目录
一、C++11介绍
二·、为什么要用C++11
三、新特性总结
1、类型推导(auto/decltype)
2、序列for循环语句
3、 lamdba表达式
4、构造函数:委托构造和继承构造
5、容器(array/forward_list)
6、垃圾回收机制
7、正则表达式基础
7.1、符号
7.2、速记理解技巧
7.3、检验数字的表达式
7.4、检验字符的表达式
7.5、特殊需求表达式
8.1、unique_ptr智能指针
8.3、weak_ptr
9、关键字:nullptr/constexpr
9.1、nullptr关键字
9.2、constexpr关键字
10、共享内存
11、std::unordered_set
12、关联容器:unordered_map
13、function函数对象
14、atomic_flag应用
15、条件变量:condition_variable
16、异常处理:exception(头文件stdexcept)
17、std::thread多线程
18、列表初始化
19、final 和 override
19.1、final
19.1.1、final第一种用法
19.1.2、final第二种用法
19.2、override
20、default 和 delete
20.1、显示缺省函数
20.2、删除默认函数(禁止调用)
21、左值引用和右值引用
21.1、什么是左值?什么是左值引用?
21.2、什么是右值?什么是右值引用?
22、完美转发
23、可变参数列表

一、C++11介绍
C++11标准为C++编程语言的第三个官方标准,正式名叫ISO/IEC 14882:2011 - Information technology -- Programming languages -- C++ 。 [1]在正式标准发布前,原名C++0x。它将取代C++标准第二版ISO/IEC 14882:2003 - Programming languages -- C++ 成为C++语言新标准。
C++11包含了核心语言的新机能,并且拓展C++标准程序库,并且加入了大部分的C++ Technical Report 1程序库(数学上的特殊函数除外)。C++ 标准委员会计划在2010年8月之前完成对最终委员会草案的投票,以及于2011年3月3召开的标准会议完成国际标准的最终草案。最终于2011年8月12日公布,并于2011年9月出版。2012年2月28日的国际标准草案(N3376)是最接近于现行标准的草案(编辑上的修正)。此次标准为13年第一次重大修正。
二·、为什么要用C++11
相比C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率。
三、新特性总结
1、类型推导(auto/decltype)
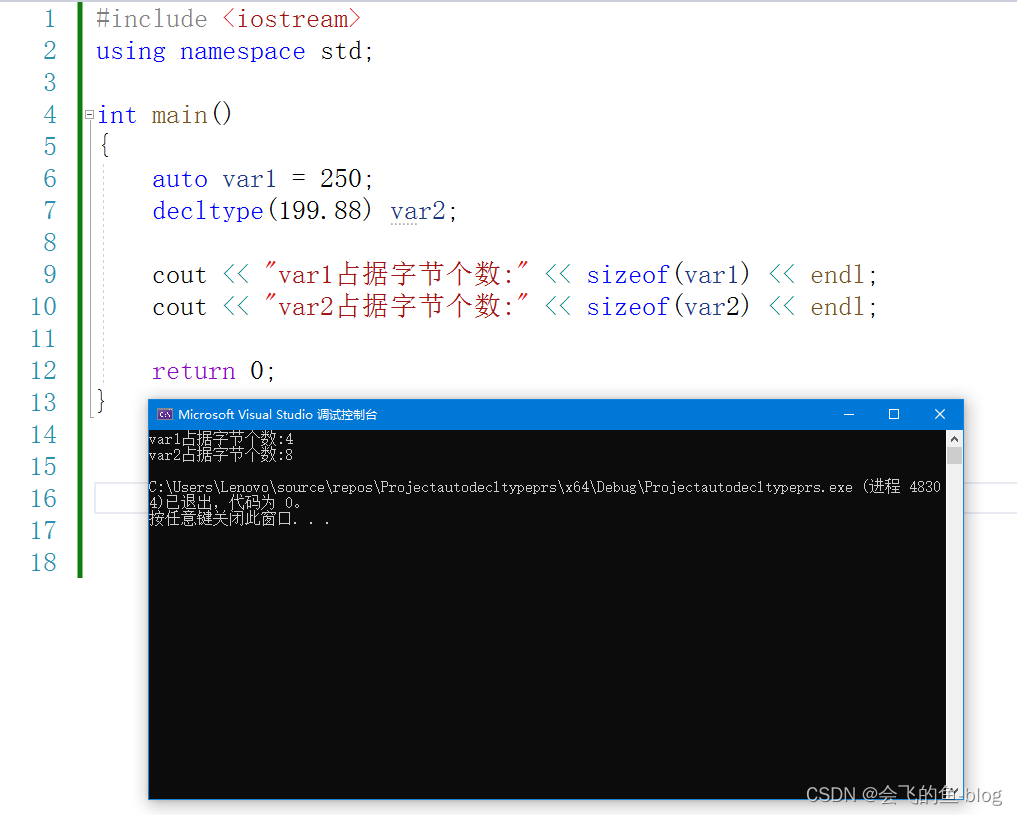
语法:
auto 变量名称 = 值;
decltype(表达式) 变量名称[=值]auto使用的前提是:必须要对auto声明的类型进行初始化,否则编译器无法推导出auto的实际类型。但有时候可能需要根据表达式运行完成之后结果的类型进行推导,因为编译期间,代码不会运行,此时auto也就无能为力。
decltype是根据表达式的实际类型推演出定义变量时所用的类型。
案例:
2、序列for循环语句
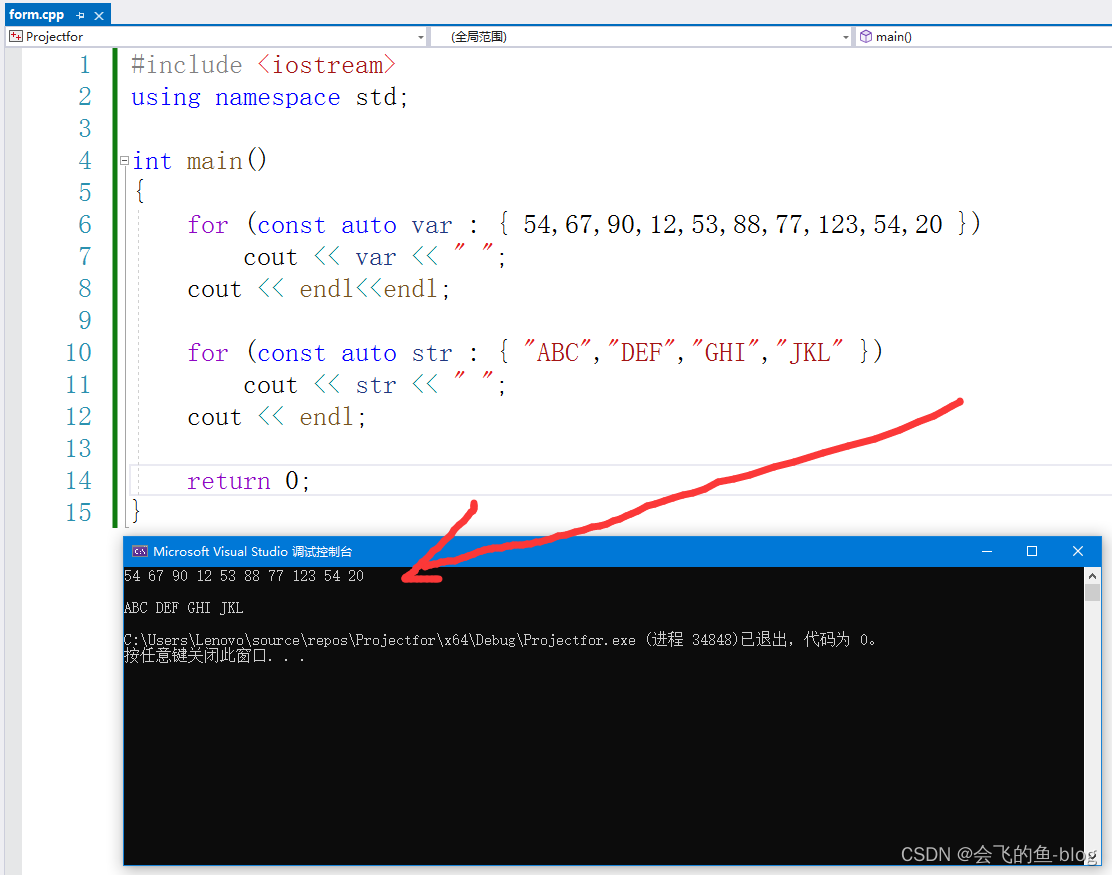
概念:
C++语言当中可以遍历数组、容器、string以及由begin/end函数定义的序列。
案例:
3、 lamdba表达式
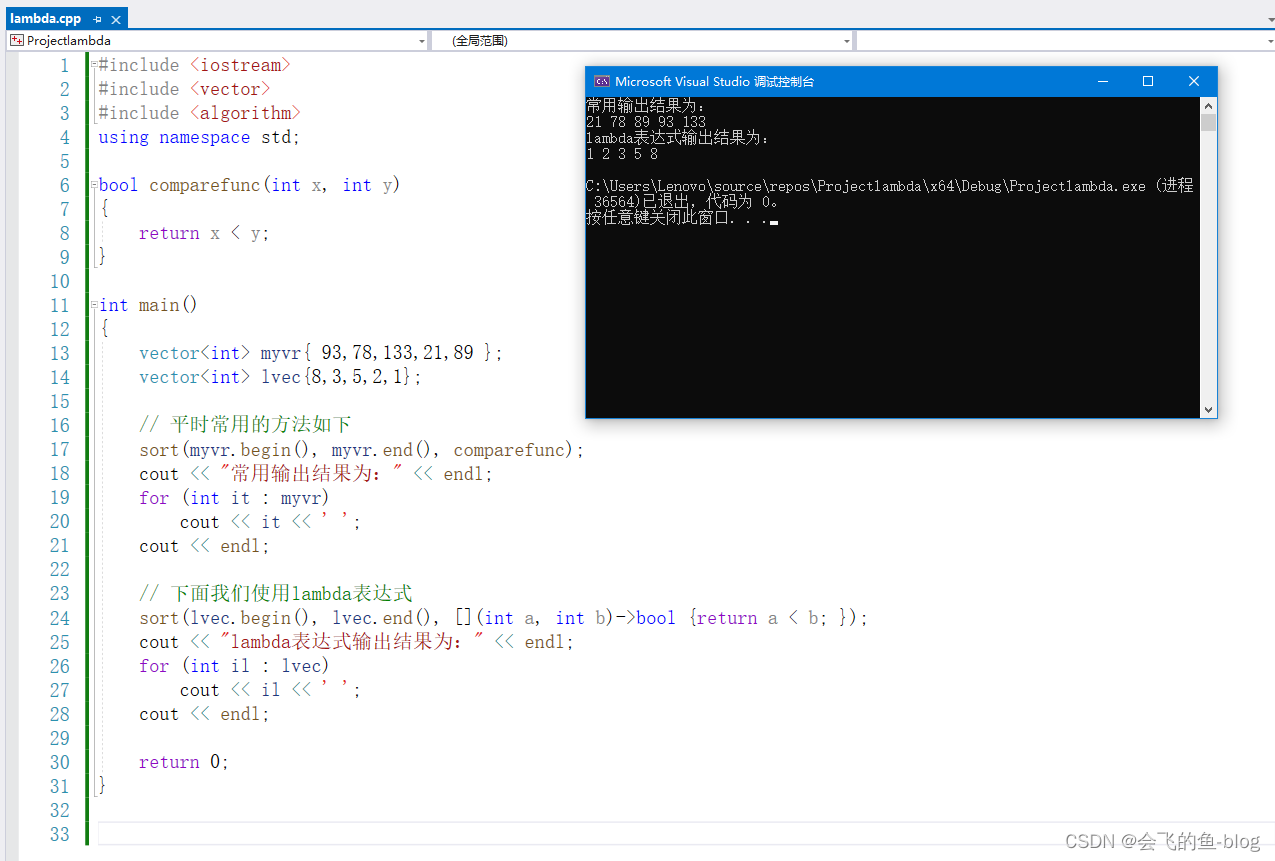
概述:
C++ 11中的lambda表达式用于定义并创建匿名的函数对象。我们如何声明lambda表达式完整格式语法如下:
[capture list](params list) mutable exception->return type {function body}
案例:
4、构造函数:委托构造和继承构造
委托构造函数它可以使用当前的类的其他构造函数来协助当前构造函数的初始化操作。
普通构造函数和委托构造函数区别:
(1)、它们两都是一个成员初始值列表与一函数体;
(2)、委托构造函数的成员初始值列表只有一个唯一的参数,就是构造函数。
当被委托构造函数当中函数体有代码,那么会先执行完函数体的代码,才加回来到扫托构造函数。
工程案例:
#include <string>
using namespace std;
// 创建一个类
class TestC
{
public:
// 普通构造函数
TestC(string s, int d) :_data(d), _str(s)
{
cout << "程序执行:普通构造函数的函数体" << endl;
}
// 委托构造函数
TestC(int d) :TestC("测试TestC(int d)", d)
{
cout << "程序执行:委托构造函数TestC(int d) 的函数体" << endl;
}
void printdata()const
{
cout << "-------------------------------------" << endl;
cout << "_str=" << _str << endl;
cout << "_data=" << _data << endl;
cout << "-------------------------------------" << endl << endl;
}
private:
int _data;
string _str;
};
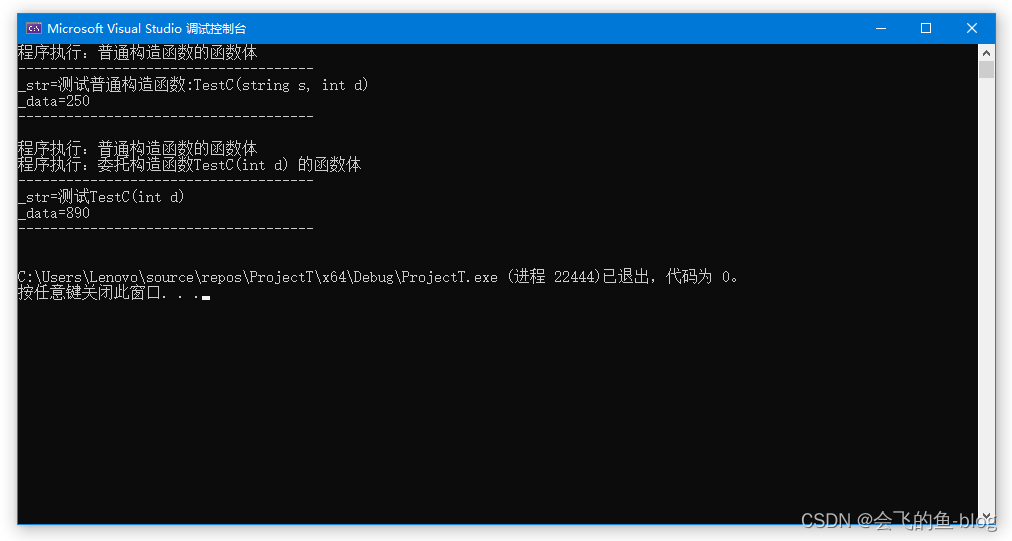
int main()
{
TestC objc1("测试普通构造函数:TestC(string s, int d) ", 250);
objc1.printdata();
TestC objc2(890);
objc2.printdata();
// 委托构造函数字符串_str赋值操作,这个大家自己完成。
return 0;
}
继承构造函数:在c++语言当中的继承关系,只有虚函数可以被继承,而构造函数不可以是虚函数,所以构造函数不能被继承,但是我们可以通过某种手段,达到继承效果。
工程案例分析:
#include <iostream>
using namespace std;
struct A
{
void func(double d)
{
cout << "基类A :" << d << endl << endl;
}
};
struct B : A
{
using A::func; // C++ 11标准当中利用using关键字特点,是构造函数可以被“继承”。
void func(int i)
{
cout << "派生类B:" << i << endl << endl;
}
};
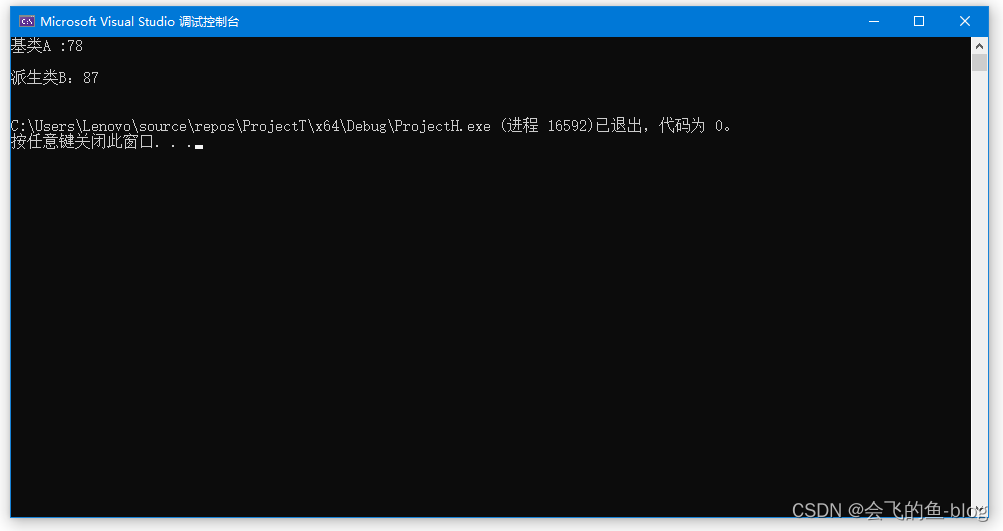
int main()
{
A a;
a.func(78);
B b;
b.func(87);
return 0;
}
5、容器(array/forward_list)
C++ array(STL array)容器,array容器是C++ 11标准中新增的序列容器。
工程案例分析:
#include <iostream>
// 要使用array容器,就必须加上头文件
#include <array>
using namespace std;
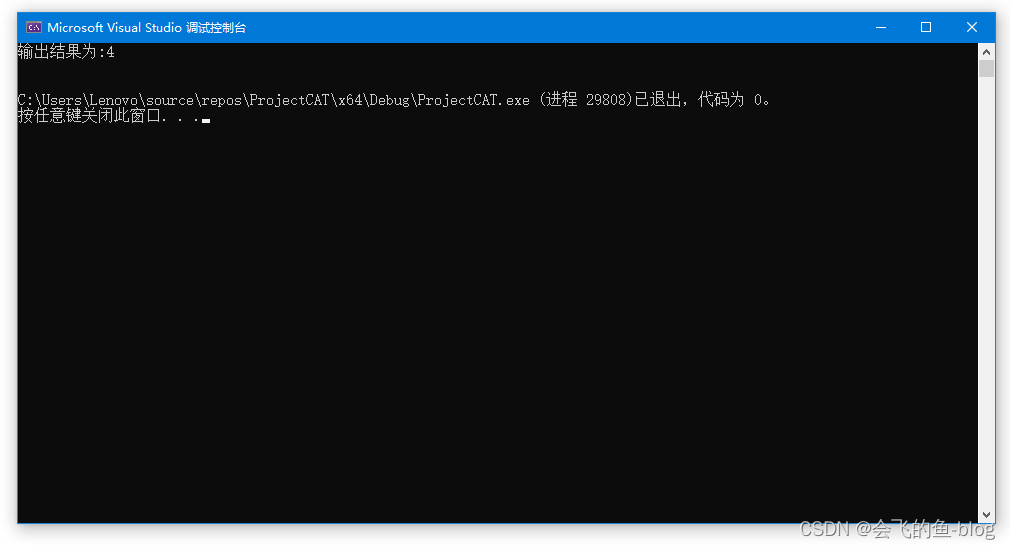
int main()
{
std::array<int, 5> values{};
// 初始化values容器
for (int i = 0; i < values.size(); i++)
{
values.at(i) = i;
}
// 通过get()重载函数输出指定位置元素值
cout << "输出结果为:" << get<4>(values) << endl << endl;
return 0;
}
forward_list是C++ 11新增加的一类容器,其底层实现和list容器类似,采用的也是链表结构,只是forward_list使用的单向链表,而list使用的双向链表。
工程案例分析:
#include <iostream>
#include <forward_list>
using namespace std;
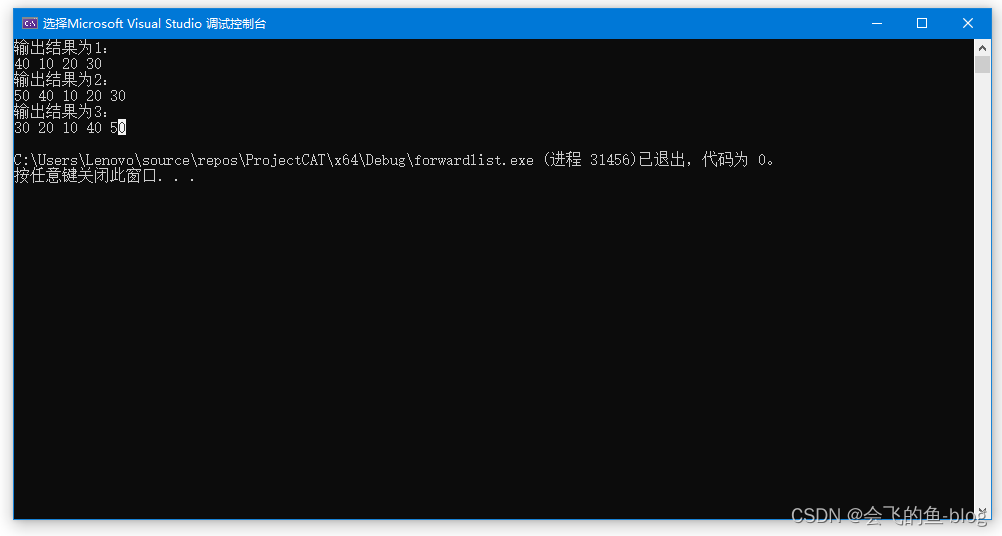
int main()
{
std::forward_list<int> values{ 10,20,30 };
values.emplace_front(40);
cout << "输出结果为1:" << endl;
for (auto it = values.begin(); it != values.end(); it++)
{
cout << *it << " ";
}
cout << endl;
values.emplace_after(values.before_begin(), 50);
cout << "输出结果为2:" << endl;
for (auto it = values.begin(); it != values.end(); it++)
{
cout << *it << " ";
}
cout << endl;
values.reverse();
cout << "输出结果为3:" << endl;
for (auto it = values.begin(); it != values.end(); it++)
{
cout << *it << " ";
}
cout << endl;
}
6、垃圾回收机制
- 标准C++没有垃圾回收机制原因:系统开销、耗内存、替代方法、没有共同基类。
- C/C++中经典垃圾回收算法:引用计数算法、标记-清除算法、节点拷贝算法。
7、正则表达式基础
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
7.1、符号
正则表达式由一些普通字符和一些元字符(metacharacters)组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义,我们下面会给予解释。
在最简单的情况下,一个正则表达式看上去就是一个普通的查找串。例如,正则表达式"testing"中没有包含任何元字符,它可以匹配"testing"和"testing123"等字符串,但是不能匹配"Testing"。
要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。
| 元字符 | 描述 |
| \ | 将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\\n”匹配\n。“\n”匹配换行符。序列“\\”匹配“\”而“\(”则匹配“(”。即相当于多种编程语言中都有的“转义字符”的概念。 |
| ^ | 匹配输入字行首。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入行尾。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 ['o', 'o', 'o', 'o'] |
| .点 | 匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。 |
| (?:pattern) | 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| (?=pattern) | 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 非获取匹配,正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
| (?<=pattern) | 非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 *python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
| (?<!pattern) | 非获取匹配,反向否定预查,与正向否定预查类似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。 *python的正则表达式没有完全按照正则表达式规范实现,所以一些高级特性建议使用其他语言如java、scala等 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[z|f]ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“plin”任一字符。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D | 匹配一个非数字字符。等价于[^0-9]。grep要加上-P,perl正则支持 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \s | 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何可见字符。等价于[^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w | 匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。 |
| \num | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
| \nml | 如果n为八进制数字(0-7),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
| \p{P} | 小写 p 是 property 的意思,表示 Unicode 属性,用于 Unicode 正表达式的前缀。中括号内的“P”表示Unicode 字符集七个字符属性之一:标点字符。 其他六个属性: L:字母; M:标记符号(一般不会单独出现); Z:分隔符(比如空格、换行等); S:符号(比如数学符号、货币符号等); N:数字(比如阿拉伯数字、罗马数字等); C:其他字符。 *注:此语法部分语言不支持,例:javascript。 |
| \< \> | 匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the\>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。 |
| ( ) | 将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
| | | 将两个匹配条件进行逻辑“或”(or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 |
最简单的元字符是点,它能够匹配任何单个字符(注意不包括换行符)。
7.2、速记理解技巧
| . | [ ] | ^ | $ |
四个字符是所有语言都支持的正则表达式,所以这四个是基础的正则表达式。正则难理解因为里面有一个等价的概念,这个概念大大增加了理解难度,让很多初学者看起来会懵,如果把等价都恢复成原始写法,自己书写正则就超级简单了,就像说话一样去写你的正则了:
等价:
等价是等同于的意思,表示同样的功能,用不同符号来书写。
?,*,+,\d,\w 都是等价字符
?等价于匹配长度{0,1}
*等价于匹配长度{0,}
+等价于匹配长度{1,}
\d等价于[0-9]
\D等价于[^0-9]
\w等价于[A-Za-z_0-9]
\W等价于[^A-Za-z_0-9]。
常用运算符与表达式:
^ 开始
() 域段
[] 包含,默认是一个字符长度
[^] 不包含,默认是一个字符长度
{n,m} 匹配长度
. 任何单个字符(\. 字符点)
| 或
\ 转义
$ 结尾
[A-Z] 26个大写字母
[a-z] 26个小写字母
[0-9] 0至9数字
[A-Za-z0-9] 26个大写字母、26个小写字母和0至9数字
, 分割
分割语法:
[A,H,T,W] 包含A或H或T或W字母
[a,h,t,w] 包含a或h或t或w字母
[0,3,6,8] 包含0或3或6或8数字
语法与释义:
基础语法 "^([]{})([]{})([]{})$"
正则字符串 = "开始([包含内容]{长度})([包含内容]{长度})([包含内容]{长度})结束"
?,*,+,\d,\w 这些都是简写的,完全可以用[]和{}代替,在(?:)(?=)(?!)(?<=)(?<!)(?i)(*?)(+?)这种特殊组合情况下除外。
初学者可以忽略?,*,+,\d,\w一些简写标示符,学会了基础使用再按表自己去等价替换
实例:
字符串;tel:086-0666-88810009999
原始正则:"^tel:[0-9]{1,3}-[0][0-9]{2,3}-[0-9]{8,11}$"
速记理解:开始 "tel:普通文本"[0-9数字]{1至3位}"-普通文本"[0数字][0-9数字]{2至3位}"-普通文本"[0-9数字]{8至11位} 结束"
等价简写后正则写法:"^tel:\d{1,3}-[0]\d{2,3}-\d{8,11}$" ,简写语法不是所有语言都支持。
7.3、检验数字的表达式
1. 数字:^[0-9]*$
2. n位的数字:^\d{n}$
3. 至少n位的数字:^\d{n,}$
4. m-n位的数字:^\d{m,n}$
5. 零和非零开头的数字:^(0|[1-9][0-9]*)$
6. 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
7. 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
8. 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
9. 有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
10. 有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
11. 非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
12. 非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
13. 非负整数:^\d+$ 或 ^[1-9]\d*|0$
14. 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
15. 非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
16. 非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
17. 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
18. 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
19. 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
7.4、检验字符的表达式
1. 汉字:^[\u4e00-\u9fa5]{0,}$
2. 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
3. 长度为3-20的所有字符:^.{3,20}$
4. 由26个英文字母组成的字符串:^[A-Za-z]+$
5. 由26个大写英文字母组成的字符串:^[A-Z]+$
6. 由26个小写英文字母组成的字符串:^[a-z]+$
7. 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
8. 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
9. 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
10. 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
11. 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+ 12 禁止输入含有~的字符:[^~\x22]+
7.5、特殊需求表达式
1. Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
2. 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
3. InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
4. 手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
5. 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
6. 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
7. 身份证号(15位、18位数字):^\d{15}|\d{18}$
8. 短身份证号码(数字、字母x结尾):^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$
9. 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
10. 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
11. 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
12. 日期格式:^\d{4}-\d{1,2}-\d{1,2}
13. 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
14. 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
15. 钱的输入格式:
16. 1.有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
17. 2.这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
18. 3.一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
19. 4.这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
20. 5.必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
21. 6.这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
22. 7.这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
23 8.1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
24. 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
25. xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
26. 中文字符的正则表达式:[\u4e00-\u9fa5]
27. 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
28. 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
29. HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
30. 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
31. 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
32. 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
33. IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)
34. IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))
工程案例分析:
#include <iostream>
#include <string>
#include <regex>
int main()
{
std::regex string_reg("[1-9](\\d{5,11})");
std::string strtest("1032");
std::smatch matchresults;
// 正则匹配
if (std::regex_match(strtest, matchresults, string_reg))
{
std::cout << "Match:" << std::endl;
// 输出表达式结果
for (size_t i = 0; i < matchresults.size(); i++)
{
std::cout << matchresults[i] << std::endl;
}
}
else
{
std::cout << "Not Match:" << std::endl;
}
return 0;
}
8、智能指针(shared_ptr/unique_ptr/weak_ptr)
智能指针的头文件-->#include <memory>
8.1、unique_ptr智能指针
独占指针(内存占为己有,不支持拷贝和赋值)
案例分析:
#include <iostream>
#include <memory>
using namespace std;
int main()
{
std::unique_ptr<int> p1(new int(24));
cout << "*p1=" <<* p1 << endl << endl;
std::unique_ptr<int> p2 = std::move(p1);
cout << "*p2=" << *p2 << endl << endl;
p2.reset(); // 显式释放内存
p1.reset();
std::unique_ptr<int>p3(new int(250));
p3.reset(new int(666)); // 绑定动态对象
cout << "*p3=" << *p3 << endl << endl;
p3 = nullptr; // 显式销毁指向对象,同时智能指针变为空,p3.reset()
std::unique_ptr<int> p4(new int(999));
int* p = p4.release(); // 只是释放控制权,不会释放内存
cout << "*p=" << *p << endl << endl;
cout << "*p4=" <<*p4 << endl;
delete p; // 释放区资源数据
return 0;
}

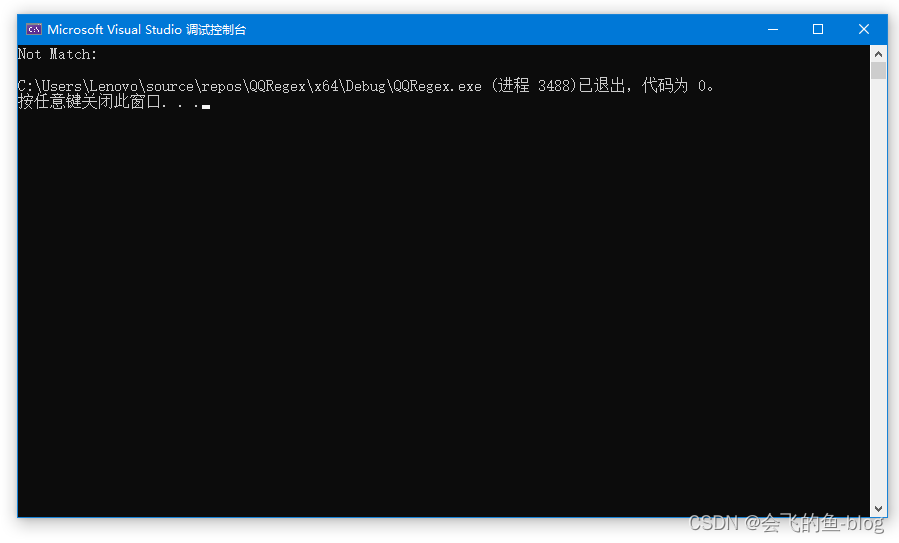
8.2、shared_ptr
shared_ptr智能指针(共享拥有同一堆分配对象的内存,支持复制与赋值操作)。
案例分析:
#include <iostream>
#include <memory>
using namespace std;
int main()
{
shared_ptr<int> p1(new int(456));
shared_ptr<int> p2 = p1;
cout << "p2=" << p2.use_count() << endl << endl;
cout << "*p1=" <<*p1<< endl;
cout << "*p2=" << *p2 << endl;
cout << "p2=" << p2.use_count() << endl << endl;
p1.reset();
cout << "p2=" << p2.use_count() << endl << endl;
return 0;
}
make_shared函数:最安全的分配和使用动态内存的方法。
8.3、weak_ptr
weak_ptr智能指针:配合shared_ptr而引入的一种智能指针协助shared_ptr工作。它的构造和析构不会引起引用计数的增加或减少。weak_ptr并不拥有资源的所有权,所以不能直接使用资源。可以从一个weak_ptr构造一个shared_ptr以取得共享资源的所有权。
案例分析:
#include <iostream>
#include <memory>
using namespace std;
int main()
{
shared_ptr<int> p1(new int(300));
shared_ptr<int> p2 = p1;
weak_ptr<int> wp = p1;
cout << "count=" << wp.use_count() << endl << endl;
cout << "*p1=" << *p1 << endl;
cout << "*p2=" << *p2 << endl;
cout << endl;
return 0;
}

9、关键字:nullptr/constexpr
9.1、nullptr关键字
nullptr关键字,它的出现为代替NULL。
案例分析:
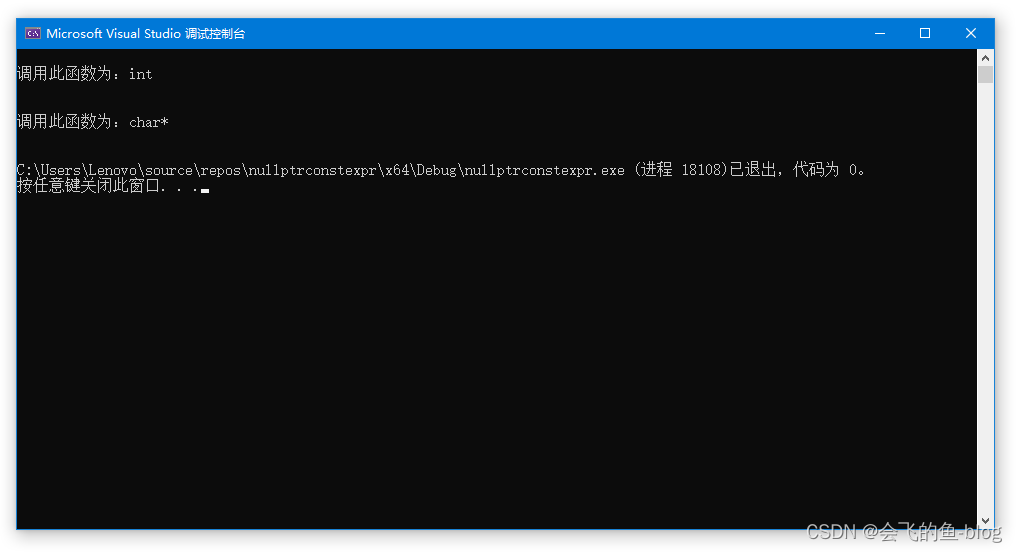
#include <iostream>
using namespace std;
void Func(char *pc)
{
printf("\n调用此函数为:char*\n\n");
}
void Func(int inumber)
{
printf("\n调用此函数为:int\n\n");
}
int main()
{
Func(0);
Func(nullptr);
return 0;
}
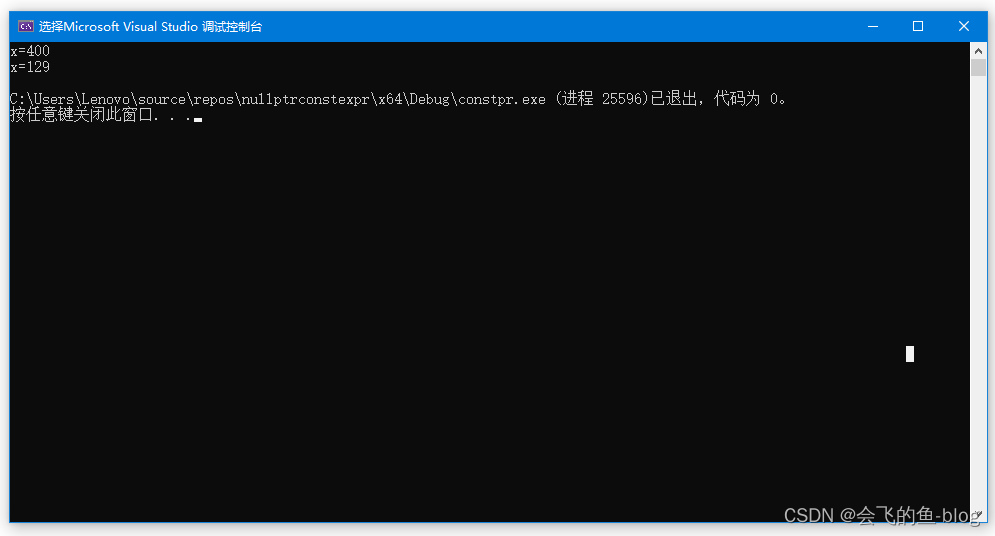
9.2、constexpr关键字
案例分析:
#include <iostream>
using namespace std;
int main()
{
int x = 400;
int y = 2000;
cout << "x=" << x << endl;
constexpr int* p = &x;
*p = 129;
cout << "x=" << x << endl;
// p = &y; 错误
return 0;
}
10、共享内存
服务端程序:1、创建共享内存区域部分 2、内存映射到当前应用程序进程 3、写入数据信息
客户端程序:1、打开共享内存区域部分 2、内存映射到当前应用程序进程 3、读出数据信息
11、std::unordered_set
std::unordered_set的数据存储结构也是采用哈希表的方式结构操作,除此之外,std::unordered_set在插入时不会自动排序。
工程案例分析:
#include <iostream>
#include <string>
#include <set>
#include <unordered_set>
int main()
{
std::unordered_set<int> un_set;
un_set.insert(23);
un_set.insert(33);
un_set.insert(12);
un_set.insert(78);
un_set.insert(99);
std::cout << "\nunordered_set:" << std::endl;
for (auto it : un_set)
{
std::cout << it << std::endl;
}
std::cout << std::endl;
std::set<int> st;
st.insert(23);
st.insert(33);
st.insert(12);
st.insert(78);
st.insert(99);
std::cout << "\nset:" << std::endl;
for (auto it : st)
{
std::cout << it << std::endl;
}
std::cout << std::endl;
return 0;
}
12、关联容器:unordered_map
Unordered_map为一个关联容器,内部采用hash表结构,具备快速检索的功能。特性:关联性、无序性、map、唯一性。
工程案例分析:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
typedef unordered_map<string, string> strmap;
strmap merge(strmap str1, strmap str2)
{
strmap temp(str1);
temp.insert(str2.begin(), str2.end());
return temp;
}
int main()
{
strmap s1;
strmap s2({ {"apple","red"},{"lemon","yellow"} }); // 使用数组初始化
strmap s3({ {"orange","orange"},{"strawberry","red"} }); // 使用数组初始化
strmap s4(s2); // 复制初始化
strmap s5(merge(s3, s4)); // 移动初始化操作
strmap s6(s5.begin(), s5.end()); // 范围初始化操作
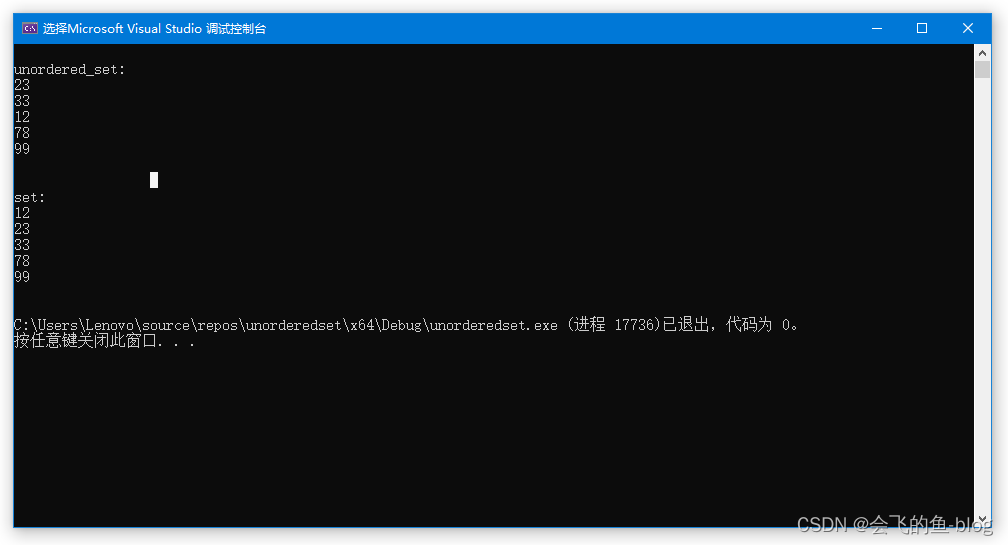
cout << "\n输出s6容器:\n";
for (auto& x : s6)
cout << " " << x.first << ":" << x.second;
cout << endl;
return 0;
}
13、function函数对象
c++函数对象:函数对象指定义operator()的对象,语法形式如下:
Class FunctionObjectType
{
Public:
Void operator()()
{
操作语句
}
};
优势:比普通函数要灵活(可以拥有状态),执行速度比函数指针要快。
我们以函数对象作为排序原则操作,具体如下:
#include <iostream>
#include <set>
using namespace std;
class TestA
{
public:
TestA(string lname, string fname):_fname(fname),_lname(lname)
{
cout << "执行TestA类的构造函数\n";
}
string firstname()const
{
return _fname;
}
string lastname()const
{
return _lname;
}
private:
string _fname = nullptr;
string _lname = nullptr;
};
class TestB
{
public:
bool operator() (const TestA& t1, const TestA& t2)const
{
return t1.lastname() < t2.lastname() || t1.lastname() == t2.lastname() &&
t1.firstname() < t2.firstname();
}
};
int main()
{
set<TestA, TestB> sett;
TestA t1("liu", "san");
TestA t2("xiao", "ming");
TestA t3("zhang", "san");
TestA t4("wang", "xiao");
sett.insert(t1);
sett.insert(t2);
sett.insert(t3);
sett.insert(t4);
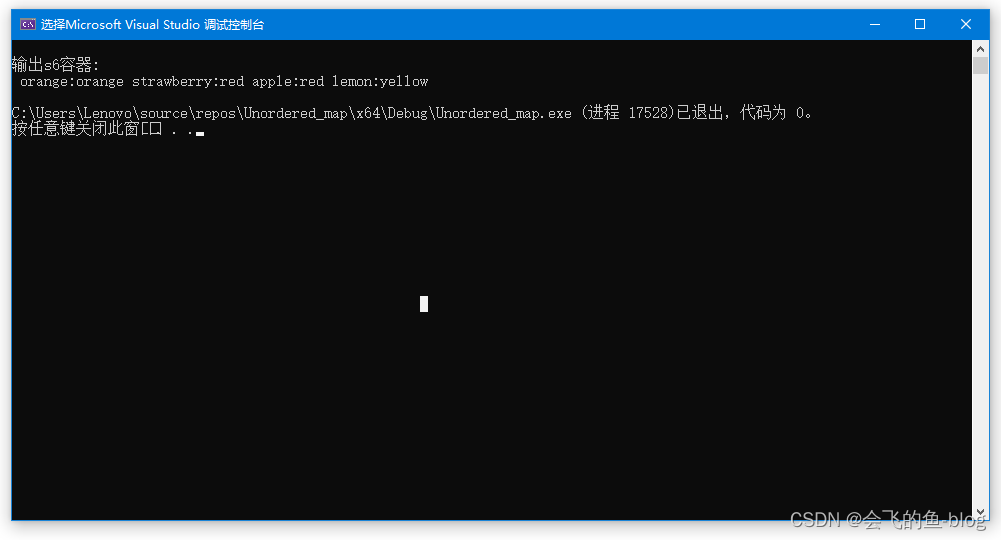
for (auto i : sett)
{
cout << i.lastname() << "," << i.firstname() << endl;
}
cout << endl;
return 0;
}
14、atomic_flag应用
Std::atomic_flag为原子布尔类型。它不同于所有std::atomic的特化,它保证是免锁。std::atomic<bool>,std::atomic_flag不提供加载或存储操作。
工程案例分析:
#include <iostream>
#include <atomic>
#include <vector>
#include <thread>
// ATOMIC_FLAG_INIT-->定义能以语句用于初始化操作,清除状态的初始化器
std::atomic_flag lock = ATOMIC_FLAG_INIT; //
void FuncAt(int args)
{
for (int i = 0; i < 10; i++)
{
while (lock.test_and_set(std::memory_order_acquire));// 获得锁
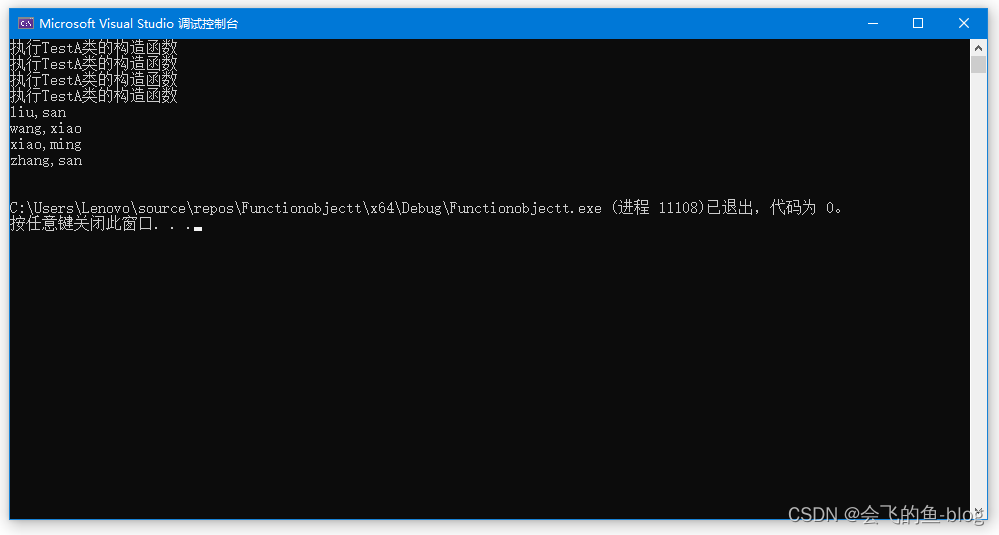
std::cout << "Output Threads:" << i << std::endl;
lock.clear(std::memory_order_release); // 释放锁
}
}
int main()
{
std::vector<std::thread> vct;
for (int i = 0; i < 2; i++)
{
vct.emplace_back(FuncAt, i);
}
for (auto& t : vct)
{
t.join();
}
return 0;
}
15、条件变量:condition_variable
C++ 11标准当中,使用条件变量condition_variable实现多线程间的同步操作;当条件不满足时,相关线程被一直阻塞,直到某种条件出现,这些线程才会被唤醒。
工程案例分析:
#include <iostream>
#include <thread>
#include <condition_variable>
#include <mutex>
std::mutex mx;
std::condition_variable scv;
bool ready = false;
void PrintID(int id)
{
std::unique_lock <std::mutex> lock(mx);
while (!ready)
{
scv.wait(lock); // 当前线程被阻塞,当全局标志位变为true之后,才唤醒
}
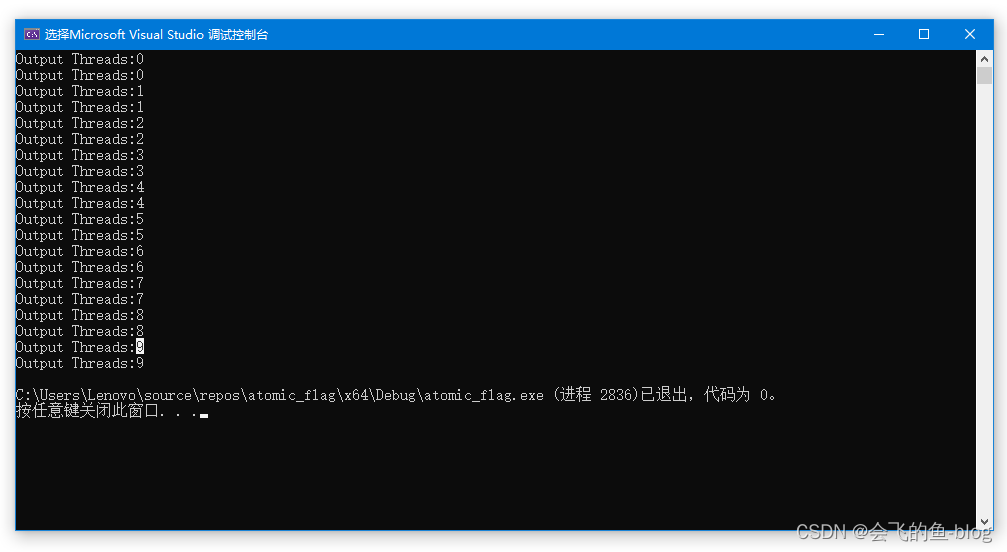
std::cout << "Threads : " << id << std::endl;
}
void RunFunc()
{
std::unique_lock <std::mutex> lock(mx);
ready = true; // 设置全局标志位为true
scv.notify_all(); // 唤醒所有线程
}
int main()
{
std::thread thrs[5];
for (int i = 0; i < 5; i++)
thrs[i] = std::thread(PrintID, i);
std::cout << "5 threads ready to race......\n";
RunFunc();
for (auto& t : thrs)
t.join();
return 0;
}
join()
join()字面意思是连接一个线程,意味着主动地等待线程的终止(线程阻塞)。在某个线程中通过子线程对象调用join()函数,调用这个函数的线程被阻塞,但是子线程对象中的任务函数会继续执行,当任务执行完毕之后,join()会清理当前子线程中的相关资源然后返回,同时,调用该函数的线程解除阻塞继续向下执行。join()函数在哪个线程中被执行,那么哪个线程就被阻塞。
// 子线程
void func()
{
cout << "子线程 " << endl;
}
// 主线程
cout << "主线程" << endl;
thread t(func); // 创建子线程
t.join(); // main线程中调用线程 t 的join函数,main线程随之被阻塞,不会向下执行
int x = 1;调用 join() 有两种情况:
如果任务函数func()还没执行完毕,主线程阻塞,直到子线程执行完毕,主线程解除阻塞,继续向下运行
如果任务函数func()已经执行完毕,主线程不会阻塞,继续向下运行
总的来说,t.join() 语句使得只有在子线程 t 完成执行之后,才能执行 int x = 1; 语句。线程执行完毕后,join() 会清理(回收)当前子线程的相关资源
detach()
detach() 函数的作用是进行线程分离,分离主线程和创建出的子线程。在线程分离之后,主线程退出也会一并销毁创建出的所有子线程,在主线程退出之前,它可以脱离主线程继续独立的运行,任务执行完毕之后,这个子线程会自动释放自己占用的系统资源。
注意事项:线程分离函数detach()不会阻塞线程,子线程和主线程分离之后,在主线程中就不能再对这个子线程做任何控制了,比如调用get_id()获取子线程的线程ID。
joinable()
joinable() 函数用于判断主线程和子线程是否处理关联(连接)状态,一般情况下,二者之间的关系处于关联状态,该函数返回一个布尔类型,有连接关系返回值为 true,否则返回 false。
16、异常处理:exception(头文件stdexcept)
C++语言标准库当中有一些类代表异常,这些类都是从exception类派生出来的,
比如:bad_typeid/bad_cast/bad_alloc/ios_base::failure等,它们都是从exception类派生类。
工程案例分析:
#include <iostream>
#include <stdexcept>
using namespace std;
class TestA
{
virtual void Func() {
}
};
class TestB :public TestA
{
public:
void disp() {
cout << "TestB OK." << endl;
}
};
void dispObject(TestA& t)
{
try
{
TestB& tb = dynamic_cast<TestB&>(t);
// 在此转换若不安全,会抛出bad_cast异常
tb.disp();
}
catch (bad_cast& e)
{
cerr << e.what() << endl;
}
}
int main()
{
TestA obja;
dispObject(obja);
return 0;
}
17、std::thread多线程
工程案例分析:
#include <iostream>
#include <thread>
using namespace std;
void ThreadFunc1()
{
cout << "ThreadFunc1()--A\n" << endl;
this_thread::sleep_for(std::chrono::seconds(2));
cout << "ThreadFunc1()--B" << endl;
}
void ThreadFunc2(int args,string sp)
{
cout << "ThreadFunc2()--A" << endl;
this_thread::sleep_for(std::chrono::seconds(7));
cout << "ThreadFunc2()--B" << endl;
}
int main()
{
thread ths1(ThreadFunc1);
thread ths2(ThreadFunc2,10,"LS");
ths1.join();
cout << "join" << endl;
ths2.detach();
cout << "detach" << endl;
return 0;
}
18、列表初始化
在C++98中,标准允许使用花括号{}对数组元素进行统一的列表初始值设定。C++98对于自定义类型,无法使用列表初始化,在C++11中改进了。
工程案例:
int array1[] = {1,2,3,4,5};
int array2[5] = {0};
C++11中自定义类型也可以使用列表初始化C++11扩大了用大括号括起的列表(初始化列表)的使用范围,使其可用于所有的内置类型和用户自定义的类型,使用初始化列表时,可添加等号(=),也可不添加。
内置类型的初始化列表
// 内置类型变量
int x1 = {10};
int x2{10};//建议使用原来的
int x3 = 1+2;
int x4 = {1+2};
int x5{1+2};
// 数组
int arr1[5] {1,2,3,4,5};
int arr2[]{1,2,3,4,5};
// 动态数组,在C++98中不支持
int* arr3 = new int[5]{1,2,3,4,5};
// 标准容器
vector<int> v{1,2,3,4,5};//这种初始化就很友好,不用push_back一个一个插入
map<int, int> m{{1,1}, {2,2,},{3,3},{4,4}};
自定义类型的列表初始化
//标准库支持单个对象的列表初始化
class Point
{
public:
Point(int x = 0, int y = 0): _x(x), _y(y)
{}
private:
int _x;
int _y;
};
int main()
{
Pointer p = { 1, 2 };
Pointer p{ 1, 2 };//不建议
return 0;
}
多个对象的列表初始化
多个对象想要支持列表初始化,需给该类(模板类)添加一个带有initializer_list类型参数的构造函数即可。
注意:initializer_list是系统自定义的类模板,该类模板中主要有三个方法:begin()、end()迭代器以及获取区间中元素个数的方法size()。
class Date
{
public:
Date(int year = 0, int month = 1, int day = 1)
:_year(year)
, _month(month)
, _day(day)
{
cout << "这是日期类" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
//C++11容器都实现了带有initializer_list类型参数的构造函数
vector<Date> vd = { { 2022, 1, 17 }, Date{ 2022, 1, 17 }, { 2022, 1, 17 } };
return 0;
}
19、final 和 override
19.1、final
19.1.1、final第一种用法
final修饰类的时候,表示该类不能被继承
工程案例:
class A final //表示该类是最后一个类
{
private:
int _year;
};
class B : public A //无法继承
{
};
19.1.2、final第二种用法
final修饰虚函数时,这个虚函数不能被重写
class A
{
public:
virtual void fun() final//修饰虚函数
{
cout << "this is A" << endl;
}
private:
int _year;
};
class B : public A
{
public:
virtual void fun()//父类虚函数用final修饰,表示最后一个虚函数,无法重写
{
cout << "this is B" << endl;
}
};
19.2、override
检查派生类虚函数是否重写了基类某个虚函数,如果没有重写编译报错
class A
{
public:
virtual void fun()
{
cout << "this is A" << endl;
}
private:
int _year;
};
class B : public A
{
public:
virtual void fun() override
{
cout << "this is B" << endl;
}
};
20、default 和 delete
在C++中对于空类编译器会生成一些默认的成员函数,比如:构造函数、拷贝构造函数、运算符重载、析构函数和&和const&的重载、移动构造、移动拷贝构造等函数。如果在类中显式定义了,编译器将不会重新生成默认版本。有时候这样的规则可能被忘记,最常见的是声明了带参数的构造函数,必时则需要定义不带参数的版本以实例化无参的对象。而且有时编译器会生成,有时又不生成,容易造成混乱,于是C++11让程序员可以控制是否需要编译器生成。
20.1、显示缺省函数
在C++11中,可以在默认函数定义或者声明时加上=default,从而显式的指定编译器生成该函数的默认版本(默认成员函数),用=default修饰的函数称为显式缺省函数。
class A
{
public:
A() = default;//让编译器默认生成无参构造函数
A(int year) //这样不写缺省值的时候,就不需要自己在去实现一个默认的无参构造函数
:_year(year)
{}
void fun()
{
cout << "this is A" << endl;
}
private:
int _year;
};
20.2、删除默认函数(禁止调用)
如果能想要限制某些默认函数的生成,在C++98中,是该函数设置private,并且不给定义,这样只要其他人想要调用就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
class A
{
public:
A() = default;
A(int a) : _a(a)
{}
//C++11
// 禁止编译器生成默认的拷贝构造函数以及赋值运算符重载
A(const A&) = delete;
A& operator=(const A&) = delete;
private:
int _a;
//C++98,设置成private就可以了
A(const A&) = delete;
A& operator=(const A&) = delete;
};
21、左值引用和右值引用
传统的C++就有引用,称为左值引用,C++11后,出了右值引用。无论是左值引用还是右值引用,都是给对象取别名(与对象共享一片空间)。
21.1、什么是左值?什么是左值引用?
左值是一个表示数据的表达式(如变量名和解引用的指针),我们可以获取它的地址,也可以对它赋值,左值可以出现在赋值符号的左边,右值不可以出现在左边。左引用加const修饰,不能对其赋值,但可取地址,是一种特殊情况。左值引用就是给左值取别名。
左值:
(1)、可以取地址
(2)、一般情况下可以修改(const修饰时不能修改)(3)、左值引用只能引用左值,不能引用右值
(4)const左值引用既可引用左值,也可引用右值
工程案例:
//以下都是左值
int* p = new int[10];
int a = 10;
const int b = 20;
//对左值的引用
int*& pp = p;
int& pa = a;
const int& rb = b;
21.2、什么是右值?什么是右值引用?
右值也是一个表示数据的表达式,如:字面常量、表达式返回值、传值返回函数的返回值(不能是左值引用返回)等,右值可以出现在赋值符号的右边,但是不能出现在左边。右值引用就是给右值取别名。move:当需要用右值引用引用一个左值时,可以通过move函数将左值转化为右值。C++11中,std::move()函数位于头文件中,该函数名字具有迷惑性,它并不搬移任何东西,唯一的功能就是将一个左值强制转化为右值引用,然后实现移动语义。
右值:
(1)、右值引用只能引用右值,一般情况下不能引用左值
(2)、右值引用可以引用move以后的左值
工程案例:
double x = 1.1, y = 2.2;
//常见右值
10;
x + y;
add(1, 2);
//右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double && rr3 = add(1, 2);
//右值引用一般情况不能引用左值,可使用move将一个左值强制转化为右值引用
int &&rr4 = move(x);
//右值不能出现在左边,错误
10 = 1;
x + y = 1.0;
add(1, 2) = 1;
左值引用既可以引用左值,可以引用右值,为什么C++11还要提出右值引用?因为左值引用存在短板,下面我们来看看这个短板以及右值引用是如何弥补这个短板的!
void fun1(bit::string s)
{
}
void fun2(bit::string& s)
{
}
int main()
{
bit::string s("1234");
//fun1(s);
//fun2(s);//左值引用提高了效率,不存在拷贝临时对象的问题
//可以使用左值引用返回,这个对象还在
s += 'a';
//不能使用左值引用返回,这个就是左值引用的一个短板
//函数返回对象出了作用域就不在了,就不能用左值引用返回(因为返回的是本身地址,栈帧已销毁)
//所以会存在拷贝问题
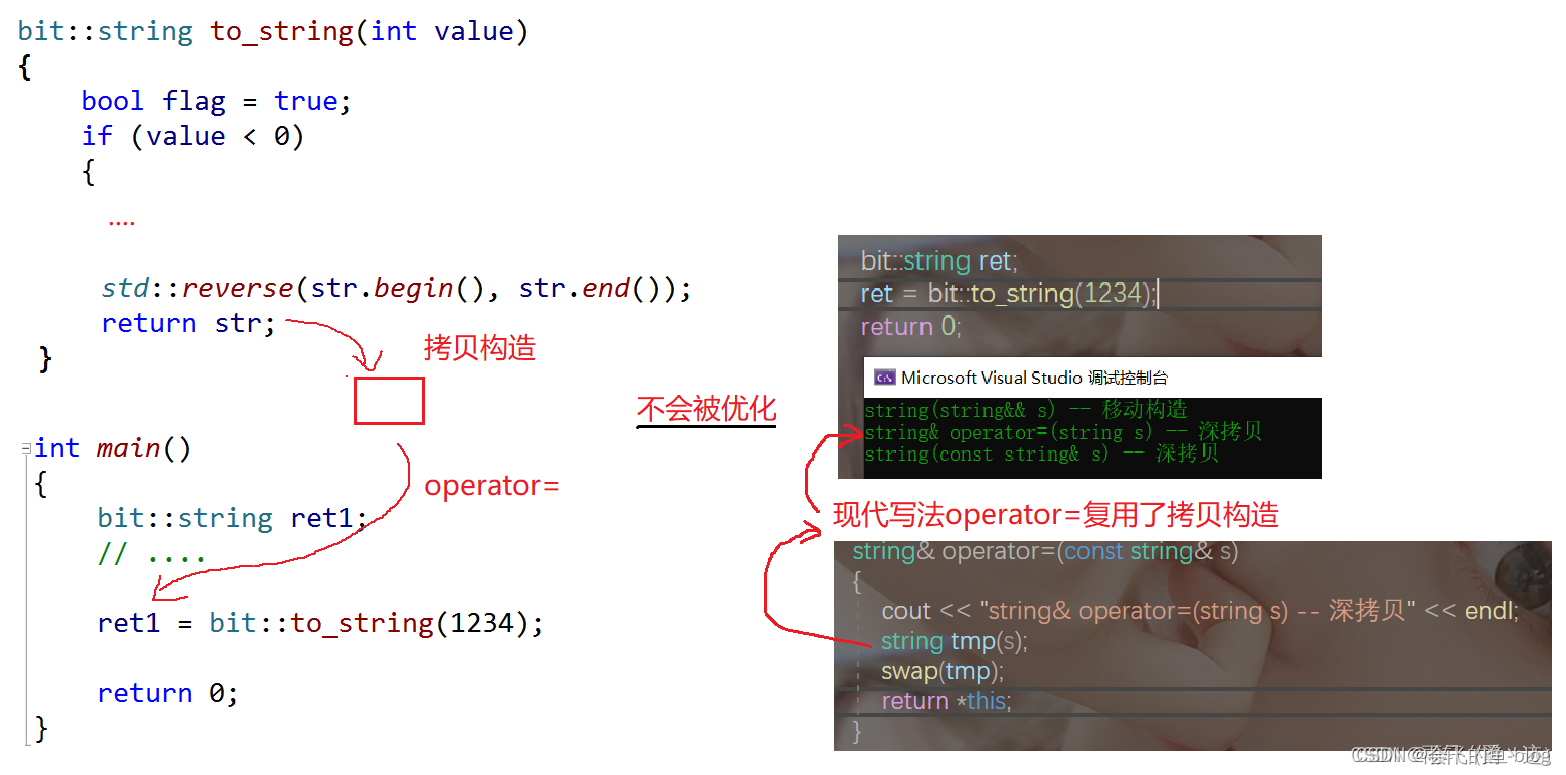
bit::string ret = bit::to_string(1234);
return 0;
}
短板(右值引用场景1)
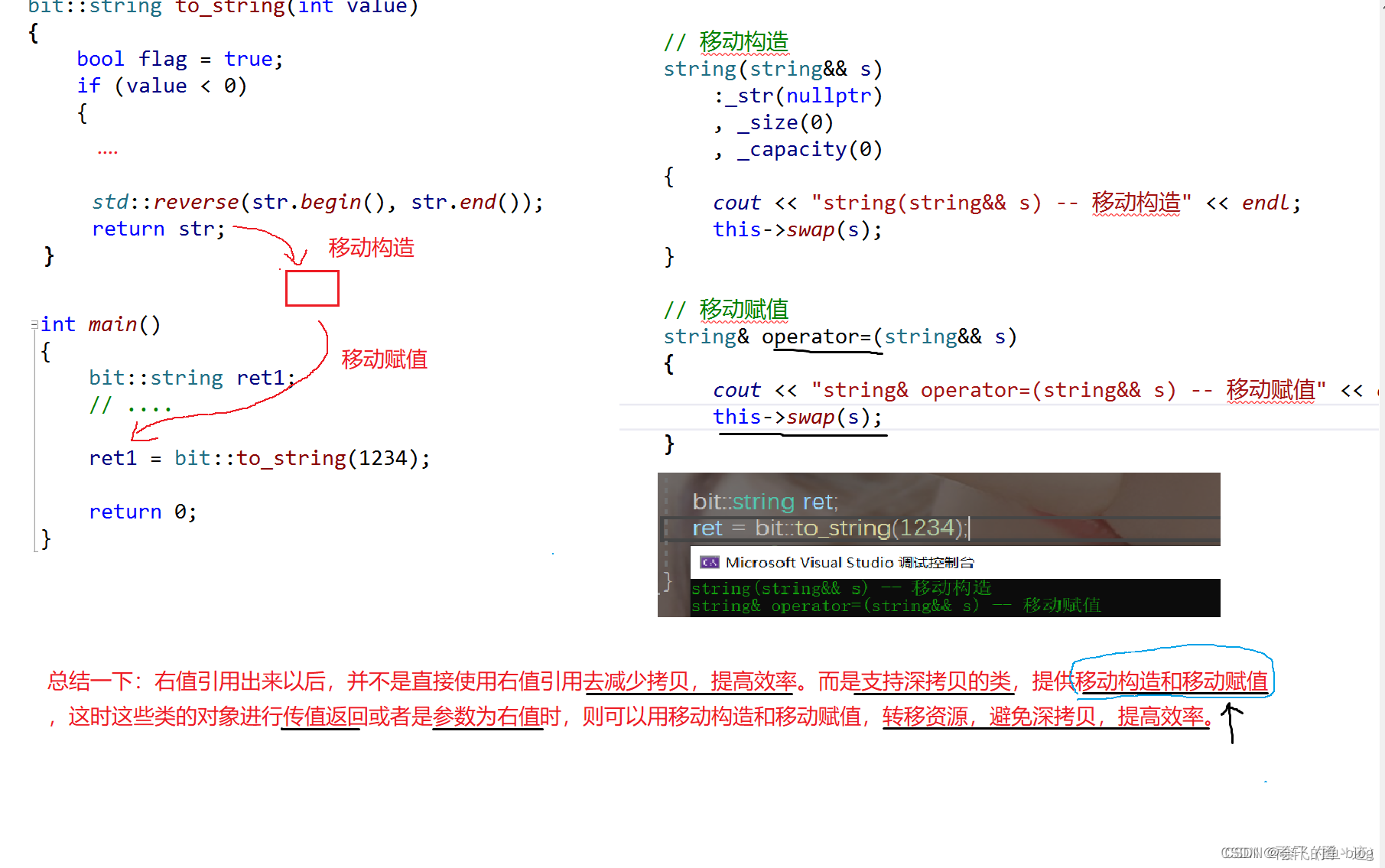
C++11移动语义的提出:将一个对象中资源移动到另一个对象中的方式。
str在按照值返回时,必须创建一个临时对象,临时对象创建好之后,str就被销毁了,str是一个将亡值,C++11认为其为右值,在用str构造临时对象时,就会采用移动构造,即将str中资源转移到临时对象中。而临时对象也是右值,因此在用临时对象构造s3时,也采用移动构造,将临时对象中资源转移到ret中,整个过程,只需要创建一块堆内存即可,既省了空间,又大大提高程序运行的效率。
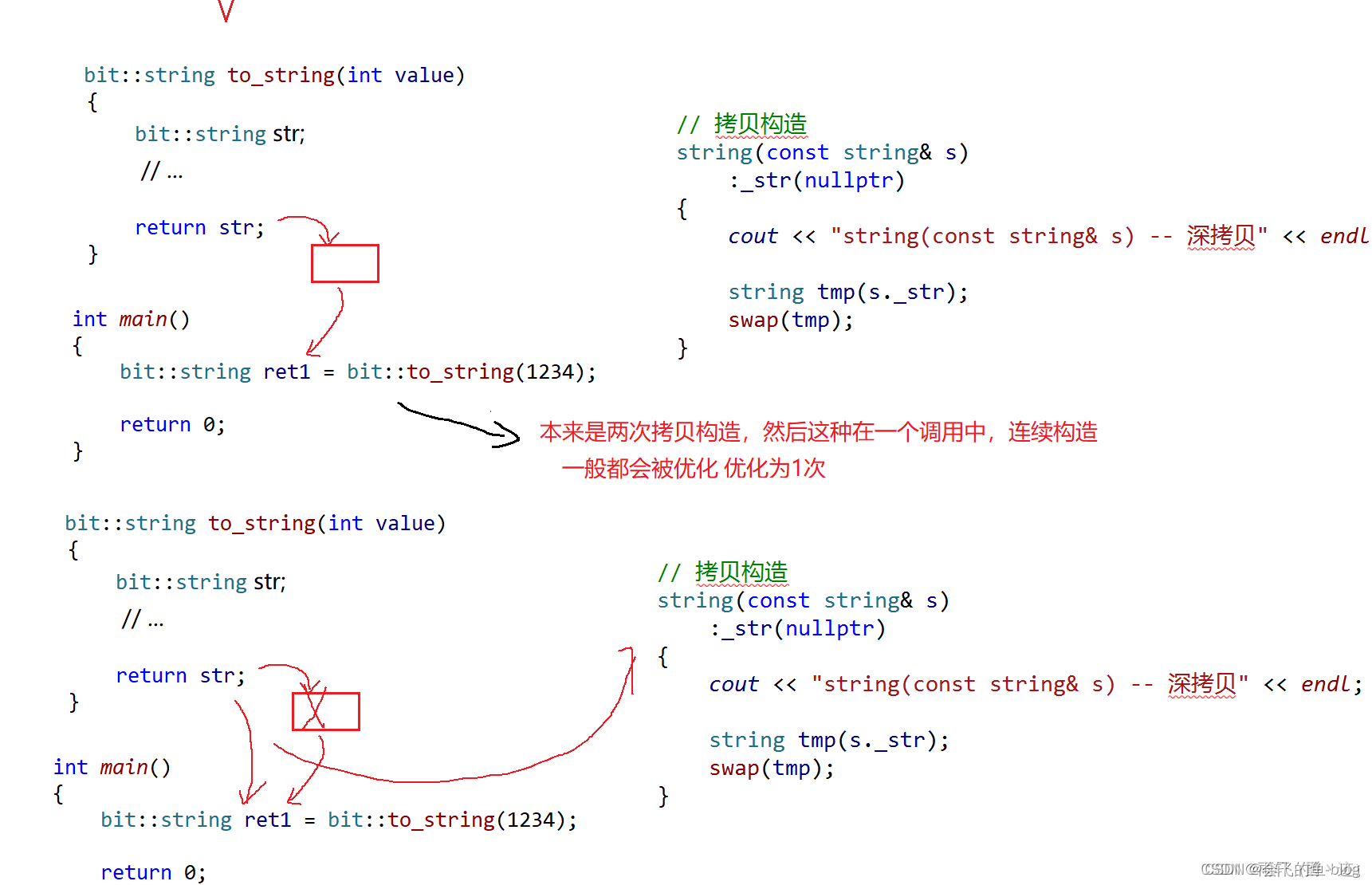
这里我们就又可以对右值进行一个定义:
右值:1、纯右值 10 a+b 2、将亡值,函数返回的临时对象,匿名对象
此时我们将这一条语句分开写,看看又是什么情况
bit::string ret;
ret = bit::to_string(1234);//赋值重载多了一次拷贝构造
以上是右值使用的场景1
//左值,拷贝构造,使用左值引用
list<bit::string> lt;
bit::string s("1234");
lt.push_back(s);
//以下传的都是右值,右值引用,所以是移动构造
lt.push_back("123");
lt.push_back(bit::string("2121"));
lt.push_back(std::move(s));
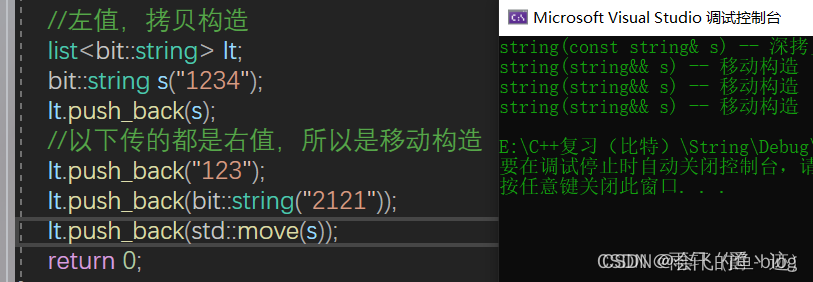
总结一下:右值引用使用场景二,还可以使用在容器插入接口函数中,如果实参是右值,则可以转移它的资源,减少拷贝
22、完美转发
完美转发是指在函数模板中,完全依照模板的参数的类型,将参数传递给函数模板中调用的另外一个函数。
工程案例:
void Func(int x)
{
cout << x << endl;
}
template<typename T>
void PerfectForward(T&& t)
{
Func(t);
}
PerfectForward为转发的模板函数,Func为实际目标函数,但是上述转发还不算完美,完美转发是目标函数总希望将参数按照传递给转发函数的实际类型转给目标函数,而不产生额外的开销,就好像转发者不存在一样。
所谓完美:函数模板在向其他函数传递自身形参时,如果相应实参是左值,它就应该被转发为左值;如果相应实参是右值,它就应该被转发为右值。这样做是为了保留在其他函数针对转发而来的参数的左右值属性进行不同处理(比如参数为左值时实施拷贝语义;参数为右值时实施移动语义)。
我们先来了解万能引用
(1)、模板中的&&不代表右值引用,而是万能引用,其既能接收左值又能接收右值。
(2)、模板的万能引用只是提供了能够接收同时接收左值引用和右值引用的能力
(3)、但是引用类型的唯一作用就是限制了接收的类型,后续使用中都退化成了左值
(4)、我们希望能够在传递过程中保持它的左值或者右值的属性,就需要用我们下面学习的完美转发
C++11通过forward函数来实现完美转发
工程案例:
void Func(int& x) { cout << "左值引用" << endl; }
void Func(const int& x) { cout << "const 左值引用" << endl; }
void Func(int&& x) { cout << "右值引用" << endl; }
void Func(const int&& x) { cout << "const 右值引用" << endl; }
template<typename T>
void PerfectForward(T&& t)
{
//Func(t);//没有使用forward保持其右值的属性,退化为左值
Func(forward<T>(t));
}
int main()
{
PerfectForward(1);//右值
int a = 10;
PerfectForward(a);
PerfectForward(move(a));
const int b = 20;
PerfectForward(b);
PerfectForward(move(b));
return 0;
}
总结:
右值引用的对象,再作为实参传递时,属性会退化为左值,只能匹配左值引用。使用完美转发,可以保持他的右值属性
23、可变参数列表
C++11的新特性可变参数模板能够让您创建可以接受可变参数的函数模板和类模板,相比C++98/03,类模版和函数模版中只能含固定数量的模版参数,可变模版参数无疑是一个巨大的改进。
工程案例:
//可变参数,你传int,char,还是自定义都会自动给你推导
可以包含0-任意个参数
template<class ...Args>
void ShowList(Args... args)
{
cout << sizeof...(args) << endl;//计算个数
}
int main()
{
ShowList(1, 2, 3);
ShowList(1, 'a');
ShowList(1, 'A', string("sort"));
return 0;
}
对比其值:
//需要加上结尾函数
void ShowList()
{
cout << endl;
}
template <class T, class ...Args>
void ShowList(T value, Args... args)
{
cout << value << " ";
ShowList(args...);//不断调用自己,直到最后参数为空,调用上面的结尾函数
}
接下来我们在看看可变参数在列表初始化的应用
template<class ...Args>
void ShowList(Args... args)
{
int arr[ ] = { args... };//可变参数初始化列表
cout << endl;
}
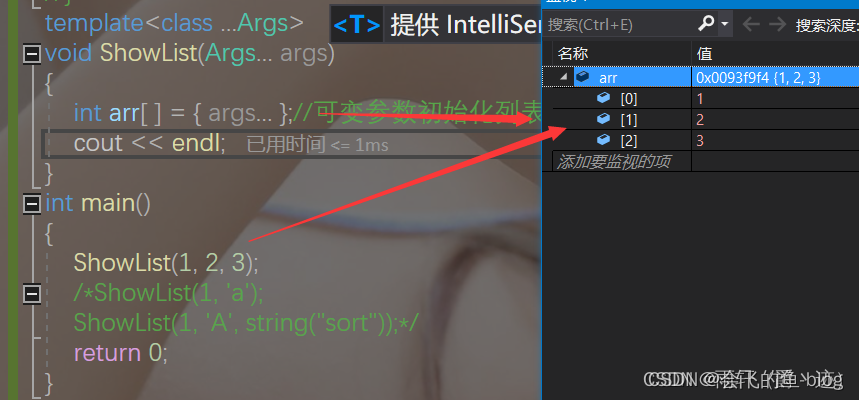
我们这里列表初始化内部都是一样的数据,如果我们要传不一样的数据,该如何实现?
C++11,利用逗号表达式调用例外一个函数,最后的0留给数据。
template <class T>
void PrintArg(T t)
{
cout << t << " ";
}
template <class ...Args>
void ShowList(Args... args)
{
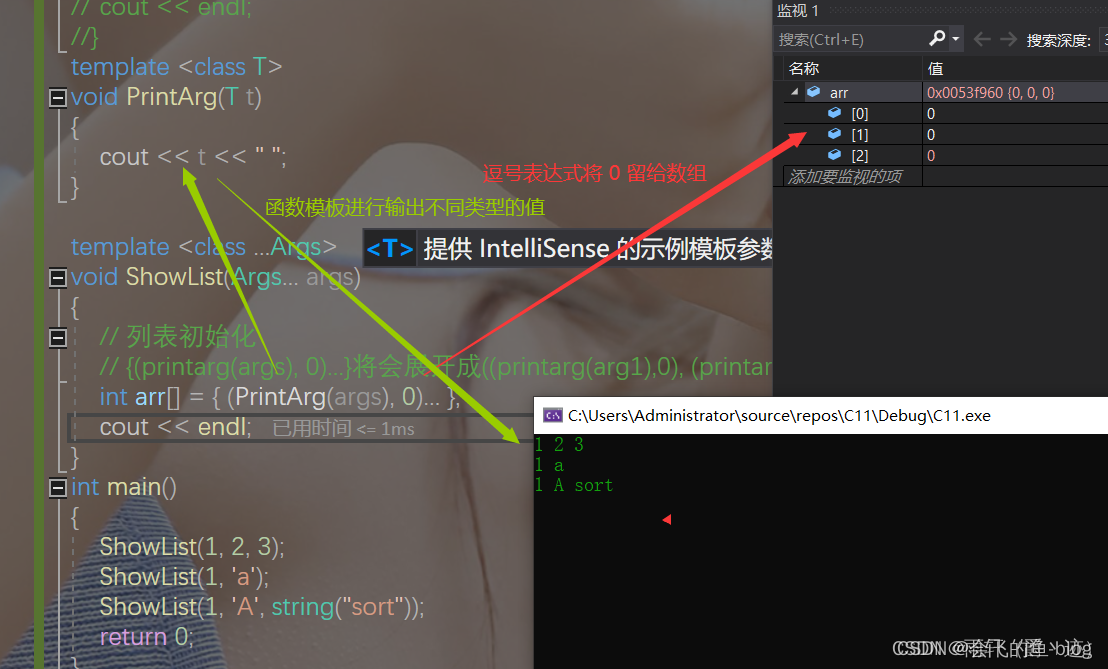
// 列表初始化
// {(printarg(args), 0)...}将会展开成((printarg(arg1),0), (printarg(arg2),0), (printarg(arg3),0), etc... )
int arr[] = { (PrintArg(args), 0)... };
cout << endl;
}
int main()
{
ShowList(1, 2, 3);
ShowList(1, 'a');
ShowList(1, 'A', string("sort"));
return 0;
}
也可以给模板函数设置一个返回值
template <class T>
int PrintArg(T t)
{
cout << t << " ";
return 0;
}
template <class ...Args>
void ShowList(Args... args)
{
// 列表初始化
//也可以给模板函数设置一个返回值
int arr[] = { PrintArg(args)... };
cout << endl;
}

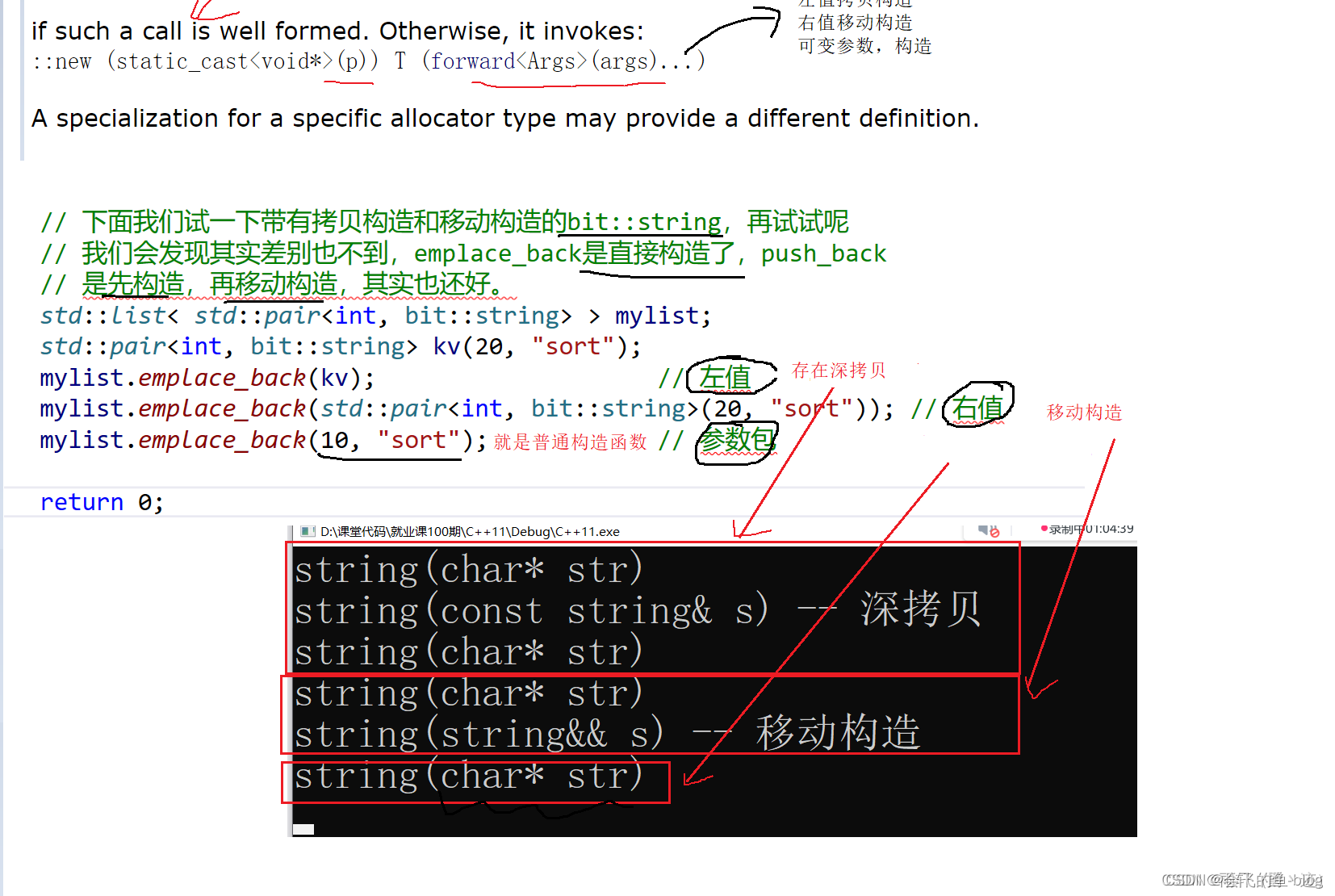
可变参数包结合完美转发的好处
直接就是普通构造函数的形式,不存在移动构造或者拷贝构造,节省空间
参考链接:
C++11特性(详细版)-CSDN博客