作者 | XY
导读
Feed,即个性化推荐信息流,是百度 App 上承载各种类型内容(如文章、视频、图集等)的重要 topic。本文概要讲述了随着业务发展,移动生态数据研发部在 Feed 数据宽表建模上的演进过程以及一些实践:整合流量、内容、用户等数据,建设多版本宽表,实现 feed 数仓的一致性,简化数仓取数逻辑,降低成本提升效率。
全文4586字,预计阅读时间9分钟。
01 引言
在宽表建模阶段之前,feed 数仓是按照传统的数仓分层建模思路进行,按照 ods---->dwd---->dws---->ads 层进行建模,在这四层之外,还有维表 dim 层。数仓建模数据较为分散,不同主题的表分散在不同的数据表,数仓复杂且存在大量冗余:数仓各层近百张表,总体数据量近50P。下游使用数据拼接成本较高,对于内部数仓和外部用户使用,都有巨大的解释成本和使用成本。
随着业务对数据使用精细化分析的需求增多,以及底层工具对数据计算和数据查询速度的提升,数据建设的思路转向建设大宽表,尽可能下沉业务逻辑到表中,隐藏复杂性。
Feed 数仓在宽表建模阶段,共分为三个阶段:
-
小时级核心表+主题宽表建模
-
小时级核心表+主题宽表建模+实时宽表
-
基于流批一体的多版本宽表
我们按照时间顺序来说明建设的这三个阶段。
02 阶段一:小时级宽表+主题宽表建模
在业务快速发展、业务复杂度提高的情况下,原先的基于分层建模的数仓的一些问题——如使用成本高、取数逻辑复杂、查询性能差、时效性差等问题开始逐渐变得显著。为了简化数仓、提升时效性、降低数仓的使用门槛,我们使用场内流式TM框架建设了15 分钟级流批日志表,并基于厂内图灵数仓,整合了 feed 分发、展现、时长、播放等数据到同一张表中,并基于该表,关联用户和资源维度等,建设用户宽表、资源宽表以及用户资源宽表等。
-
15 分钟级流批日志表(log_qi):基于 feed 日志产出 feed 15 分钟的流批日志表,该表主要用于对日志原始字段的解析,并下沉简单业务逻辑。可以对应之前的 ods 层。
-
feed 小时级明细宽表(log_hi):小时级产出,下沉复杂业务逻辑,作为 feed 主要对外服务的数据表,可以对应 dwd 层。
-
主题宽表、中间表:拼接其他主题数据,聚合数据聚合,可以对应 ads 层。

03 阶段二:实时宽表建模
实时宽表(log_5mi)的建设,源于业务的飞速发展,业务侧对数据的时效性提出了更高的要求,用于对实验或者策略上线后效果的验证和问题的监控。现有的 15 分钟级别流批日志已经不太能满足实时监控的时效性需求。而且 15 分钟级流批日志表,只是对原始日志的解析和抽取,并没有下沉复杂的业务逻辑,下游使用该表的成本巨大,无法满足对准实时数据快速迭代的需求。因此建设了 feed 实时数据表,该表 schema 完全对齐小时级宽表,同样下沉了复杂业务逻辑,下游应用可以快速简单地获取实时数据,用于满足业务对于实时数据需求的快速迭代。
实时宽表建设后,feed 数仓相较于之前,多了一条 feed 实时数据流。如下图所示:
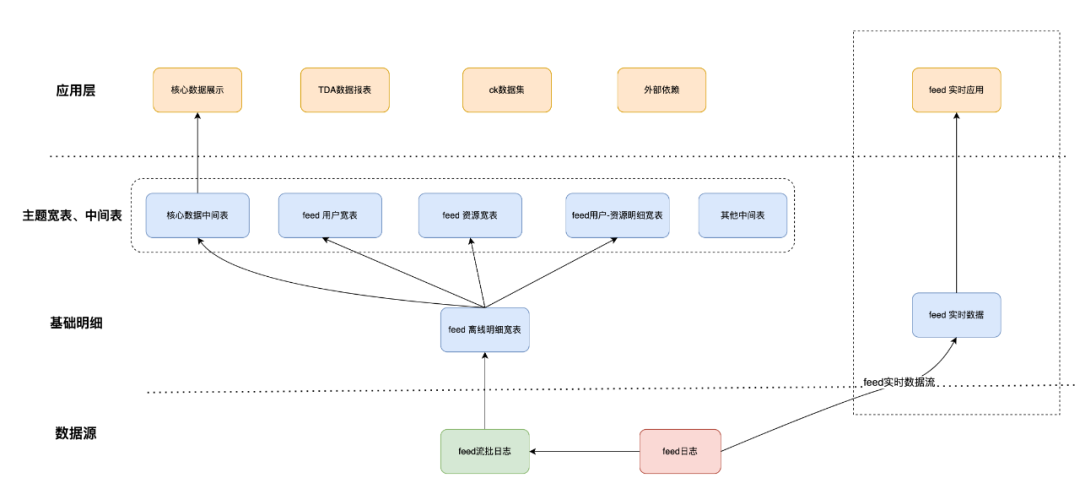
04 阶段三:基于流批一体的多版本宽表
4.1 背景
在小时级表宽、主题宽表、实时宽表建设完成后 ,随着 feed 业务的发展,这套数据建模体现在应用现有业务的时候,还是出现了一些使用上的问题。主要体现在如下方面:
-
口径一致性:主要体现为流式实时数据与离线数据存在的差异,在数据一致性方面遇到了挑战,而且需要维护实时和离线数据两份数据口径。
-
数据源不统一:搜索、直播有部分数据计入到 feed,数据源与现有数据源存在较大差异,获取 feed 数据多了两部分外部数据源。
-
数据重复加工:数据数据源的不一致,导致 feed 数据分散在不同的中间表,导致获取完整数据成本较大,内外部获取数据存在重复加工的问题。
-
数据计算成本大:资源、用户等主题宽表的维度的拼接,在计算中中间数据可能达到 30T,且存在数据倾斜问题。
4.2 建设思路
基于前面小时级表(log_hi)、实时表(log_5mi)的建设思路,建设一张新的天级用户-资源明细数据(log_di)宽表,用这三张表重构 Feed 数仓体系,解决实时&离线数据不一致问题,统一 feed 数据源和数据出口,提升用户资源常用维度产出时效。
建设新表有两个难点:
-
业务上,如何统一不同数据的数据源,有效整合到一张表中,并且在表中下沉复杂的业务逻辑,对外隐藏业务复杂性,只暴露下沉好的业务字段。
-
技术上,在 feed 总体数据拼接用户、资源维度的时候,中间 shuflfe 的数据量会达到 30T,且存在较大的数据倾斜,严重影响 join 的性能。
为了解决以上两个问题,在设计阶段,将新表设计为 4 级分区,拆分为 4 个版本产出,不同版本产出不同的数据。
- 版本拆分思路:feed 汇总数据、资源维度、用户维度、关注关系等,产出时效不同,按照对数据时效性要求的不同以及维度表就绪的时间,不提供版本拼接不同的维度数据,既提升对应维度的产出时效,也减少数据 JOIN 时的数据量。
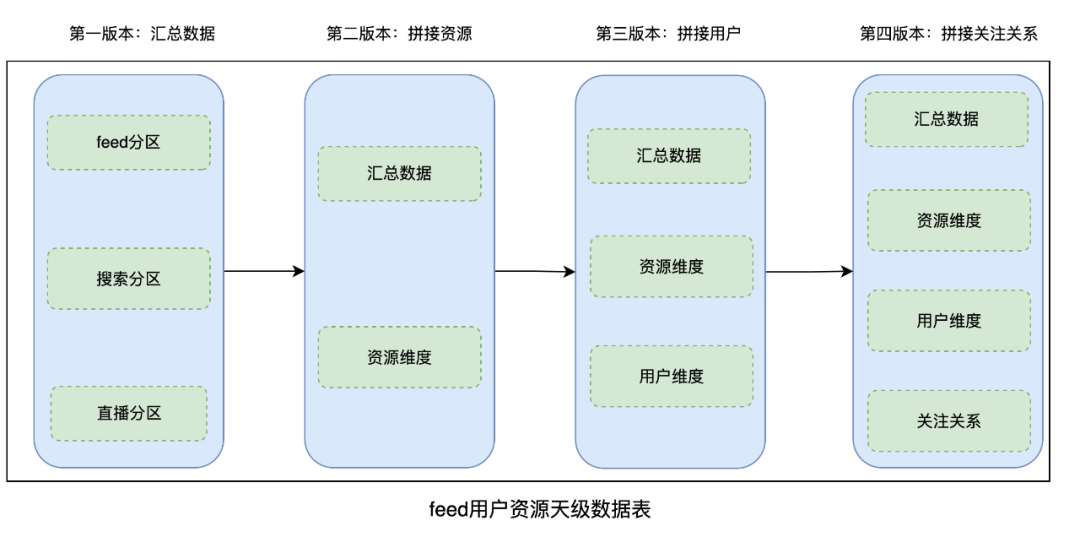
- 分区设计思路:

- 计数优化思路:对拼接的资源表、关注关系表做提前过滤,减少 join 时的数据量,再采用 spark AQE 解决数据倾斜问题。
4.3 Feed 基于流批一体的多版本的数仓体系
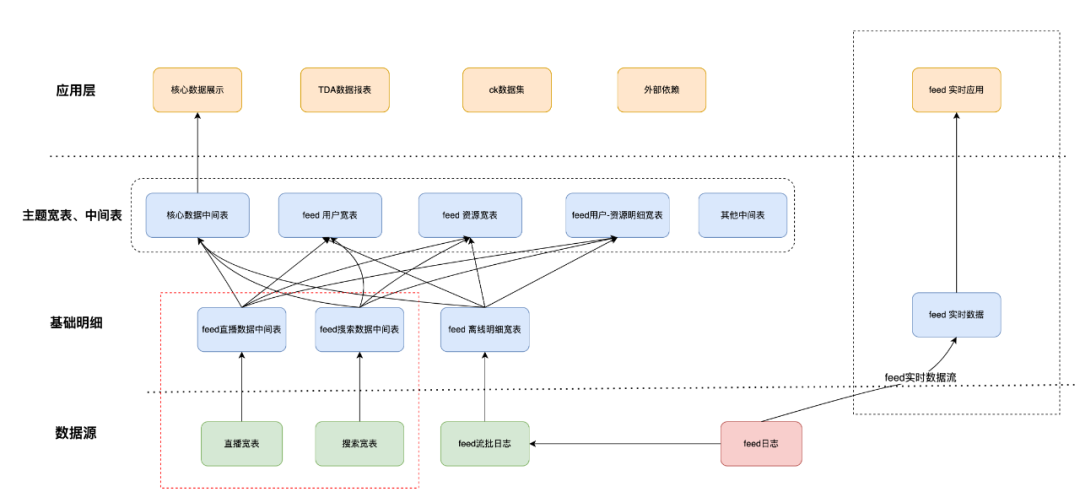
天级用户-资源明细数据(log_di)宽表建设完成后,Feed 实时表(log_5mi)、小时级表(log_hi)、天级表(log_di),由于 schema 对齐,数据一脉相承,可以视为一张大宽表——Feed 基于流批一体的多版本宽表,共 3 张表,涉及 6 个版本:
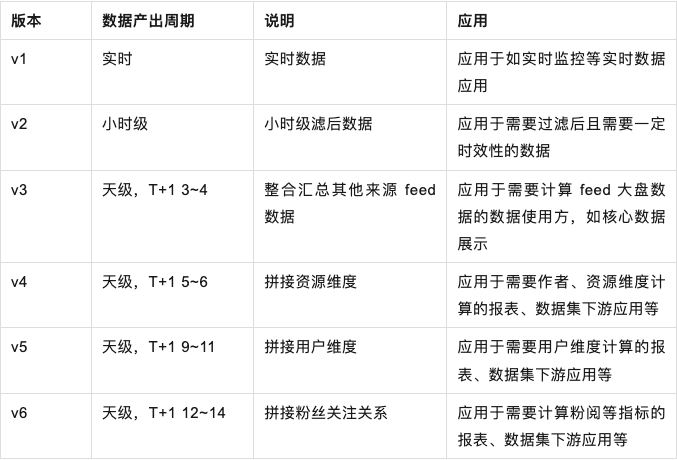
用 Feed 基于流批一体的多版本宽表重构 Feed 数仓体系,其他主题表都基于流批一体的多版本宽表进行上卷,数据出口统一到宽表。不同的时效性产出的数据,对应上层不同的应用,如报表、数据集等等。
重构后数仓示意图如下:
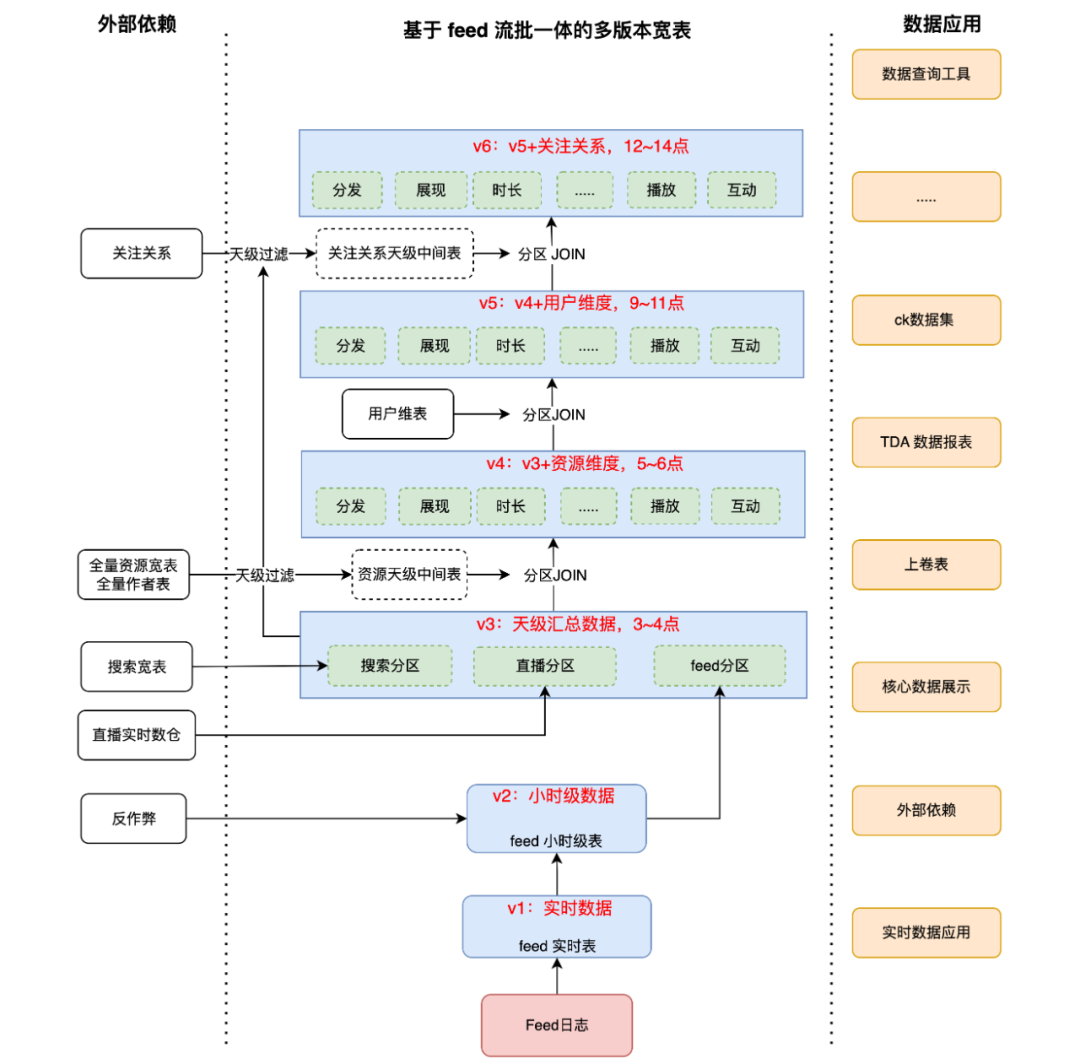
经过重构后的 feed 数仓,具有以下优势:
-
数据源统一与数据出口统一:整合了分散的不同数据源到同一张表,统一了出口,并且下沉了复杂的业务逻辑,下游用户只需要查询一张表,保障了内外部门使用 feed 数据的一致性。
-
多版本产出不同数据:对于时效性不同的查询需求,可以在实时、小时级、天级表多个版本间进行切换,除了调整表名外,查询语句基本不需要修改。
-
高时效性多维度整合:资源、用户等多维数据,不同版本拼接不同的维度,提高了产出时效,下游可以按需依赖。
05 总结与规划
业务的发展对数仓工具提出了更高的要求,工具的不断迭代又带来更多的数仓建设思路,数仓的建设也随着业务的发展不断迭代。在宽表建设阶段,经过不断摸索,最终 feed 数仓简化为基于流批一体的多版本数仓体系。后续随着 Feed 业务规模的不断扩大和复杂化,当前的数仓工具&数仓体系面临的挑战也日益增多,在新的业务挑战下,我们将继续完善数仓体系,以应对不断变化的业务需求,为业务决策和创新提供坚实的数据支持。
——————END——————
推荐阅读
大模型时代数据库技术创新
低代码组件扩展方案在复杂业务场景下的设计与实践
通过搭建 24 点小游戏应用实战,带你了解 AppBuilder 的技术原理
基于 Native 技术加速 Spark 计算引擎
百度&YY设计稿转代码的探索与实践
![LeetCode67(二进制求和[位运算,大数运算])](https://i-blog.csdnimg.cn/direct/7f8be600171e4391b7a1d3a511053d02.png)