动手学深度学习53 语言模型
- 语言模型
- 代码
- QA
语言模型
核心:预测文本出现的概率
最常见应用:做预训练模型



当数据序列很长怎么办?常用n-gram 。
一元语法:马尔科夫假设tao=0 基本认为每一个字是独立的,不管前面的东西。
二元语法:马尔科夫假设tao=1 每一个字只与前一个字相关。例如:x3只依赖于x2…………
三元语法:马尔科夫假设tao=2 每一个字只与前两个字相关。例如:x3依赖于x2,x1,…………
最大的好处:可以处理很长的序列。每次看的序列是固定的。
n元语法,数据存储是指数关系 一元语法忽略掉了很多时序信息。n越大,空间复杂度越大。

n元语法:每次看n个子序列。

代码
num_steps: 时间t–tao
扫一遍数据,所有数据只用一次。问题:有数据可能访问不到。
每次把前k个数据扔掉,能遍历所有可能的数据?每次切的不一样。
X:两个长为num_steps=5的序列,Y:每个元素是对应X序列的后一个元素。
数据采样做法:
第一种做法:所有 min-batch采样都是独立的。
第二种做法:两个相邻小批量的数据是相邻的。数据是连续的,可以做更长的序列出来。
import random
import torch
from d2l import torch as d2l
import re
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt', '090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
"""将时间机器数据集加载到文本行的列表中"""
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
tokens = d2l.tokenize(read_time_machine())
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
# print(vocab.token_freqs[:10])
freqs = [freq for token, freq in vocab.token_freqs]
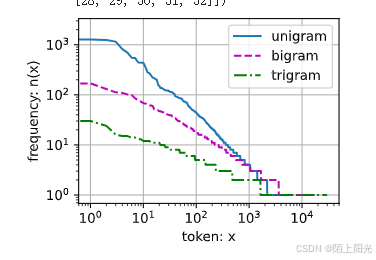
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
# print(bigram_tokens)
# bigram_vocab = d2l.Vocab(bigram_tokens)
# print(bigram_vocab.token_freqs[:10])
trigram_tokens = [triple for triple in zip(corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
print(trigram_vocab.token_freqs[:10])
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
def seq_data_iter_random(corpus, batch_size, num_steps):
"""使用随机抽样生成一个小批量子序列"""
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,
# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
def seq_data_iter_sequential(corpus, batch_size, num_steps):
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
class SeqDataLoader:
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.data_iter_fn = d2l.seq_data_iter_sequential
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
def load_data_time_machine(batch_size, num_steps, use_random_iter=False, max_tokens=10000):
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab
Downloading ../data/timemachine.txt from http://d2l-data.s3-accelerate.amazonaws.com/timemachine.txt...
[('the', 2261), ('i', 1267), ('and', 1245), ('of', 1155), ('a', 816), ('to', 695), ('was', 552), ('in', 541), ('that', 443), ('my', 440)]
--------
排序报错待解决。

不调用d2l的Vocab,按照前面的代码重新写一份。
import random
import torch
from d2l import torch as d2l
import re
import collections
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt', '090b5e7e70c295757f55df93cb0a180b9691891a')
def read_time_machine():
"""将时间机器数据集加载到文本行的列表中"""
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
tokens = d2l.tokenize(read_time_machine())
class Vocab:
"""
文本词表
min_freq: 出现少于多少次 就不管他 扔掉
reserved_tokens: 标记句子开始或者结束的token
"""
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# 按出现频率排序 对token排序
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1], reverse=True)
# 未知词元的索引为0 unk 未知token <> NLP 常见的 token的一个表示方法
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx for idx, token in enumerate(self.idx_to_token)}
# 把词数据全部count一遍,扔掉出现次数比较少的词
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
# 核心:getitem 根据给的token返回index
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens]
# 核心: to_token 给index返回token
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
return [self.idx_to_token[index] for index in indices]
@property
def unk(self): # 未知词元的索引为0
return 0
@property
def token_freqs(self):
return self._token_freqs
def count_corpus(tokens):
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
# print(vocab.token_freqs[:10])
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',
xscale='log', yscale='log')
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
# print(bigram_tokens)
bigram_vocab = Vocab(bigram_tokens)
# print(bigram_vocab.token_freqs[:10])
trigram_tokens = [triple for triple in zip(corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = Vocab(trigram_tokens)
print(trigram_vocab.token_freqs[:10])
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
def seq_data_iter_random(corpus, batch_size, num_steps):
"""使用随机抽样生成一个小批量子序列"""
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,
# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
def seq_data_iter_sequential(corpus, batch_size, num_steps):
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
class SeqDataLoader:
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.data_iter_fn = d2l.seq_data_iter_sequential
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
def load_data_time_machine(batch_size, num_steps, use_random_iter=False, max_tokens=10000):
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab
[(('the', 'time', 'traveller'), 59), (('the', 'time', 'machine'), 30), (('the', 'medical', 'man'), 24), (('it', 'seemed', 'to'), 16), (('it', 'was', 'a'), 15), (('here', 'and', 'there'), 15), (('seemed', 'to', 'me'), 14), (('i', 'did', 'not'), 14), (('i', 'saw', 'the'), 13), (('i', 'began', 'to'), 13)]
X: tensor([[17, 18, 19, 20, 21],
[27, 28, 29, 30, 31]])
Y: tensor([[18, 19, 20, 21, 22],
[28, 29, 30, 31, 32]])
X: tensor([[ 2, 3, 4, 5, 6],
[22, 23, 24, 25, 26]])
Y: tensor([[ 3, 4, 5, 6, 7],
[23, 24, 25, 26, 27]])
X: tensor([[12, 13, 14, 15, 16],
[ 7, 8, 9, 10, 11]])
Y: tensor([[13, 14, 15, 16, 17],
[ 8, 9, 10, 11, 12]])
X: tensor([[ 1, 2, 3, 4, 5],
[17, 18, 19, 20, 21]])
Y: tensor([[ 2, 3, 4, 5, 6],
[18, 19, 20, 21, 22]])
X: tensor([[ 6, 7, 8, 9, 10],
[22, 23, 24, 25, 26]])
Y: tensor([[ 7, 8, 9, 10, 11],
[23, 24, 25, 26, 27]])
X: tensor([[11, 12, 13, 14, 15],
[27, 28, 29, 30, 31]])
Y: tensor([[12, 13, 14, 15, 16],
[28, 29, 30, 31, 32]])
QA

1 数字会做embedding。
2 连续单词是有时序的,有先后顺序,不能打乱。
3 不存count为0的词,空间复杂度还是n–文本长度。
4 过滤掉长尾,不是长尾效应–电商名词。

5 n-gram 中文gram-字,n个字。也可用词。
6 T 序列的长度,每次看多长的序列。
7 把一对词做成一个token。广告中可以把特定产品映射成特定token。
8 T 16 32 不错选择,可以先试试。256 512长度都有。T根据模型复杂度考虑。