MySQL 索引你必须知道的那些事
- 一、什么是索引?
- 二、索引相关命令演示
- 三、添加索引的条件
- 四、索引失效的几种情况
- 五、索引背后的数据结构
- 1、概述
- 2、B树
- 3、B+树
- 4、如果一个表中有多个索引(回表现象)
一、什么是索引?
索引是在数据库表的字段上添加的,是为了提高查询效率存在的一种机制。一张表的一个字段可以添加一个索引,当然,多个字段联合起来也可以添加索引。索引相当于一本书的目录,是为了缩小扫描范围而存在的一种机制。
对于一本字典来说,查找某个汉字有两种方式:
(1)第一种方式:一页一页挨着找,直到找到为止,这种查找方式属于全字典扫描。效率比较低。
(2)第二种方式:先通过目录(索引)去定位一个大概的位置,然后直接定位到这个位置,做局域性扫描,缩小扫描的范围,快速的查找。这种查找方式属于通过索引检索,效率较高。
二、索引相关命令演示
以下索引操作均针对下表:
create table student(
SID int primary key,
SNAME varchar(255),
SLOC varchar(255)
);

创建索引
create index 索引名 on 表名(字段名);
create index student_sname_index on student(sname);
给student表的sname字段添加索引,起名:student_sname_index

查看索引
show index from 表名;
show index from student;
查看student表的索引

删除索引
drop index 索引名 on 表名;
drop index student_sname_index on student;
将student表上的student_sname_index索引对象删除。

explain 查询语句
explain 可以查看 SQL 执行计划,这里就可以查看一个SQL语句是否使用了索引进行检索:
explain select * from student where sloc = "北京";
explain select * from student where sname = '张三';
explain select * from student where sid = '10';
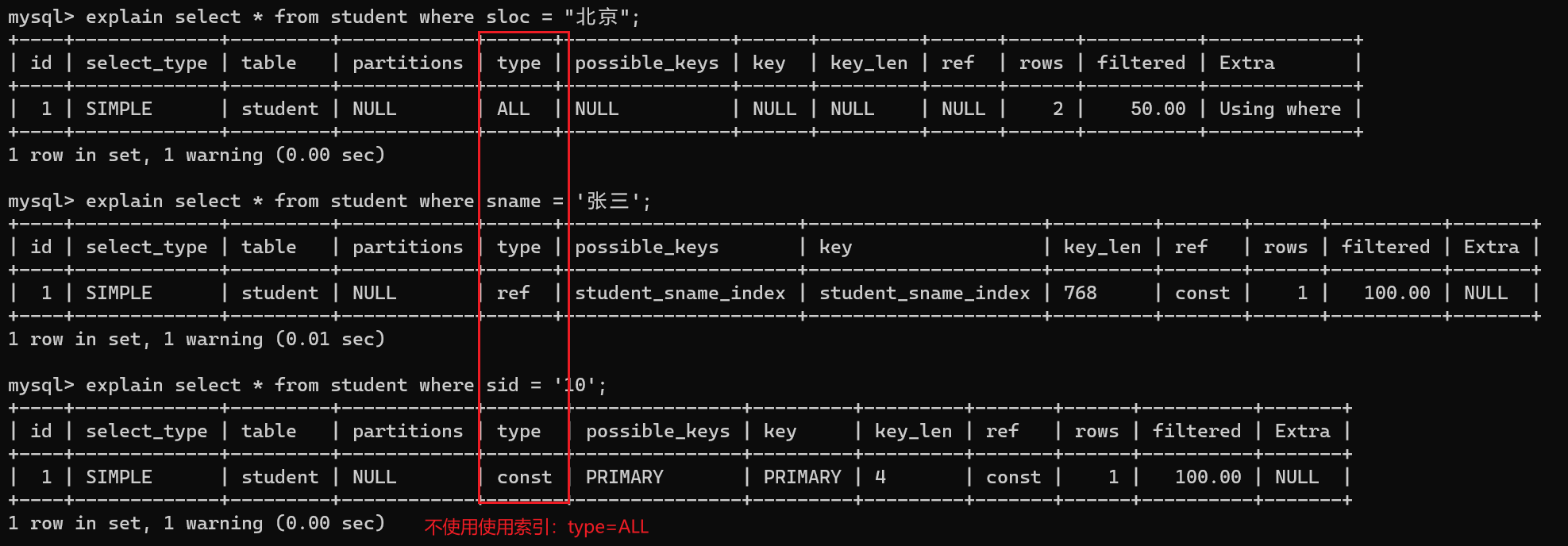
注意:在 mysql 当中,主键(PK)上,以及 unique 字段上都会自动添加索引的。
三、添加索引的条件
什么条件下,我们会考虑给字段添加索引呢?
- 条件1: 数据量庞大(到底有多么庞大算庞大,这个需要测试,因为每一个硬件环境不同)
- 条件2: 该字段经常出现在 where 的后面,以条件的形式存在,也就是说这个字段总是被扫描。
- 条件3: 该字段很少的 DML(insert delete update) 操作。因为DML之后,索引需要重新排序,维护开销大。
使用索引注意事项:
- 建议不要随意添加索引,因为索引也是需要维护的,太多的话反而会降低系统的性能。
- 建议通过主键或通过 unique 约束的字段进行查询,效率是比较高的。
- 如果表里的数据很大,建立索引的开销也会很大。好的做法是创建表之初就把索引设定好。
四、索引失效的几种情况
提示:此时 SID 和 SNAME 均有索引
1、模糊匹配当中以“%”开头。
explain select * from student where sname like '%张';

2、不合理使用 or
使用 or 的时候会失效,如果使用 or ,那么要求 or 两边的条件字段都要有索引,才会走索引,如果其中一边有一个字段没有索引,那么另一个字段上的索引也会失效。所以不建议使用 or 建议 union。
explain select * from student where sname = '张三' or sloc = '北京';

3、在where当中索引列参加了运算,索引失效。
explain select * from student where sid+10 = 20;

4、在where当中索引列使用了函数。
explain select * from emp where upper(sname) = 'JACK';

五、索引背后的数据结构
1、概述
在实际中,汉语字典前面的目录是排序的,按照a b c d e f…排序,为什么排序呢?因为只有排序了才会有区间查找这一说!在mysql数据库当中索引也是需要排序的,因此索引底层需要维护一种用于排序查询的数据结构,我们知道二叉搜索树,平衡二叉树和哈希表均可用于查询,那么MySQL索引底层为什么不采用以上数据结构呢?正是因为它们都存在一定的缺陷:
- 二叉搜索树:二叉搜索树有良好的查找和插入性能,但是二叉查找树构建可能极不平衡,甚至会导致时间复杂度退化到O(n),就会极大增加IO次数,大大降低查找性能。
- 平衡二叉树:平衡二叉树解决了二叉搜索树可能高度不平衡的问题,比普通二叉搜索树更优秀的平均性能,但是随着数据规模增大,树的高度仍然会变得很高,IO次数就会增多,导致性能下降。
- 哈希表:哈希表虽然是O(1)时间复杂度查询,但是最大的问题在于只能进行key值相等的比较,如果想进行诸如大于小于的范围比较,或模糊匹配哈希表都是无能为力的。(不对索引进行排序)
因此为了解决以上缺陷,我们引入了B树又叫B-树(B杠树)和B+树。在MySQL中,索引的底层使用的是B+树的数据结构。又或叫做下面我们就简单了解一下B树和B+这两种数据结构。
2、B树
B树是一种多路搜索树,可以认为是一颗N叉搜索树,一个m 阶的B树指的是一个节点最多拥有 m 个孩子节点,而不是指的树的高度,即3阶 B-tree 是每个节点都最多拥有3个孩子节点。对于B树的定义比较复杂,咱们直接看图:
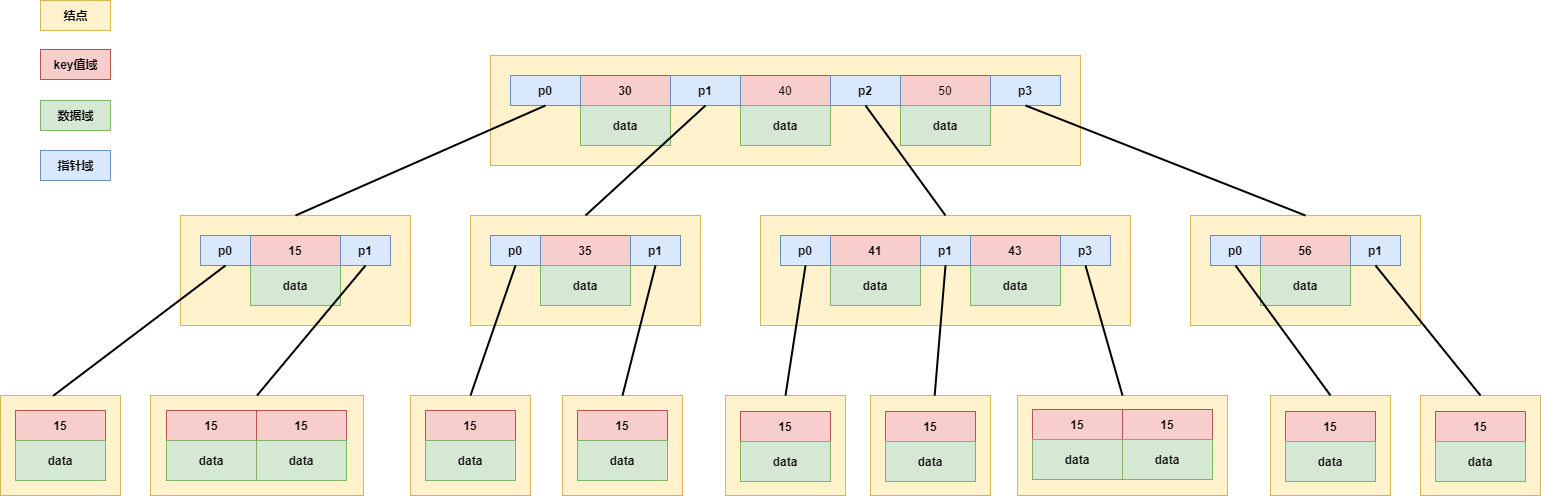
据上图,我们可以更清晰的观察到B树的特点:
- B树的每个结点可以存放N行记录,N行记录又可以根据key值划分出N+1个区间。即每个结点的每个记录的左子树存放比当前记录key值小的记录,右子树存放比当前记录大的记录。
- 由于B树的每个结点可以存放多个记录,那么同样的数据量的情况下,这种数据结构可以大大降低树的高度,减少了IO次数。
3、B+树
B+树是在B树的基础上做出了改进,其实也是一种多路搜索树。同样一图胜千言,我们直接看图:
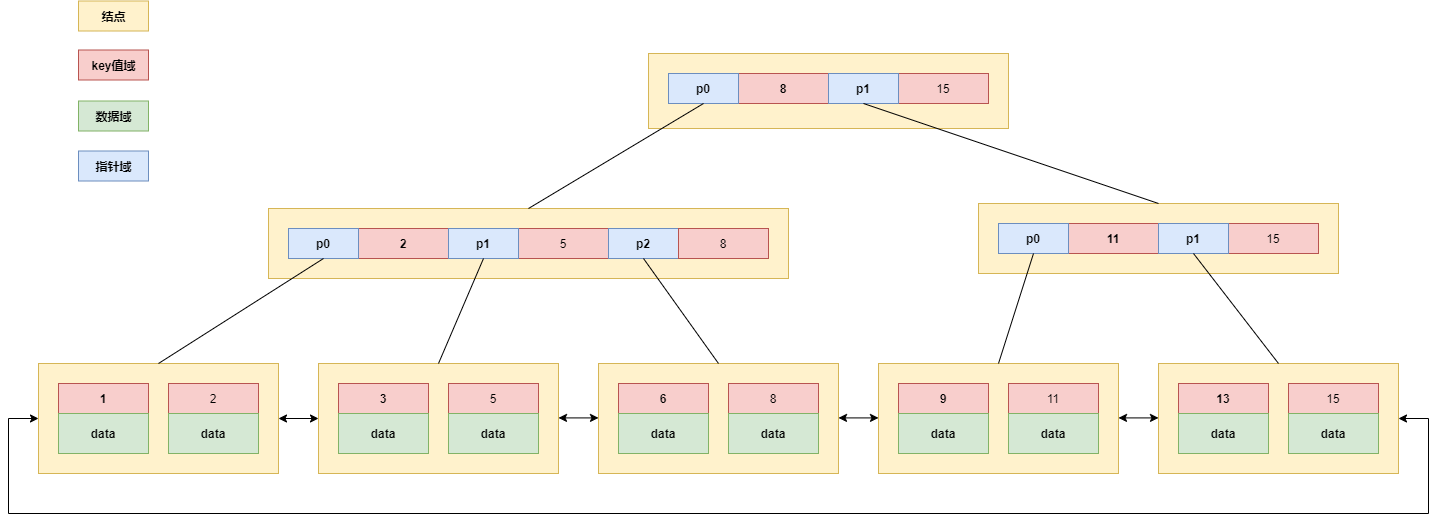
从图中我们不难总结出B+树特点:
- 一个结点可以存储N个key,N个key可以划分出N个区间。
- 每个节点中的key值都会在子节点中存在,同时key是当前子节点的最大值。
- B+树的叶子结点之间都有指针相连,在MySQL中优化成了循环链表。
- 在MySQL中,由于叶子结点是完整的数据集合,因此只在叶子结点中存储数据表的每一行数据,而非叶子结点只存储key值(索引)本身。
B+树在B树的基础上进行了改进,MySQL索引底层就是维护了一个B+树的数据结构。对于B+树相比于其他用于查询的数据结构,其优势是明显的:
- 首先它是在B树的基础上进行的迭代,具有一个节点保存更多的key的特点,这就导致相同数据量的情况下,最终树的高度是相对更矮的,查询的时候减少了IO访问次数。
- 所有的查询最终都会落到叶子结点上,查询任何一个数据,经过的IO访问次数是一样的,也就是说B+树的IO访问次数更加稳定,这可以让程序员对于程序的执行效率有一个更准确的评估。
- B+树的所有叶子节点构成链表,此时会比较方便进行范围查询。 例如参照上图,假设key值为ID,查询
ID>5 并且ID<11的同学,只需要先找到5所在的位置,再找到11所在的位置,之后在叶子结点中的5到11进行遍历,中间结果即为所求。- 对于B树,由于每个结点中都存放完整的数据,因此占用空间较大,由于内存空间有限,因此不适合在内存缓存。而B+树,所有的数据都在叶子节点上,非叶子结点只存储key(索引),导致非叶子结点占用空间比较小,这些非叶子结点就可能在内存中缓存,或者缓存一部分,这样之后在进行查询时就不用读取硬盘了,又进一步减少了IO次数。
4、如果一个表中有多个索引(回表现象)
假设有一个学生表student(ID,Name,Score),其中ID为主键,此时我们创建Name索引,进行查询时MySQL内部会出现如下现象:
MySQL内部会先以ID为主键,构建出B+树,通过叶子结点组织所有行。其次针对Name这一列,会构建另外一个B+树,但是这个B+树的叶子结点就不再存储这一行的完整数据,而是存主键ID。此时如果你根据name来查询,查到叶子结点得到的只是主键ID,还需要再通过主键ID的B+树里再查询一次。这个过程被称为
“回表”,是mysql自动完成的,用户感知不到。



















