
当我们输入句子 "I love machine learning !" 时,我们首先将每个词转换为其对应的索引:
- "I" -> 0
- "love" -> 1
- "machine" -> 2
- "learning" -> 3
- "!" -> 4
然后,我们使用这些索引在嵌入矩阵中查找相应的向量表示:
输入句子嵌入表示:
[
[0.1, 0.2, 0.3], // "I" 的向量表示
[0.4, 0.5, 0.6], // "love" 的向量表示
[0.7, 0.8, 0.9], // "machine" 的向量表示
[1.0, 1.1, 1.2], // "learning" 的向量表示
[1.3, 1.4, 1.5] // "!" 的向量表示
]
步骤 4:输入嵌入过程
通过查找表操作,我们把原本的句子 "I love machine learning !" 转换成了一个二维数组,每一行是一个词的嵌入向量。
码示例代
让我们用 Python 和 PyTorch 来实现这个过程:
import torch
import torch.nn as nn
# 假设词汇表大小为 5,嵌入维度为 3
vocab_size = 5
embedding_dim = 3
# 创建一个嵌入层
embedding_layer = nn.Embedding(num_embeddings=vocab_size, embedding_dim=embedding_dim)
# 初始化嵌入矩阵(为了便于理解,这里手动设置嵌入矩阵的值)
embedding_layer.weight = nn.Parameter(torch.tensor([
[0.1, 0.2, 0.3], # "I"
[0.4, 0.5, 0.6], # "love"
[0.7, 0.8, 0.9], # "machine"
[1.0, 1.1, 1.2], # "learning"
[1.3, 1.4, 1.5] # "!"
]))
# 输入句子对应的索引
input_indices = torch.tensor([0, 1, 2, 3, 4])
# 获取输入词的嵌入表示
embedded = embedding_layer(input_indices)
print(embedded)输出:
tensor([[0.1000, 0.2000, 0.3000],
[0.4000, 0.5000, 0.6000],
[0.7000, 0.8000, 0.9000],
[1.0000, 1.1000, 1.2000],
[1.3000, 1.4000, 1.5000]], grad_fn=<EmbeddingBackward>)这样我们就完成了输入嵌入的过程,把离散的词转换为了连续的向量表示。
当你完成了词嵌入,将离散的词转换为连续的向量表示后,位置编码步骤如下:
2. 理解位置编码
位置编码(Positional Encoding)通过生成一组特殊的向量,表示词在序列中的位置,并将这些向量添加到词嵌入上,使模型能够识别词序。
2.1 位置编码公式
位置编码使用正弦和余弦函数生成。具体公式如下:

其中:
-
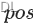 是词在序列中的位置。
是词在序列中的位置。 - i是词嵌入向量的维度索引。
- d是词嵌入向量的总维度。
2.2 生成位置编码向量
以下是 Python 代码示例,展示如何生成位置编码向量,并将其添加到词嵌入上:
生成位置编码向量
import numpy as np
import torch
def get_positional_encoding(max_len, d_model):
"""
生成位置编码向量
:param max_len: 序列的最大长度
:param d_model: 词嵌入向量的维度
:return: 形状为 (max_len, d_model) 的位置编码矩阵
"""
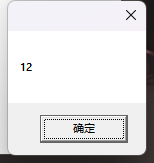
pos = np.arange(max_len)[:, np.newaxis]
i = np.arange(d_model)[np.newaxis, :]
angle_rates = 1 / np.power(10000, (2 * (i // 2)) / np.float32(d_model))
angle_rads = pos * angle_rates
# 采用正弦函数应用于偶数索引 (2i)
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# 采用余弦函数应用于奇数索引 (2i+1)
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
return torch.tensor(angle_rads, dtype=torch.float32)
# 示例参数
max_len = 100 # 假设最大序列长度为 100
d_model = 512 # 假设词嵌入维度为 512
# 生成位置编码矩阵
positional_encoding = get_positional_encoding(max_len, d_model)
print(positional_encoding.shape) # 输出: torch.Size([100, 512])2.3 添加位置编码到词嵌入
假设你已经有一个词嵌入张量 embedded,它的形状为 (batch_size, seq_len, d_model),可以将位置编码添加到词嵌入中:
class TransformerEmbedding(nn.Module):
def __init__(self, vocab_size, d_model, max_len):
super(TransformerEmbedding, self).__init__()
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.positional_encoding = get_positional_encoding(max_len, d_model)
self.dropout = nn.Dropout(p=0.1)
def forward(self, x):
# 获取词嵌入
token_embeddings = self.token_embedding(x)
# 添加位置编码
seq_len = x.size(1)
position_embeddings = self.positional_encoding[:seq_len, :]
# 词嵌入和位置编码相加
embeddings = token_embeddings + position_embeddings.unsqueeze(0)
return self.dropout(embeddings)
# 示例参数
vocab_size = 10000 # 假设词汇表大小为 10000
d_model = 512 # 词嵌入维度
max_len = 100 # 最大序列长度
# 实例化嵌入层
embedding_layer = TransformerEmbedding(vocab_size, d_model, max_len)
# 假设输入序列为一批大小为 2,序列长度为 10 的张量
input_tensor = torch.tensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]], dtype=torch.long)
# 获取嵌入表示
output_embeddings = embedding_layer(input_tensor)
print(output_embeddings.shape) # 输出: torch.Size([2, 10, 512])2.4. 继续进行 Transformer 模型的前向传播
有了词嵌入和位置编码之后,接下来的步骤就是将这些嵌入输入到 Transformer 模型的编码器和解码器中,进行进一步处理。Transformer 模型的编码器和解码器由多层注意力机制和前馈神经网络组成。
位置编码步骤通过生成一组正弦和余弦函数的向量,并将这些向量添加到词嵌入上,使 Transformer 模型能够捕捉序列中的位置信息。
import torch
import torch.nn as nn
class MultiHeadSelfAttention(nn.Module):
def __init__(self, d_model, nhead):
super(MultiHeadSelfAttention, self).__init__()
assert d_model % nhead == 0, "d_model 必须能被 nhead 整除"
self.d_model = d_model
self.d_k = d_model // nhead
self.nhead = nhead
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.fc = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(0.1)
self.scale = torch.sqrt(torch.FloatTensor([self.d_k]))
def forward(self, x):
batch_size = x.size(0)
seq_len = x.size(1)
# 线性变换得到 Q, K, V
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# 分成多头
Q = Q.view(batch_size, seq_len, self.nhead, self.d_k).transpose(1, 2)
K = K.view(batch_size, seq_len, self.nhead, self.d_k).transpose(1, 2)
V = V.view(batch_size, seq_len, self.nhead, self.d_k).transpose(1, 2)
# 计算注意力权重
attn_weights = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
attn_weights = torch.nn.functional.softmax(attn_weights, dim=-1)
attn_weights = self.dropout(attn_weights)
# 加权求和
attn_output = torch.matmul(attn_weights, V)
# 拼接多头输出
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
# 最后的线性变换
output = self.fc(attn_output)
return output
# 示例参数
d_model = 8
nhead = 2
# 输入张量
x = torch.rand(2, 5, d_model)
# 实例化多头自注意力层
multi_head_attn = MultiHeadSelfAttention(d_model, nhead)
# 前向传播
output = multi_head_attn(x)
print("多头自注意力输出:\n", output)解释
- 线性变换:使用 nn.Linear 实现线性变换,将输入张量 通过三个不同的线性层得到查询、键和值向量。
- 分成多头:使用 view 和 transpose 方法将查询、键和值向量分成多头,形状变为 。
- 计算注意力权重:通过点积计算查询和键的相似度,并通过 softmax 归一化得到注意力权重。
- 加权求和:使用注意力权重对值向量进行加权求和,得到每个头的输出。
- 拼接多头输出:将多头的输出拼接起来,并通过一个线性层进行变换,得到最终的输出。
查询、键和值向量的生成是多头自注意力机制的关键步骤,通过线性变换将输入向量转换为查询、键和值向量,然后使用这些向量计算注意力权重,捕捉输入序列中不同位置的相关性。