获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读
探索连续学习中的新方法
在人工智能领域,尤其是在语言模型(LM)的发展过程中,连续学习(CL)始终是一个挑战。传统的学习方法往往面临着灾难性遗忘的问题,即新知识的学习可能会导致旧知识的丢失。这一问题不仅影响模型的长期稳定性,还可能限制其在实际应用中的效能。
为了解决这一问题,研究者们提出了多种策略,如重复学习、架构调整和参数调整等方法。然而,这些方法往往依赖于旧任务数据或任务标签,而这在实际应用中可能难以获得。因此,探索不依赖外部标签和数据的连续学习新方法显得尤为重要。
最近,一种名为“MIGU”(基于幅度的梯度更新)的新方法应运而生,它通过利用语言模型线性层输出的L1标准化幅度分布的内在差异,实现了无需任务标签和重复数据的连续学习。这一方法的核心在于,在模型的前向传播阶段捕获并标准化线性层的输出,然后在反向传播阶段,只更新那些具有最大L1标准化幅度的参数。这种策略不仅简化了学习过程,还有效地利用了模型固有的行为特征,从而解锁了其连续学习的潜能。
通过在不同的语言模型架构和连续学习基准上的实验验证,MIGU方法在不同的连续微调和连续预训练设置中均展示了出色的性能,甚至在某些情况下超越了现有的最先进方法。例如,在一个包含15个任务的连续学习基准测试中,MIGU方法使得模型的平均准确率比传统的参数高效微调基线提高了15.2%。
此外,MIGU方法的灵活性也体现在其能够与现有的连续学习方法(如重复学习、架构基方法和参数基方法)无缝集成,进一步提升了模型的连续学习能力。这一创新的探索不仅为连续学习领域提供了新的视角,也为实际应用中的语言模型持续优化和更新开辟了新的可能性。
1. 论文标题:Unlocking Continual Learning Abilities in Language Models
2. 机构:
- Wenyu Du, Ka Chun Cheung, Reynold Cheng: The University of Hong Kong
- Shuang Cheng: ICT, Chinese Academy of Sciences
- Tongxu Luo: CUHK-SZ
- Zihan Qiu, Zeyu Huang: Tsinghua University
- Ka Chun Cheung: NVIDIA
- Jie Fu: HKUST
3. 论文链接:https://arxiv.org/pdf/2406.17245.pdf
4. 项目地址:https://github.com/wenyudu/MIGU
MIGU方法介绍
在持续学习(CL)的领域中,语言模型(LM)面临着灾难性遗忘的挑战,这限制了它们在持续学习任务中的长期可持续性。为了解决这一问题,研究人员提出了多种方法,包括基于复习的方法、基于架构的方法和基于参数的方法。然而,这些方法往往依赖于旧任务数据或任务标签,这在实际应用中可能难以获取或成本较高。
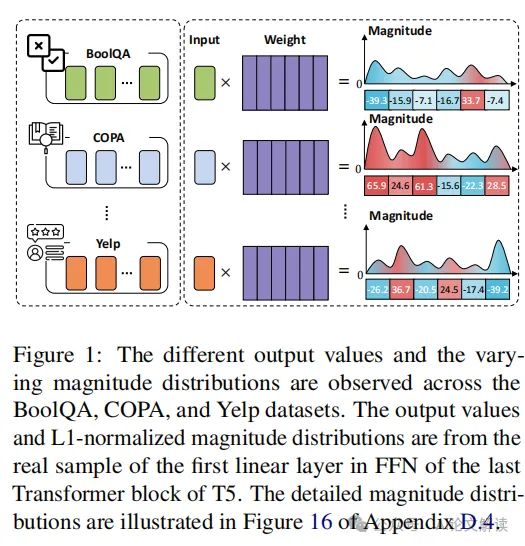
针对这一挑战,本文介绍了一种名为“MIGU”(基于幅度的梯度更新)的新方法。MIGU方法不需要复习旧任务数据,也不需要任务标签,它通过只更新输出幅度较大的模型参数来实现持续学习。这种方法利用了语言模型线性层输出的L1标准化幅度分布的固有差异,这些差异在处理不同任务数据时表现不同。
1. MIGU的工作原理
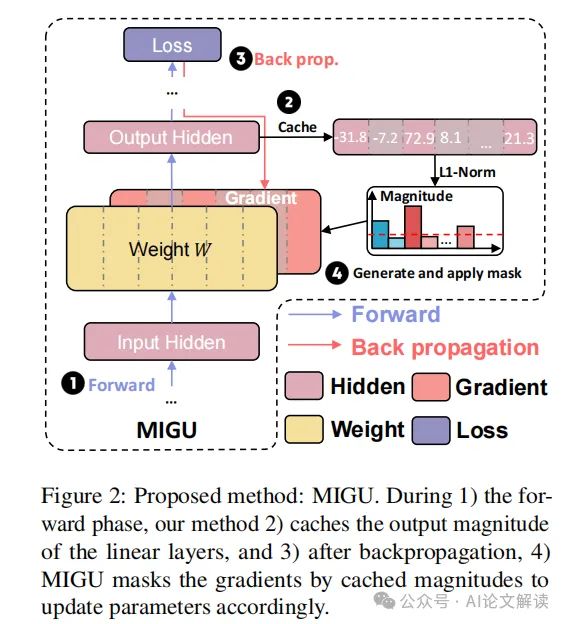
MIGU方法包括两个主要步骤:在前向传播阶段,缓存并标准化线性层的输出幅度;在后向传播阶段,只更新那些L1标准化幅度最大的参数。具体来说,MIGU在模型的前向传播阶段计算每个线性层的输出,然后使用L1范数对这些输出进行标准化,得到一个幅度分布向量。在后向传播阶段,MIGU根据预定义的阈值比例T,只更新幅度最大的参数,从而有效地利用语言模型处理不同任务时输出幅度的固有差异,减少不同任务间的梯度冲突,解锁模型的持续学习能力。
2. MIGU的实验验证
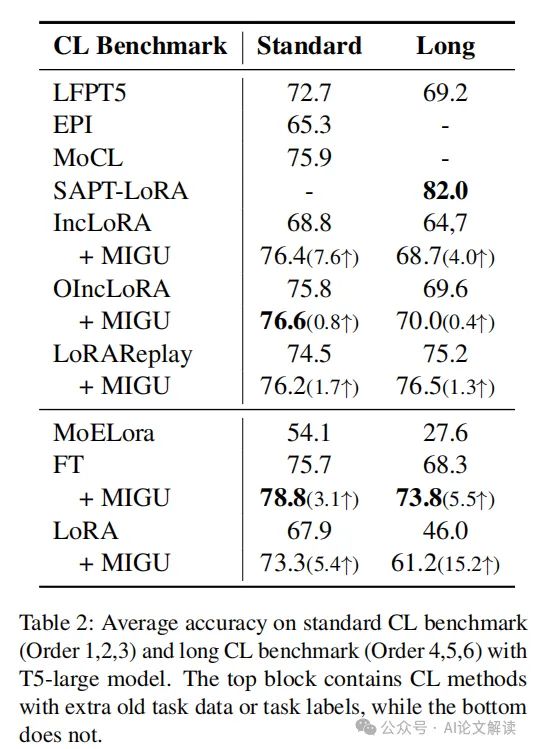
MIGU方法已在三种主要的语言模型架构(T5、RoBERTa和Llama2)上进行了测试,并在持续微调和持续预训练的设置中,针对四个持续学习基准进行了评估。实验结果显示,MIGU在所有测试中均达到了最先进或相当的性能。例如,在一个包含15个任务的持续学习基准测试中,MIGU使平均准确率比传统的参数高效微调基线提高了15.2%。
实验设计与数据集
在探索语言模型(LMs)的持续学习(CL)能力的研究中,我们提出了一种名为“MIGU”(基于幅度的梯度更新)的新方法。这种方法利用了语言模型线性层输出的L1标准化幅度分布的固有差异,实现了无需任务标签的持续学习。这一发现基于对不同任务数据处理时线性层输出幅度分布的观察。例如,在T5模型的最后一个Transformer块的前馈网络(FFN)的第一线性层中,对于BoolQA、COPA和Yelp三个任务,幅度分布有显著不同。
实验设计
在实验中,我们首先在前向传播阶段缓存并标准化线性层的输出幅度,然后在反向传播阶段,只更新L1标准化幅度最大的T个参数,其中T是预定义的阈值比率。这种设计使得模型能够针对不同任务有效地利用其固有特征来更新参数,从而缓解任务间的梯度冲突,释放其持续学习的潜力。
数据集
我们在三种主要的语言模型架构上评估了MIGU方法:仅编码器的RoBERTa、编码器-解码器的T5模型和仅解码器的Llama2。实验涉及两种持续预训练设置:持续预训练和持续微调,使用四个CL基准数据集。这些数据集包括标准CL基准和长序列CL基准,涵盖了多种文本分类任务和问答任务。例如,在一个包含15个任务的长序列CL数据集中,MIGU方法使平均准确率相比传统的参数高效微调基线提高了15.2%。
通过这些设计和数据集的使用,我们的实验不仅验证了MIGU方法在不同语言模型架构和持续学习场景下的有效性,还展示了它如何与现有的三种主流CL方法(基于复习的方法、基于架构的方法和基于参数的方法)无缝集成,进一步增强了语言模型的CL能力。
实验结果与分析
在探索语言模型(LMs)的持续学习(CL)能力的过程中,我们引入了一种名为“MIGU”的新方法(基于幅度的梯度更新),这种方法利用LMs线性层中L1标准化输出的幅度分布的固有差异,实现了无需任务标签的持续学习。通过实验,我们在三种主要的LM架构(T5, RoBERTa和Llama2)上验证了MIGU的效果,并在四个CL基准测试中进行了持续的微调和持续的预训练设置测试。
1. 实验设置与基准测试
我们在不同的持续学习设置中评估了MIGU,包括持续微调和持续预训练。使用的基准数据集包括标准CL基准和长序列CL基准,以及用于持续预训练的DAS基准。这些基准覆盖了从文本分类到领域适应的多种任务。
2. 实验结果
在T5-large模型上的持续微调实验中,MIGU在没有旧任务数据或任务信息的情况下,与传统的参数高效微调基线相比,平均准确率提高了15.2%。此外,MIGU与现有的三种CL方法(基于重演的、基于架构的和基于参数的方法)无缝集成,进一步增强了LMs的CL能力。
在RoBERTa模型的持续预训练实验中,MIGU也显示出与或优于其他先进CL方法的性能。例如,在DAS基准测试中,FT+MIGU在MF1和ACC指标上均实现了改进。
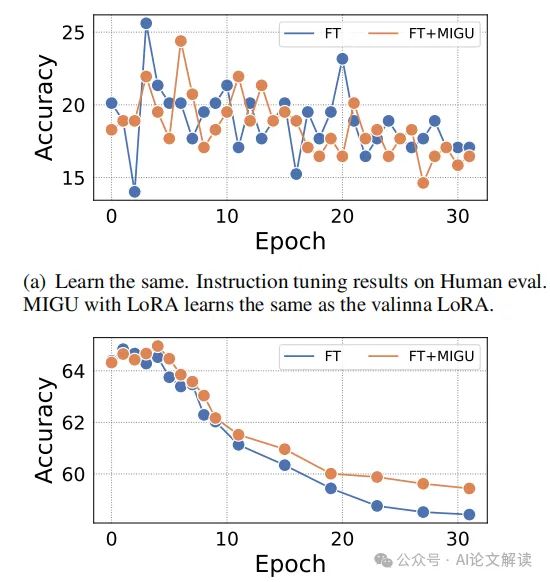
3. 分析与讨论
MIGU通过在后向传播阶段仅更新具有最大L1标准化幅度的参数,有效地利用了任务间的幅度分布差异,减少了不同任务间的梯度冲突。这种方法不仅减少了对旧任务数据的依赖,而且也避免了在LMs场景中获取精确任务标签的困难。
我们的实验结果表明,MIGU能够显著提高在多任务学习环境中的模型性能,特别是在处理长序列任务和需要高度领域适应性的场景中。此外,MIGU的实现简单,计算效率高,易于与现有的CL策略集成,为未来的研究和应用提供了新的可能性。
通过这些实验,我们证明了MIGU方法在解锁LMs的持续学习潜力方面的有效性和通用性,为持续学习的未来研究提供了新的视角和工具。
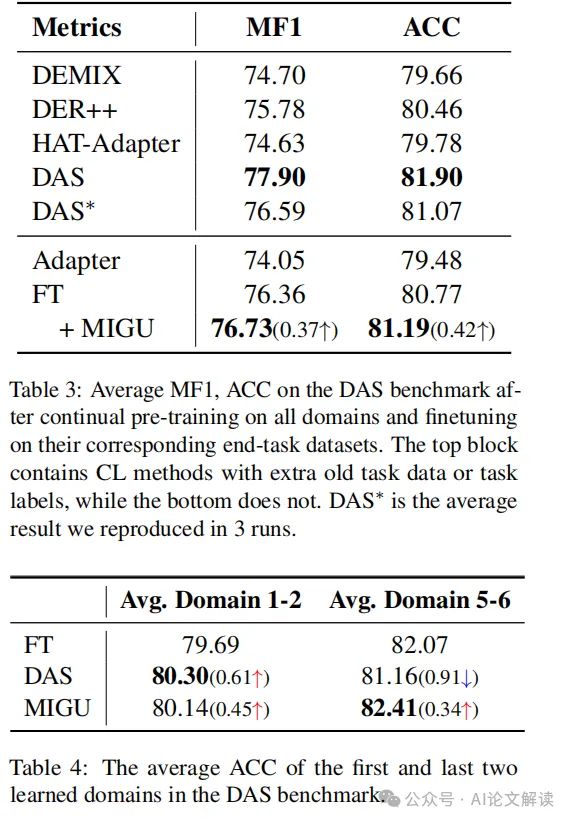
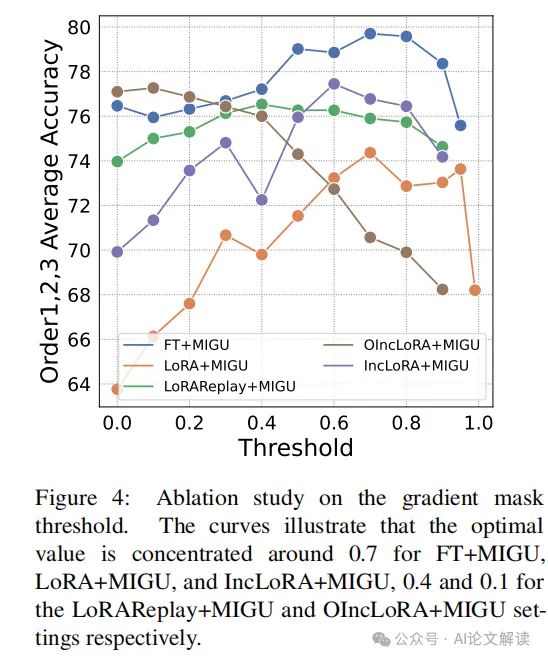
MIGU的优势与挑战
MIGU(基于幅度的梯度更新)是一种针对语言模型(LM)持续学习的新方法,它通过利用LM线性层输出的L1标准化幅度分布的固有差异,实现了无需任务标签和重复训练数据的模型参数更新。这种方法在多个持续学习(CL)基准测试中展示了其有效性,能够显著提高模型在多任务学习环境中的表现,并且与现有的CL方法(如重复训练、架构调整和参数调整方法)无缝集成,进一步增强了模型的CL能力。
1. MIGU的优势
MIGU的主要优势在于其独特的更新机制,该机制只更新那些具有较大L1标准化幅度的参数,从而有效减少了不同任务间的梯度冲突,解决了传统CL方法中常见的灾难性遗忘问题。例如,在一个包含15个任务的CL基准测试中,MIGU比传统的参数高效微调基线提高了15.2%的平均准确率。此外,MIGU不依赖于旧任务数据或精确的任务标签,使其在数据获取成本高或数据不可用的情况下尤为有用。
2. MIGU的挑战
尽管MIGU在多个方面表现出色,但它也面临一些挑战。首先,MIGU依赖于模型线性层输出的幅度分布差异,这需要模型能够在不同任务之间展示出足够的幅度变化,这在某些情况下可能不容易实现。其次,尽管MIGU减少了对旧任务数据的依赖,但在没有任何任务标签的情况下,如何有效地区分和处理不同任务的学习过程仍然是一个开放的问题。此外,MIGU的效果可能受到模型架构和任务性质的限制,其在不同类型的语言模型和任务上的普适性和效率仍需进一步验证。
总体而言,MIGU提供了一种创新的解决方案来增强语言模型的持续学习能力,通过简单的幅度基准更新机制解锁了模型的潜在CL能力,尽管存在挑战,但其在实际应用中的潜力值得进一步探索和优化。
结论与未来展望
在本研究中,我们提出了一种名为MIGU(基于幅度的梯度更新)的新方法,用于解决语言模型(LMs)在持续学习(CL)中的灾难性遗忘问题。MIGU方法通过利用LMs线性层输出的L1标准化幅度分布的固有差异,实现了无需任务标签和重复样本的持续学习。我们的实验结果表明,MIGU在多种LM架构和持续学习场景中均表现出色,能够与现有的CL方法无缝集成,进一步提升性能。
1. 性能提升
MIGU在多个持续学习基准测试中取得了显著的性能提升。例如,在一个包含15个任务的长序列CL基准测试中,MIGU使得模型的平均准确率比传统的参数高效微调基线提高了15.2%。这一结果证明了MIGU在处理多任务学习和避免任务间梯度冲突方面的有效性。
2. 与现有CL方法的集成
MIGU能够与重复基、架构基和参数基的CL方法无缝集成,进一步增强了LMs的持续学习能力。通过与这些方法的结合,MIGU不仅提高了模型在新任务上的学习能力,还有效减少了对旧任务知识的遗忘。
3. 未来研究方向
尽管MIGU已经取得了一定的成功,但我们认为还有几个方向值得进一步探索:
- 扩展到更大规模的模型和任务:未来可以考虑将MIGU应用于更大规模的LMs和更复杂的任务序列,以测试其在更广泛应用中的效果。
- 探索其他内在特征:除了输出幅度分布,LMs可能还有其他未被充分利用的内在特征。未来的研究可以探索这些特征在CL中的潜在用途。
- 优化计算效率:虽然MIGU已经相对高效,但在处理大规模数据和模型时,进一步优化其计算效率仍然很有必要。