背景
刚参加完24年世界人工智能大会(WAIC),聊聊自己的一些感受。这次会明显比去年多很多人,用人山人海来形容应该也不为过。根据我自己粗浅观察参会的人员也比去年更多样化。去年更多还是从业者或者是这块研究人员。今年每个论坛各种角色人都有,销售、技术、算法、研究人员、产业实践方…去年更多是一些技术展望和技术方向内容,今年很明显看到应用和实践报告多起来了(各大家争相在会议期间发布自己AI产品)。会议主题基本就围绕大模型和人形机器人这两大主题展开,从展会内容看咋一看同质化挺严重。但是因为这也是大模型(23年技术元年)到今年应用元年,有很多类似思路也正常。打上同质化背后其实也可以看到各大家在努力结合自己产业特点制造一些差异化,相信明年会看到更多更实用和差异化的思路和产品。
1.算力
2.个大模型+应用
3.人形机器人
4.机器人核心配件
基本就这几个套路。从产品完整度看呢,个人觉得AI在教育上的应用做的还是不错的,这有点超出我的预期。估计这和国家几年前就在推教育数字化有很大关系,这块产品他们应该是深根很多年,大模型的出现只是让以前技术很难实现的事得以更快速实现。所以从产品形态、完整度、实用性角度看,感觉都比AIGC在工业应用更实在,更不那么toy。
其实这样侧面证明一个推测,大模型下的这波AI应该死人机协作,知识工程是非常重要的 一个环节。业务域的中小企业其实应该把业务知识整理梳理清楚做深才是壁垒,光做工具的企业可能会受到冲击。
也是有感于这次会议,想开一个AI Native的应用系列。这个系列定位就是只讲实现落地,纯AI技术的整合,更偏向工具实现,不讲AI背后技术的原理,也不太讲具体某个行业业务逻辑,只是秀工具功能。这么做的目的也是希望能给有很强业务sence的企业在寻找一些技术赋能、找一些可用工具的时候降低他们门槛,让他们可用快速的把工具结合自己业务测试起来。
操作手册
这篇文章给大家介绍一个纯AI驱动的单图数字人工具,主要包括5个部分:
1.单图生成AI
2.文本生成AI
3.声音克隆AI
4.动作生成AI
5.嘴形生成AI
环境搭建
用指令创建初始化环境:
#创建指定python版本虚拟环境
conda create -n lumina python=3.11
conda activate lumina
单图生成模块
生成图,选用上海人工智能研究所的Lumina架构,具体信息可用看他们官网(https://github.com/Alpha-VLLM/Lumina-T2X.git)
具体环境安装如下:
#下载lumina源码
git clone https://github.com/Alpha-VLLM/Lumina-T2X.git
conda activate lumina
#安装需要工具包
pip install -q flash_attn==2.5.9.post1 --no-build-isolation
pip install git+https://github.com/Alpha-VLLM/Lumina-T2X
#下载模型参数
apt -y install -qq aria2
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/Lumina-Next-SFT/resolve/main/consolidated_ema.00-of-01.safetensors -d ./Lumina-T2X/models -o consolidated_ema.00-of-01.safetensors
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/ckpt/Lumina-Next-SFT/resolve/main/model_args.pth -d ./Lumina-T2X/models -o model_args.pth
#启动lumina做图软件做图
cd ./Lumina-T2X/lumina_next_t2i
python demo.py --ckpt ../models --ema
上面指令已经把Lumina的网页界面启动了,打开网页开始生成需要的人物。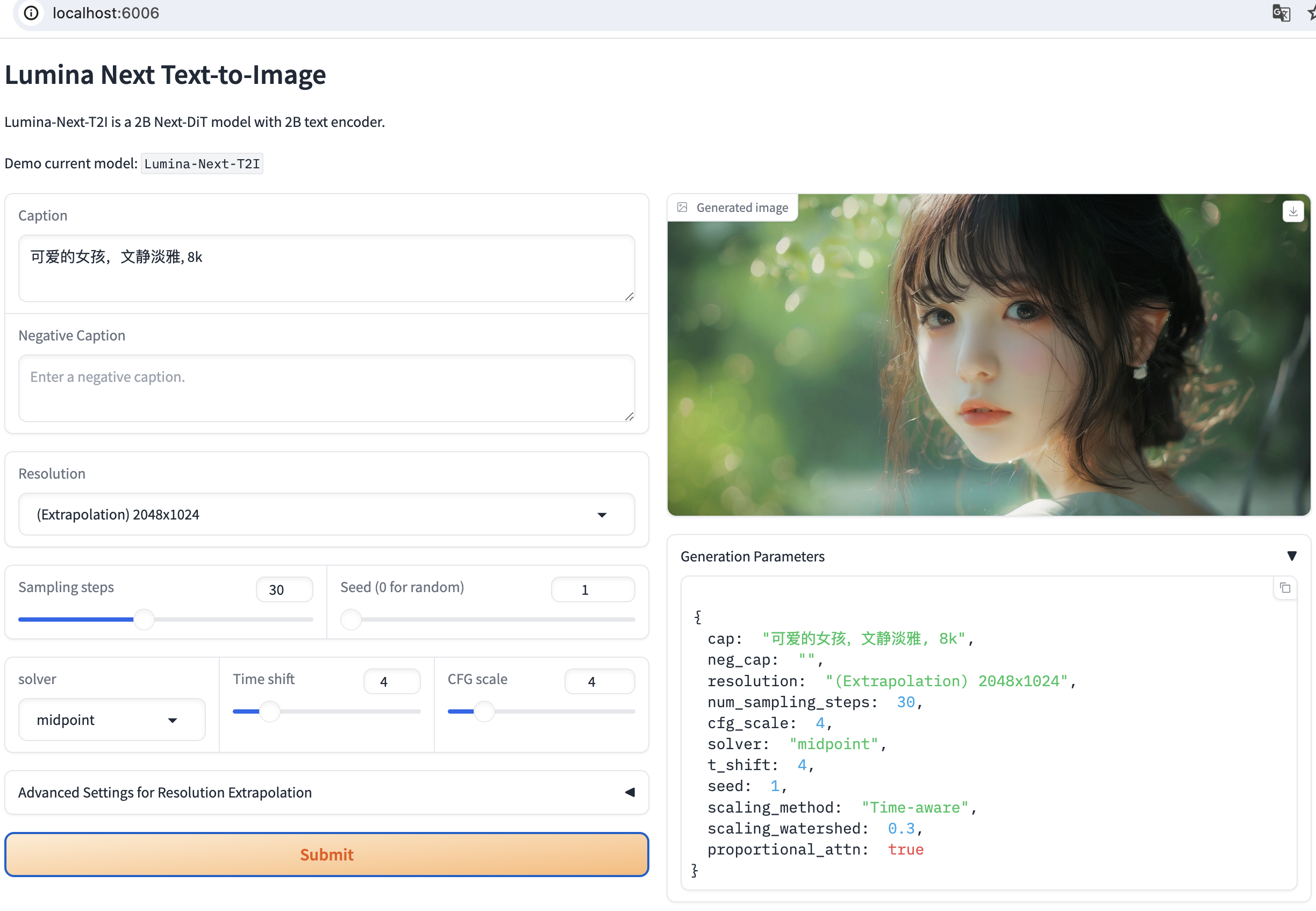
声音克隆模块
声音克隆现在是个热门,有很多可选的开源项目,效果做的都还不错。这边选用阿里通义CosyVoice来实践。
ubuntu安装git lfs
sudo apt-get update
sudo apt-get install git-lfs
git lfs install
环境初始化设置
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
# If you failed to clone submodule due to network failures, please run following command until success
cd CosyVoice
git submodule update --init --recursive
conda create -n cosyvoice python=3.8
conda activate cosyvoice
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
# If you encounter sox compatibility issues
# ubuntu
sudo apt-get install sox libsox-dev
下载模型
# git模型下载,请确保已安装git lfs
mkdir -p pretrained_models
git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M
git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT
git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct
git clone https://www.modelscope.cn/speech_tts/speech_kantts_ttsfrd.git pretrained_models/speech_kantts_ttsfrd
安装包
#解压ttsfrd资源并安装ttsfrd包
cd pretrained_models/speech_kantts_ttsfrd/
unzip resource.zip -d .
pip install ttsfrd-0.3.6-cp38-cp38-linux_x86_64.whl
export PYTHONPATH=/root/autodl-tmp/CosyVoice/third_party/Matcha-TTS
export HF_ENDPOINT=https://hf-mirror.com/
启动语音clone软件
python3 webui.py --port 6006 --model_dir pretrained_models/CosyVoice-300M
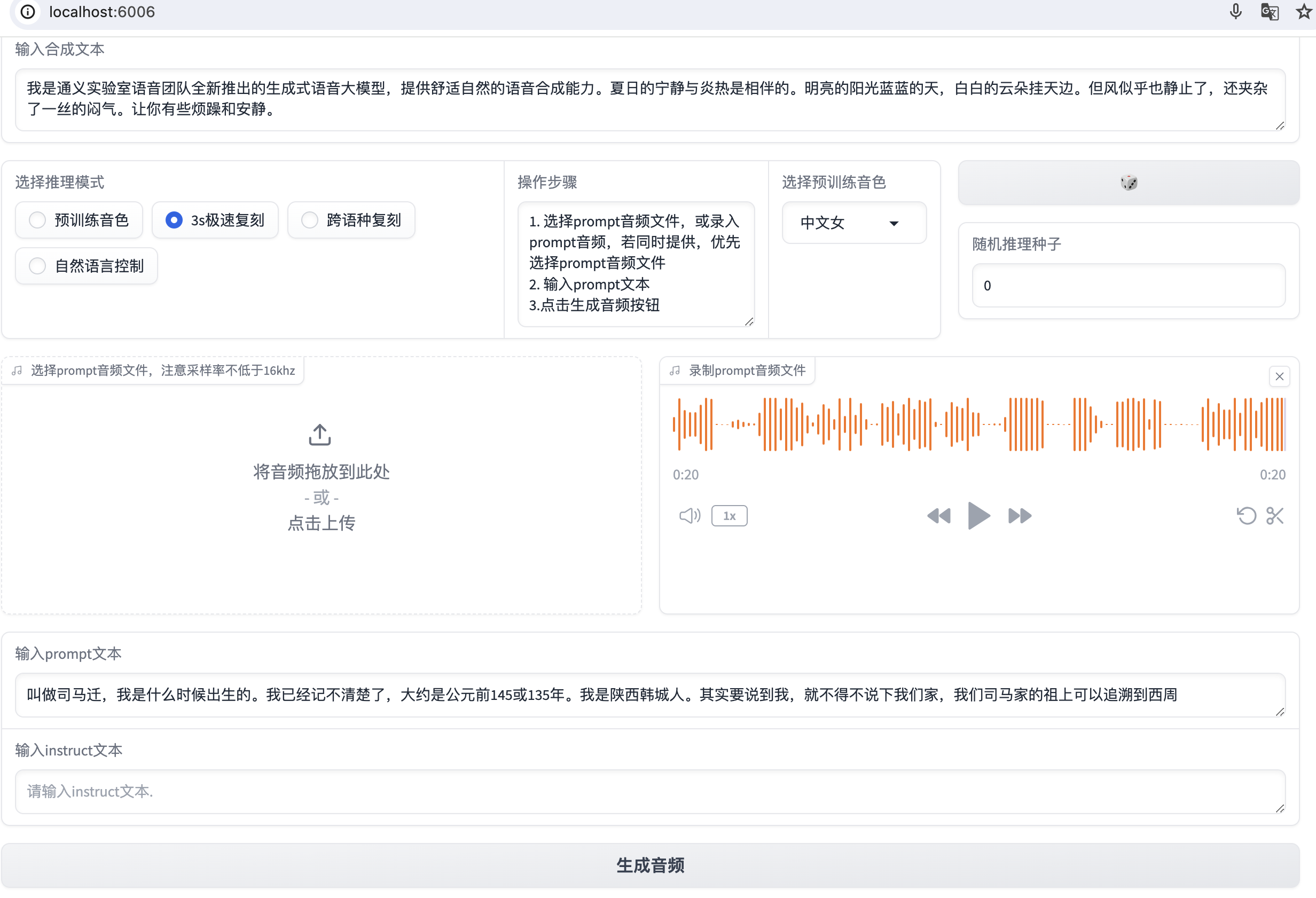
用录音或者上传你想要模仿的语音,并把语音文本输入prompt,输入需要生成语音文本生成clone语音;把合成的语音下载下来就可以了。
角色动作生成模块
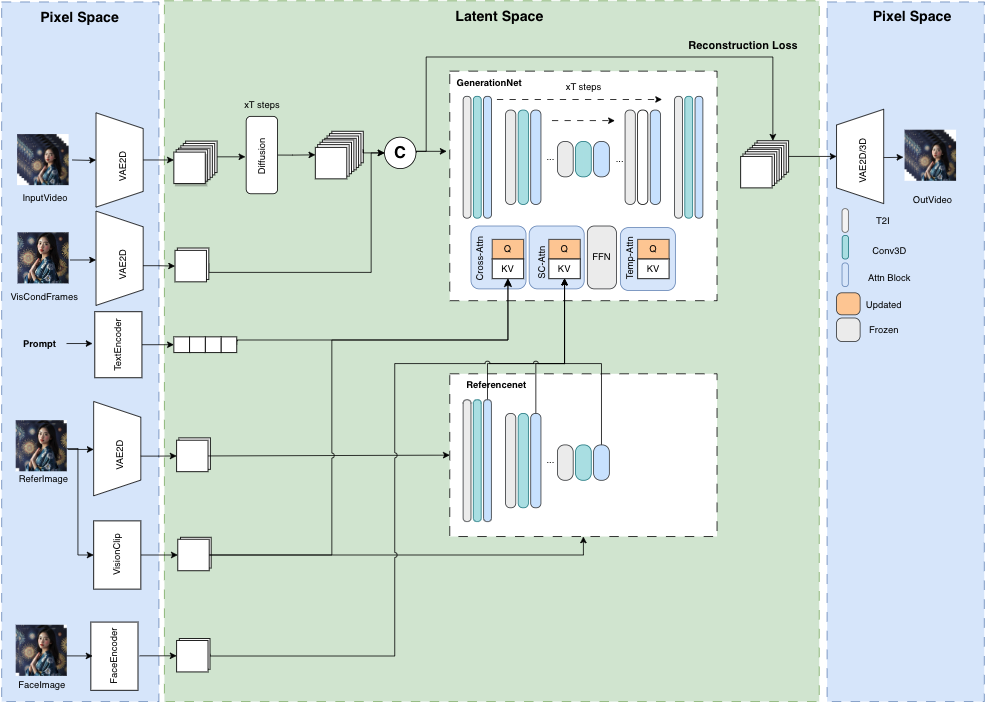
角色动作生成模块选择Musev来实现。MuseV 是基于扩散模型的虚拟人视频生成框架,具有以下特点:
- 支持使用新颖的视觉条件并行去噪方案进行无限长度生成,不会再有误差累计的问题,尤其适用于固定相机位的场景。
- 提供了基于人物类型数据集训练的虚拟人视频生成预训练模型。
- 支持图像到视频、文本到图像到视频、视频到视频的生成。
- 兼容 Stable Diffusion 文图生成生态系统,包括 base_model、lora、controlnet 等。
- 支持多参考图像技术,包括 IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID。
- 我们后面也会推出训练代码
git clone --recursive https://github.com/TMElyralab/MuseV.git
cd MuseV
#初始化环境
pip install -r requirements.txt
pip install --no-cache-dir -U openmim
pip install mmengine
pip install mmcv>=2.0.1
pip install mmdet>=3.1.0
pip install mmpose>=1.1.0
cd ..
current_dir=$(pwd)
export PYTHONPATH=${PYTHONPATH}:${current_dir}/MuseV
export PYTHONPATH=${PYTHONPATH}:${current_dir}/MuseV/MMCM
export PYTHONPATH=${PYTHONPATH}:${current_dir}/MuseV/diffusers/src
export PYTHONPATH=${PYTHONPATH}:${current_dir}/MuseV/controlnet_aux/src
cd MuseV
#下载模型
git clone https://huggingface.co/TMElyralab/MuseV ./checkpoints
#输入文本、图像的视频生成
python scripts/inference/text2video.py --sd_model_name majicmixRealv6Fp16 --unet_model_name musev -test_data_path ./configs/tasks/example.yaml --output_dir ./output --n_batch 1 --target_datas yongen --time_size 12 --fps 12
#输入视频的视频生成
python scripts/inference/video2video.py --sd_model_name majicmixRealv6Fp16 --unet_model_name musev -test_data_path ./configs/tasks/example.yaml --output_dir ./output --n_batch 1 --controlnet_name dwpose_body_hand --which2video "video_middle" --target_datas dance1 --fps 12 --time_size 12
#Gradio 演示
cd scripts/gradio
python app.py
上面模型下载会非常大,也可以挑选同类模型汇总一个,可以节省存储空间和下载时间。
!cg down O_O/MuseV/musev_____unet_____config.json
!cg down O_O/MuseV/musev_____unet_____diffusion_pytorch_model.bin
!cg down O_O/MuseV/musev_referencenet_____ip_adapter_image_proj.bin
!cg down O_O/MuseV/musev_referencenet_____unet_____config.json
!cg down O_O/MuseV/musev_referencenet_____unet_____diffusion_pytorch_model.bin
!cg down O_O/MuseV/musev_referencenet_____referencenet_____config.json
!cg down O_O/MuseV/musev_referencenet_____referencenet_____diffusion_pytorch_model.bin
!cg down O_O/MuseV/musev_referencenet_pose_____ip_adapter_image_proj.bin
!cg down O_O/MuseV/musev_referencenet_pose_____unet_____config.json
!cg down O_O/MuseV/musev_referencenet_pose_____unet_____diffusion_pytorch_model.bin
如果还是觉得麻烦可以直接上autodl用找社区musev镜像减少环境安装下载模型浪费的时间。
角色口型生成模块
这部分选用MuseTalk:实时高质量唇形同步与潜在空间修复。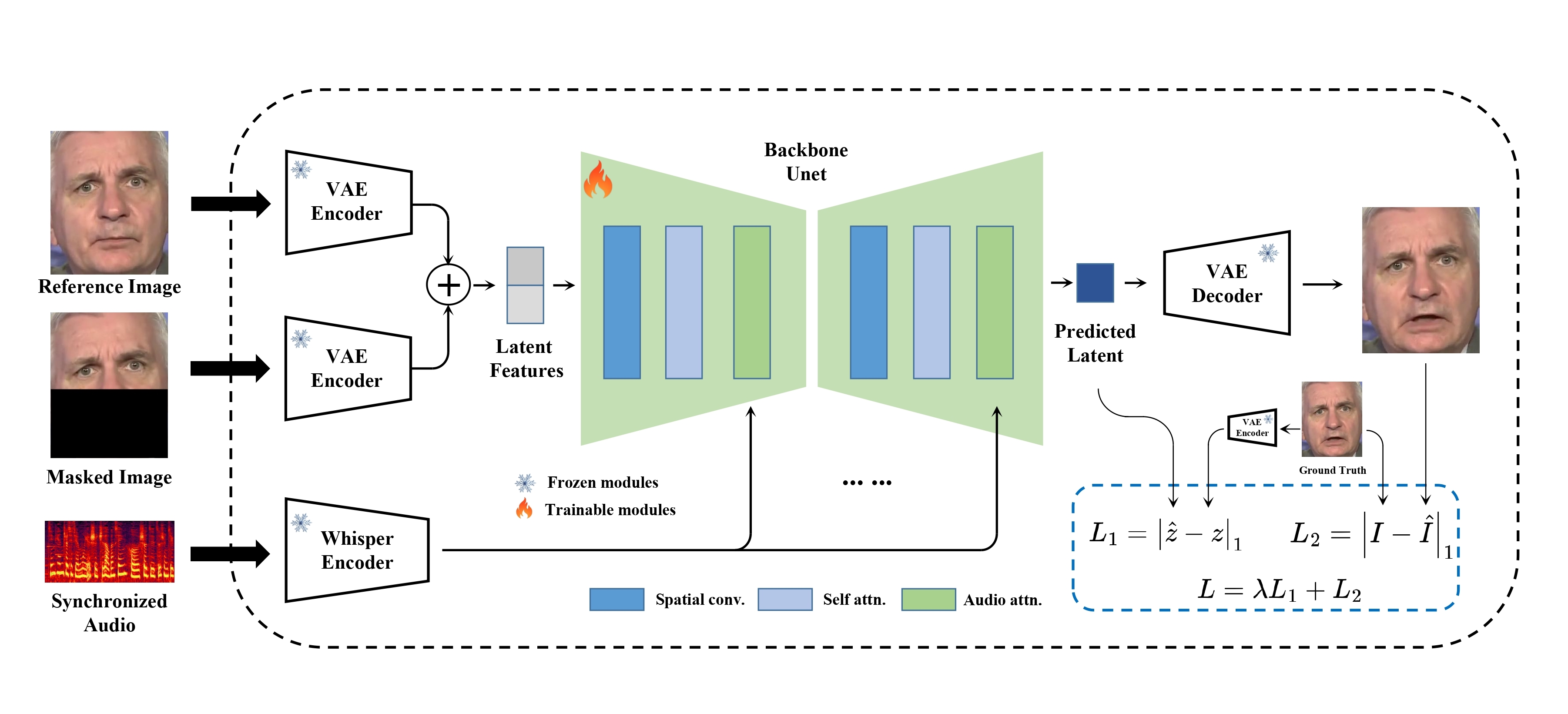
MuseTalk 在潜在空间中进行训练,其中图像由冻结的 VAE 进行编码。音频由冻结的 whisper-tiny 模型编码。生成网络的架构借鉴了 stable-diffusion-v1-4 的 UNet,其中音频嵌入通过交叉注意力融合到图像嵌入。
使用与稳定扩散非常相似的架构,但 MuseTalk 的不同之处在于它不是扩散模型。相反,MuseTalk 通过一步修复潜在空间来进行操作。
#下载项目文件
git clone https://github.com/TMElyralab/MuseTalk.git
cd ./MuseTalk
#初始化环境
pip install -q diffusers==0.27.2 accelerate==0.28.0 omegaconf ffmpeg-python mmpose mmdet gradio
pip install -q https://github.com/camenduru/wheels/releases/download/colab2/mmcv-2.1.0-cp310-cp310-linux_x86_64.whl
#下载模型
apt -y install -qq aria2
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/dw-ll_ucoco.pth -d ./MuseTalk/models/dwpose -o dw-ll_ucoco.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/dw-ll_ucoco_384.onnx -d ./MuseTalk/models/dwpose -o dw-ll_ucoco_384.onnx
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/dw-ll_ucoco_384.pth -d ./MuseTalk/models/dwpose -o dw-ll_ucoco_384.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/dw-mm_ucoco.pth -d ./MuseTalk/models/dwpose -o dw-mm_ucoco.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/dw-ss_ucoco.pth -d ./MuseTalk/models/dwpose -o dw-ss_ucoco.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/dw-tt_ucoco.pth -d ./MuseTalk/models/dwpose -o dw-tt_ucoco.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/rtm-l_ucoco_256-95bb32f5_20230822.pth -d ./MuseTalk/models/dwpose -o rtm-l_ucoco_256-95bb32f5_20230822.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/rtm-x_ucoco_256-05f5bcb7_20230822.pth -d ./MuseTalk/models/dwpose -o rtm-x_ucoco_256-05f5bcb7_20230822.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/rtm-x_ucoco_384-f5b50679_20230822.pth -d ./MuseTalk/models/dwpose -o rtm-x_ucoco_384-f5b50679_20230822.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/dwpose/yolox_l.onnx -d ./MuseTalk/models/dwpose -o yolox_l.onnx
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/face-parse-bisent/79999_iter.pth -d ./MuseTalk/models/face-parse-bisent -o 79999_iter.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/face-parse-bisent/resnet18-5c106cde.pth -d ./MuseTalk/models/face-parse-bisent -o resnet18-5c106cde.pth
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/raw/main/musetalk/musetalk.json -d ./MuseTalk/models/musetalk -o musetalk.json
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/musetalk/pytorch_model.bin -d ./MuseTalk/models/musetalk -o pytorch_model.bin
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/raw/main/sd-vae-ft-mse/config.json -d ./MuseTalk/models/sd-vae-ft-mse -o config.json
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/sd-vae-ft-mse/diffusion_pytorch_model.bin -d ./MuseTalk/models/sd-vae-ft-mse -o diffusion_pytorch_model.bin
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/sd-vae-ft-mse/diffusion_pytorch_model.safetensors -d ./MuseTalk/models/sd-vae-ft-mse -o diffusion_pytorch_model.safetensors
aria2c --console-log-level=error -c -x 16 -s 16 -k 1M https://huggingface.co/camenduru/MuseTalk/resolve/main/whisper/tiny.pt -d ./MuseTalk/models/whisper -o tiny.pt
#启动可视化界面
python app.py
到这你就已经拥有一个数字人工具了,至于输入的文本你也可以用AI来生成。当然现在还是一个一个的模块如果你需要批量的生成数字人视频或者批量的翻译视频、弹唱配视频。那你可以把这些链路用comfyui分成5个模块串接起来就可以了,这就是一个标准的AI native的数字人生成工具了。
小结
2024年世界人工智能大会(WAIC)参会感受
- 参会人员多样化:2024年的WAIC参会人员包括销售、技术、算法、研究人员、产业实践方等各类角色,相比去年更加多样化。
- 应用和实践报告增多:今年的会议中,应用和实践报告的数量明显增加,各大公司争相发布自己的AI产品。
- 会议主题聚焦:主要围绕大模型和人形机器人两大主题展开,各公司在努力结合自身产业特点创造差异化的产品和思路。
- AI在教育上的应用:AI在教育上的应用表现较为成熟和实用,这可能得益于国家在教育数字化方面的推动。
AI Native应用系列的设想
- 目的:为有很强业务sence的企业在寻找技术赋能、找一些可用工具的时候降低他们门槛,让他们可用快速的把工具结合自己业务测试起来。
- 内容:只讲实现落地,纯AI技术的整合,更偏向工具实现,不讲AI背后技术的原理,也不太讲具体某个行业业务逻辑。
AI Native的数字人工具操作手册
- 环境搭建:使用conda创建并激活名为lumina的虚拟环境,使用Python 3.11版本。
- 单图生成模块:使用上海人工智能研究所的Lumina架构进行图像生成。
- 声音克隆模块:使用阿里通义的CosyVoice进行声音克隆。
- 角色动作生成模块:使用MuseV进行角色动作生成。
- 角色口型生成模块:使用MuseTalk进行角色口型生成。
- 整合与应用:将这些模块整合起来,可以构建一个AI Native的数字人工具,用于生成数字人视频、翻译视频、弹唱配视频等应用。
项目代码更新在
GitHub - liangwq/Chatglm_lora_multi-gpu: chatglm多gpu用deepspeed和