上一篇:google gemini1.5 flash视频图文理解能力初探(一)提到了gemini 1.5 flash 可以对视频进行理解以及分析,但是整体在检索任务上效果不佳。
这几天参加了人工智能大会 + 网上收集,看一看有相似能力的一些技术点、创业团队有哪些
1 联汇科技 - OmAgent
现场Live震撼!OmAgent框架强势开源!行业应用已全面开花
我们正处于 L2 级别,并逐步向 L3、L4 迈进的过程中。

联汇科技全新发布了第二代思考大模型 OmChat V2,一个基于多模态模型原生预训练的生成大模型,不仅提供 8B、40B、60B 多个版本,适配不同需求。更能非常好地支持视频、图文混合、文字等多种复杂输入,完美适配智能体决策过程中所需要的复杂场景。

OmChat V2 支持高达 512K、50 万的上下文长度,折合视频长度 30 分钟,仅次于 Google Gemin-1.5,并远超 GPT-4o 及微软 LLaVa-1.5。
OmChat V2 不仅能够看准时序关系,更能够看懂多图关系。



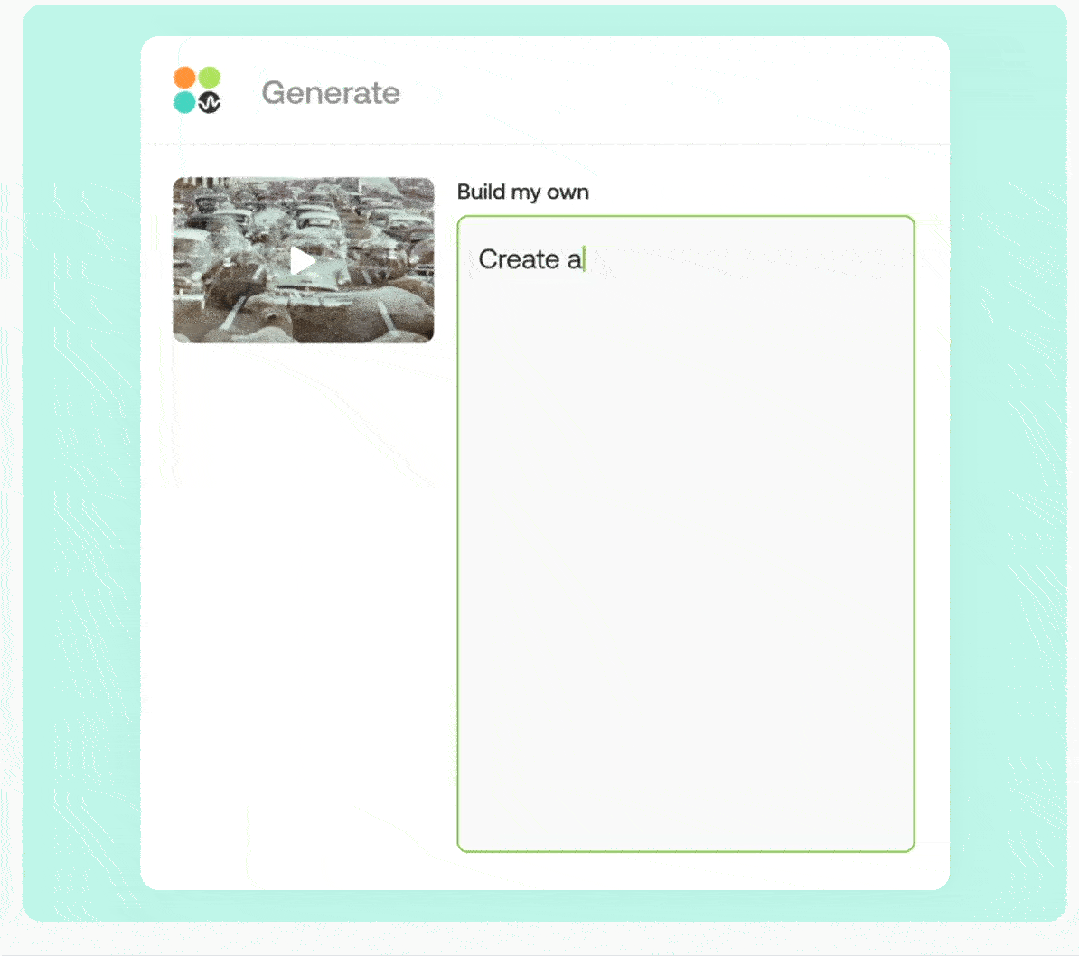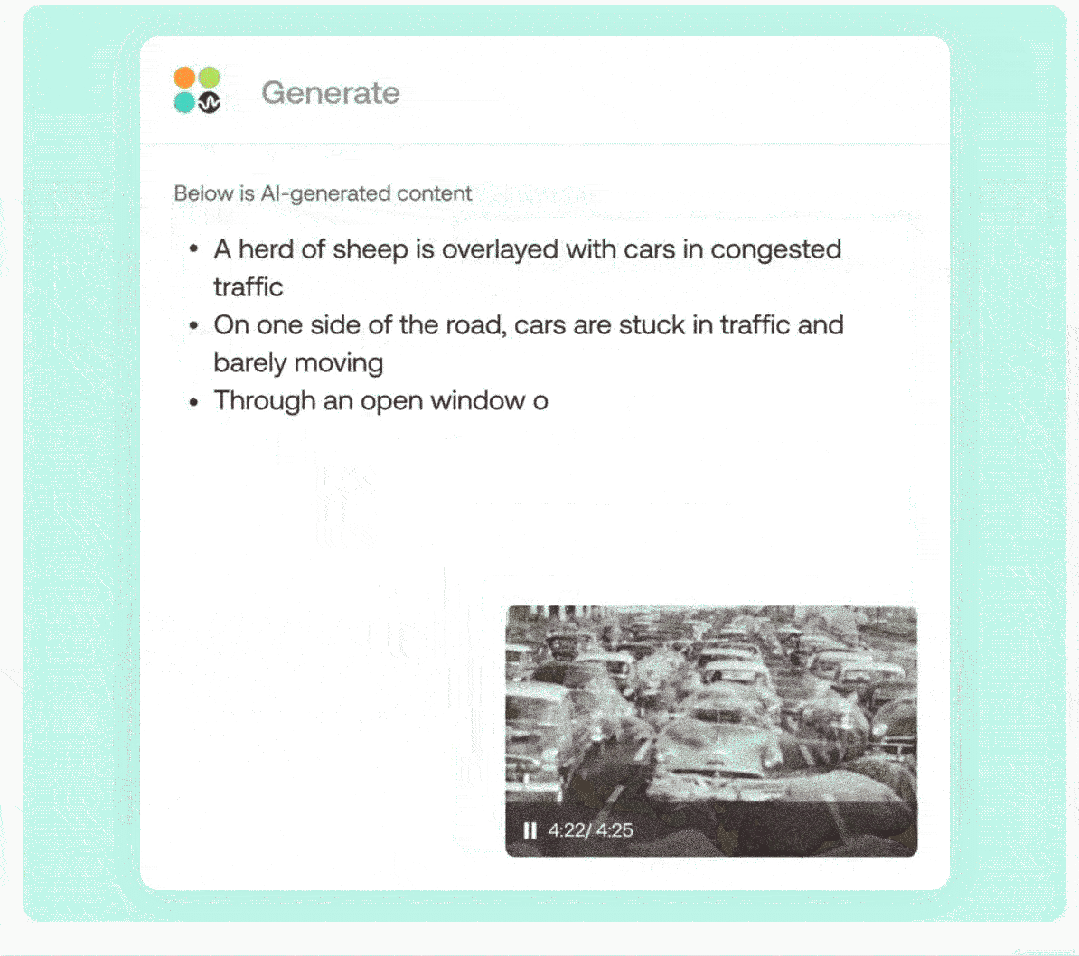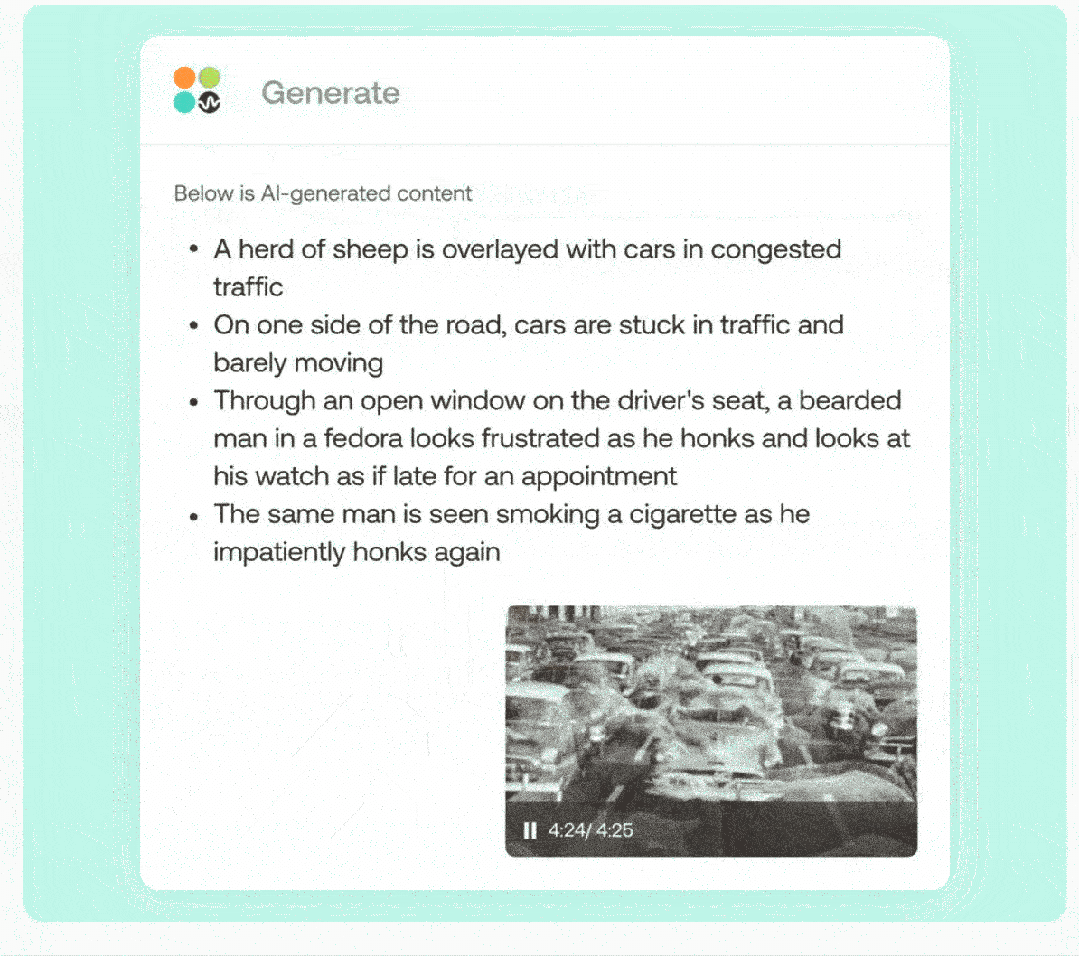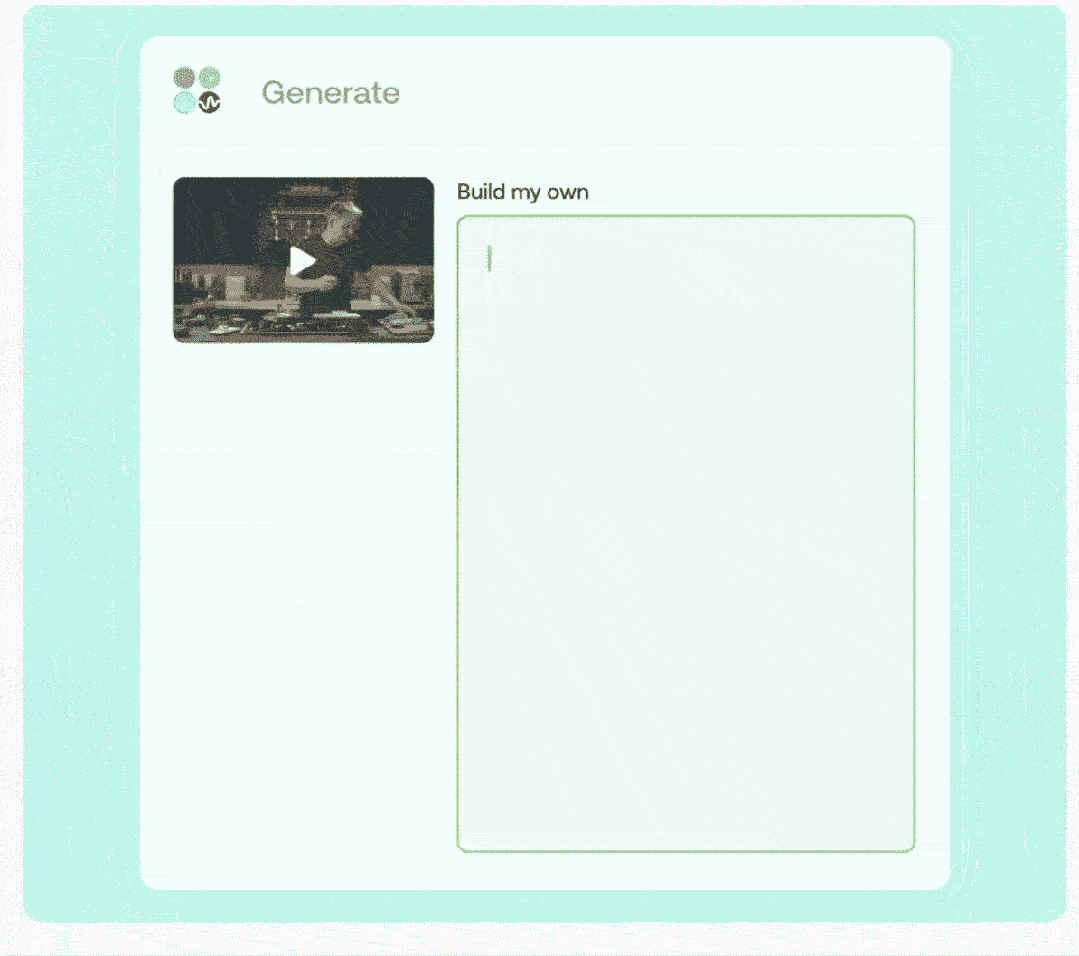
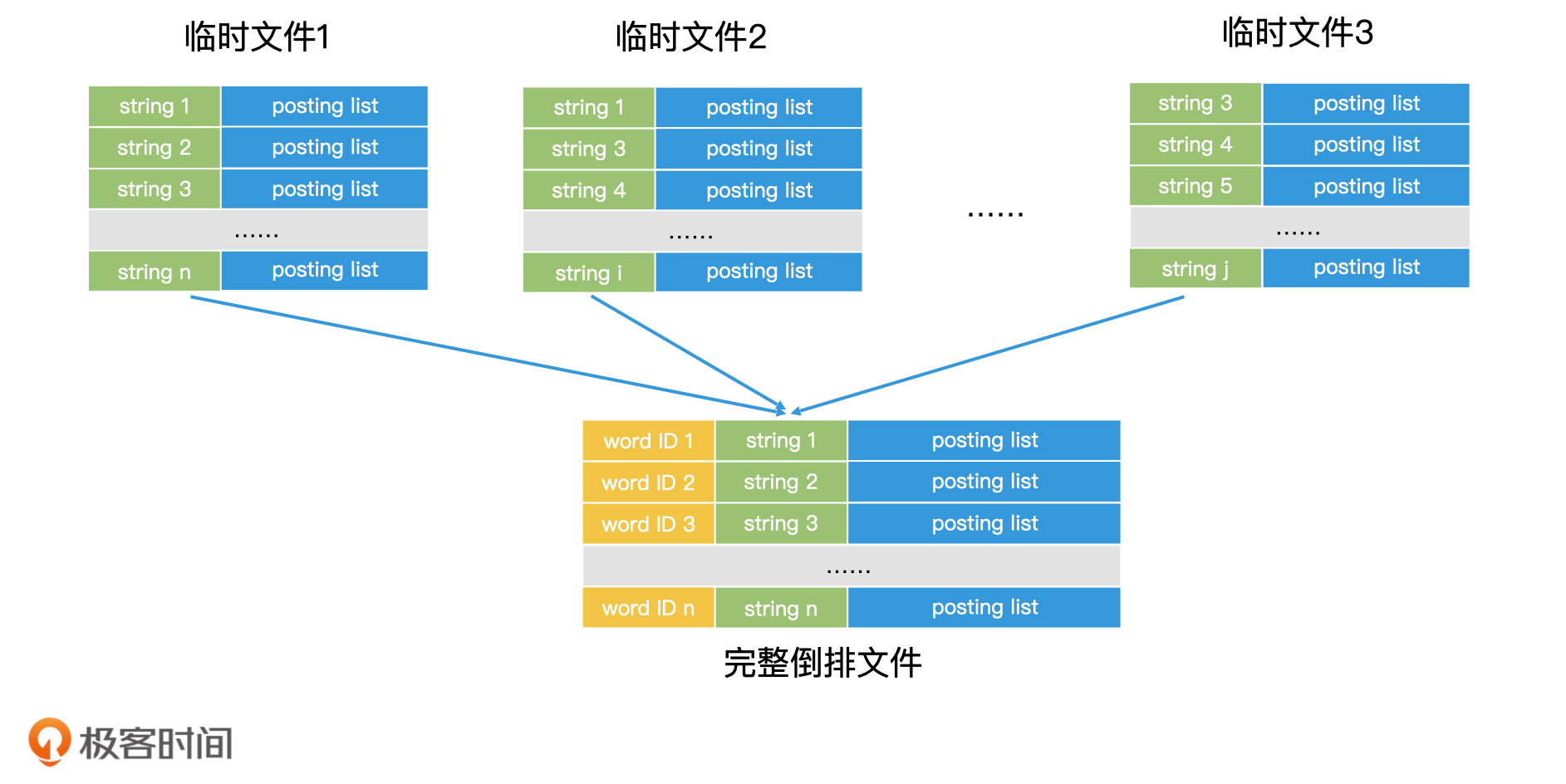
通过 OmAgent,能够快速、准确解决各类场景下的复杂问题。比如,从影视剧中总找出某个问题的答案,尽管影片没有直接呈现答案,但是 OmAgent 依然可以通过对全片的整体理解,掌握剧情并根据原片内容进行思考、作答。
2 Twelve Labs
AI+视频 | Nvidia 投资的AI公司,通过视频理解开创感知推理,获顶级风投5000万美元融资
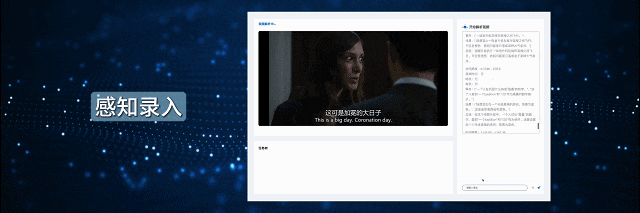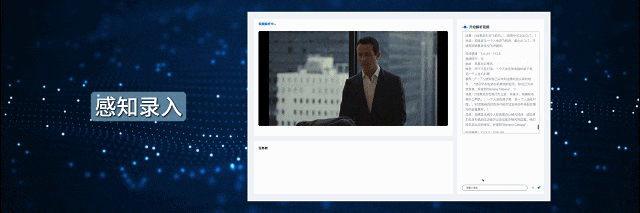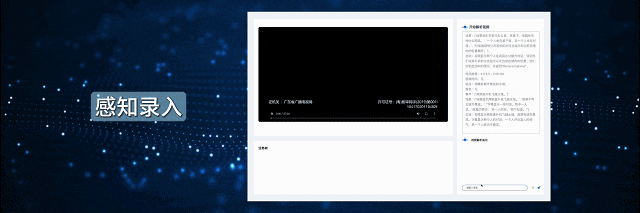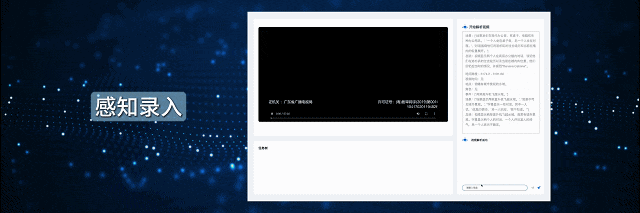
Twelve Labs,一家旧金山初创公司,是由一支年轻的工程师团队Jae Lee 和 Aiden L 创立,该产品可在视频中提取特定视频瞬间,包括视觉、音频、文本和上下文信息,以实现语义搜索、分析和洞察。该公司的愿景是创建用于多模式视频理解的基础设施,其自研模型可用于媒体分析并自动生成精彩片段。目前已被从多个顶级风投机构投资。
主要的产品功能,只需通过对接API就可以使用:
1、视频搜索
此模型分析视频的语义内容(Sematic search),包括视频,音频,Logo等数字材料,文字等全面分析场景关联性,以实现高效且准确的特定视频片段检索,帮助用户在无需观看完整内容的情况下精准搜索到大量来自Youtube, Tiktok,Reels等视频库的材料。

2、视频分类
该模型通过分析视频中的语义特征、对象和动作,将视频自动分类为预定义的类别,如体育、新闻、娱乐或纪录片。这增强了内容发现能力,并提供个性化推荐。同时,此功能基于内容相似性对视频进行分组,而不需要标签数据。它使用视频嵌入来捕捉视觉和时间信息,便于测量相似性并将相似视频进行归类。

3、视频-语言建模
该功能集成文本描述和视频内容,使模型能够理解并生成基于文本的摘要、描述或对视频内容的响应。它弥合了视觉和文本理解之间的差距。

4、视频描述和摘要
该模型生成自然语言描述和视频的简明摘要,捕捉关键信息和重要时刻。这改善了理解力和参与度,尤其适用于有视力障碍或时间限制的用户。还可以通过自由定义的prompt来生成不同侧重点的长文字型的视频总结,故事或者自媒体文章等。