文章目录
- 一、诞生背景
- 二、VGG网络结构
- 2.1VGG块
- 2.2网络运行流程
- 2.3总结
- 三、实战
- 3.1搭建模型
- 3.2模型训练
- 3.3训练结果可视化
- 3.4模型参数初始化
一、诞生背景

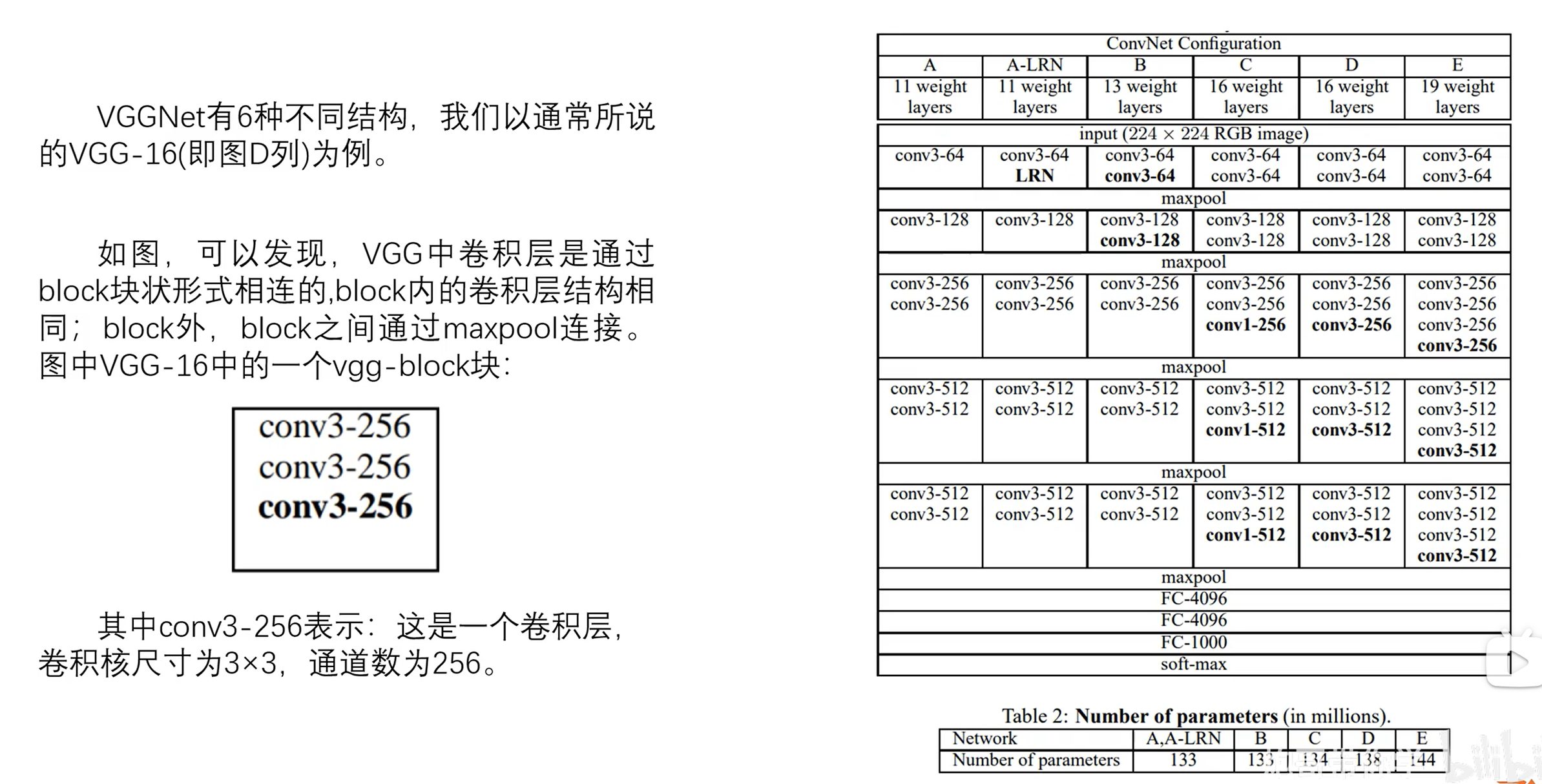
从网络结构中可看出,所有版本VGG均全部使用3×3大小、步长为1的小卷积核,3×3卷积核同时也是最小的能够表示上下左右中心的尺寸。
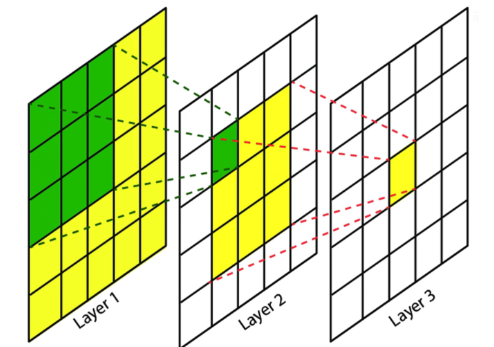
假设输入图像尺寸为假输入为5×5,使用2次3×3卷积后最终得到1×1的特征图,那么这个1×1的特征图的感受野为5×5。这和直接使用一个5×5卷积核得到1×1的特征图是一样的。也就是说2次3×3卷积可以代替一次5×5卷积同时,并且,2次3×3卷积的参数更少(2×3×3=18<5×5=25)而且会经过两次激活函数进行非线性变换,学习能力会更好。同样的3次3×3卷积可以替代一次7×7的卷积。并且,步长为1可以不会丢失信息,网络深度增加可以提高网络性能。
二、VGG网络结构
2.1VGG块

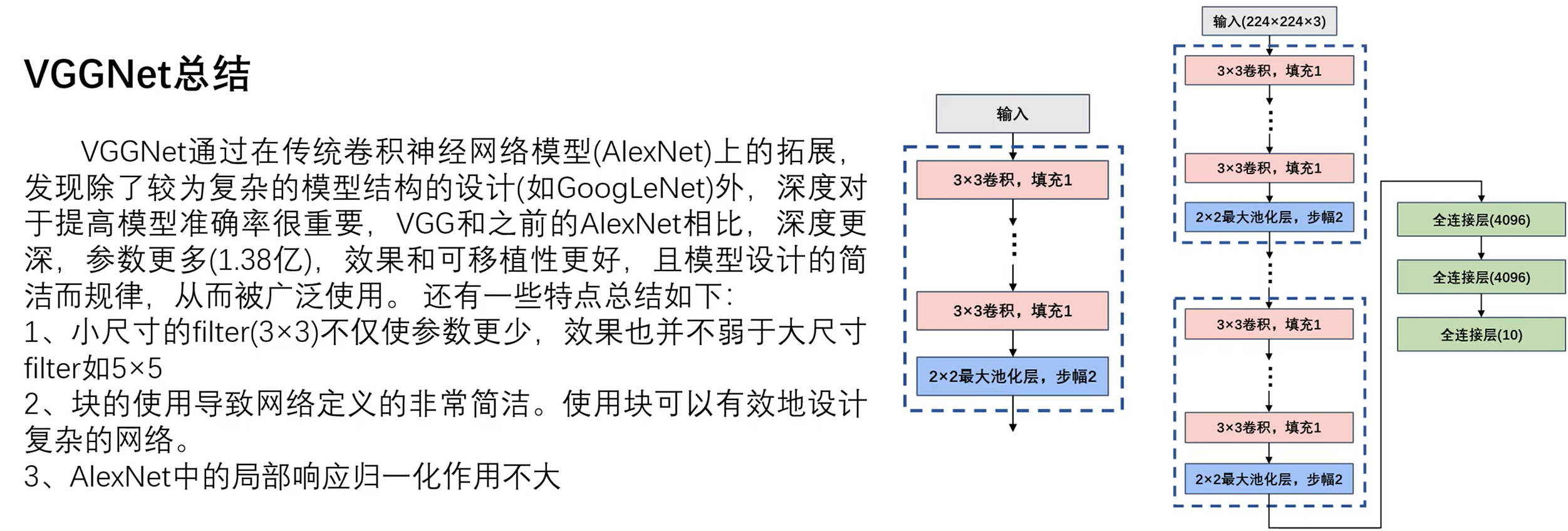
一个VGG_bolck的组成:
带填充以保持分辨率的卷积层:指对输入特征图卷积操作时会带有填充,使得只改变通道数而不改变图像高、宽。非线性激活函数ReLU:卷积操作后将特征图输入激活函数,提供使之具有非线性性。池化层、最大池化层:使用最大池化函数,不改变图像通道数,但会缩小图像尺寸。
对于卷积层、池化层有:
- 卷积层:使用3x3大小的卷积核,padding=1,stride=1,output=(input-3+2×1)/1+1=input,使得特征图尺寸不变。
- 池化层:使用2x2大小的核,padding=0,stride=2,output=(input-2)/2+1=1/2input,特征图尺寸减半。
2.2网络运行流程
输入层:输入大小为
(
224
,
224
,
3
)
(224,224,3)
(224,224,3)的RGB图像。





2.3总结
三、实战
3.1搭建模型
import torch
from torch import nn
from torchsummary import summary
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.block1 = nn.Sequential(
# 本案例中使用FashionMNIST数据集,所以输入通道数为1
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block3 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 10)
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.fc(x)
return x
model = VGG16().to(device)
summary(model, (1, 224, 224))

3.2模型训练
使用模板:
import torch
from torch import nn
import copy
import time
from torchvision.datasets import FashionMNIST
from torchvision import transforms
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch.utils.data as Data
train_data = FashionMNIST(root='./', train=True, download=True,
transform=transforms.Compose([transforms.Resize(size=224), transforms.ToTensor()]))
def train_val_process(train_data, batch_size=128):
train_data, val_data = Data.random_split(train_data,
lengths=[round(0.8 * len(train_data)), round(0.2 * len(train_data))])
train_loader = Data.DataLoader(dataset=train_data,
batch_size=batch_size,
shuffle=True,
num_workers=8)
val_loader = Data.DataLoader(dataset=val_data,
batch_size=batch_size,
shuffle=True,
num_workers=8)
return train_loader, val_loader
train_dataloader, val_dataloader = train_val_process(train_data, batch_size=64)
def train(model, train_dataloader, val_dataloader, epochs=30, lr=0.001, model_saveName=None, model_saveCsvName=None ):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = nn.CrossEntropyLoss()
model = model.to(device)
# 复制当前模型的参数
best_model_params = copy.deepcopy(model.state_dict())
# 最高准确率
best_acc = 0.0
# 训练集损失函数列表
train_loss_list = []
# 验证集损失函数列表
val_loss_list = []
# 训练集精度列表
train_acc_list = []
# 验证集精度列表
val_acc_list = []
# 记录当前时间
since = time.time()
for epoch in range(epochs):
print("Epoch {}/{}".format(epoch + 1, epochs))
print("-" * 10)
# 当前轮次训练集的损失值
train_loss = 0.0
# 当前轮次训练集的精度
train_acc = 0.0
# 当前轮次验证集的损失值
val_loss = 0.0
# 当前轮次验证集的精度
val_acc = 0.0
# 训练集样本数量
train_num = 0
# 验证集样本数量
val_num = 0
# 按批次进行训练
for step, (x, y) in enumerate(train_dataloader): # 取出一批次的数据及标签
x = x.to(device)
y = y.to(device)
# 设置模型为训练模式
model.train()
out = model(x)
# 查找每一行中最大值对应的行标,即为对应标签
pre_label = torch.argmax(out, dim=1)
# 计算损失函数
loss = criterion(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 累计损失函数,其中,loss.item()是一批次内每个样本的平均loss值(因为x是一批次样本),乘以x.size(0),即为该批次样本损失值的累加
train_loss += loss.item() * x.size(0)
# 累计精度(训练成功的样本数)
train_acc += torch.sum(pre_label == y.data)
# 当前用于训练的样本数量(对应dim=0)
train_num += x.size(0)
# 按批次进行验证
for step, (x, y) in enumerate(val_dataloader):
x = x.to(device)
y = y.to(device)
# 设置模型为验证模式
model.eval()
torch.no_grad()
out = model(x)
# 查找每一行中最大值对应的行标,即为对应标签
pre_label = torch.argmax(out, dim=1)
# 计算损失函数
loss = criterion(out, y)
# 累计损失函数
val_loss += loss.item() * x.size(0)
# 累计精度(验证成功的样本数)
val_acc += torch.sum(pre_label == y.data)
# 当前用于验证的样本数量
val_num += x.size(0)
# 计算该轮次训练集的损失值(train_loss是一批次样本损失值的累加,需要除以批次数量得到整个轮次的平均损失值)
train_loss_list.append(train_loss / train_num)
# 计算该轮次的精度(训练成功的总样本数/训练集样本数量)
train_acc_list.append(train_acc.double().item() / train_num)
# 计算该轮次验证集的损失值
val_loss_list.append(val_loss / val_num)
# 计算该轮次的精度(验证成功的总样本数/验证集样本数量)
val_acc_list.append(val_acc.double().item() / val_num)
# 打印训练、验证集损失值(保留四位小数)
print("轮次{} 训练 Loss: {:.4f}, 训练 Acc: {:.4f}".format(epoch+1, train_loss_list[-1], train_acc_list[-1]))
print("轮次{} 验证 Loss: {:.4f}, 验证 Acc: {:.4f}".format(epoch+1, val_loss_list[-1], val_acc_list[-1]))
# 如果当前轮次验证集精度大于最高精度,则保存当前模型参数
if val_acc_list[-1] > best_acc:
# 保存当前最高准确度
best_acc = val_acc_list[-1]
# 保存当前模型参数
best_model_params = copy.deepcopy(model.state_dict())
print("保存当前模型参数,最高准确度: {:.4f}".format(best_acc))
# 训练耗费时间
time_use = time.time() - since
print("当前轮次耗时: {:.0f}m {:.0f}s".format(time_use // 60, time_use % 60))
# 加载最高准确率下的模型参数,并保存模型
torch.save(best_model_params, model_saveName)
train_process = pd.DataFrame(data={'epoch': range(epochs),
'train_loss_list': train_loss_list,
'train_acc_list': train_acc_list,
'val_loss_list': val_loss_list,
'val_acc_list': val_acc_list
})
train_process.to_csv(model_saveCsvName, index=False)
return train_process
model_saveName="VGG16_best_model.pth"
model_saveCsvName="VGG16_train_process.csv"
train_process = train(model, train_dataloader, val_dataloader, epochs=15, lr=0.001, model_saveName=model_saveName, model_saveCsvName=model_saveCsvName)
3.3训练结果可视化
def train_process_visualization(train_process):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(train_process['epoch'], train_process['train_loss_list'], 'ro-', label='train_loss')
plt.plot(train_process['epoch'], train_process['val_loss_list'], 'bs-', label='val_loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.subplot(1, 2, 2)
plt.plot(train_process['epoch'], train_process['train_acc_list'], 'ro-', label='train_acc')
plt.plot(train_process['epoch'], train_process['val_acc_list'], 'bs-', label='val_acc')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('acc')
plt.legend()
plt.show()
train_process_visualization(train_process)
训练后可能会出现如下结果:
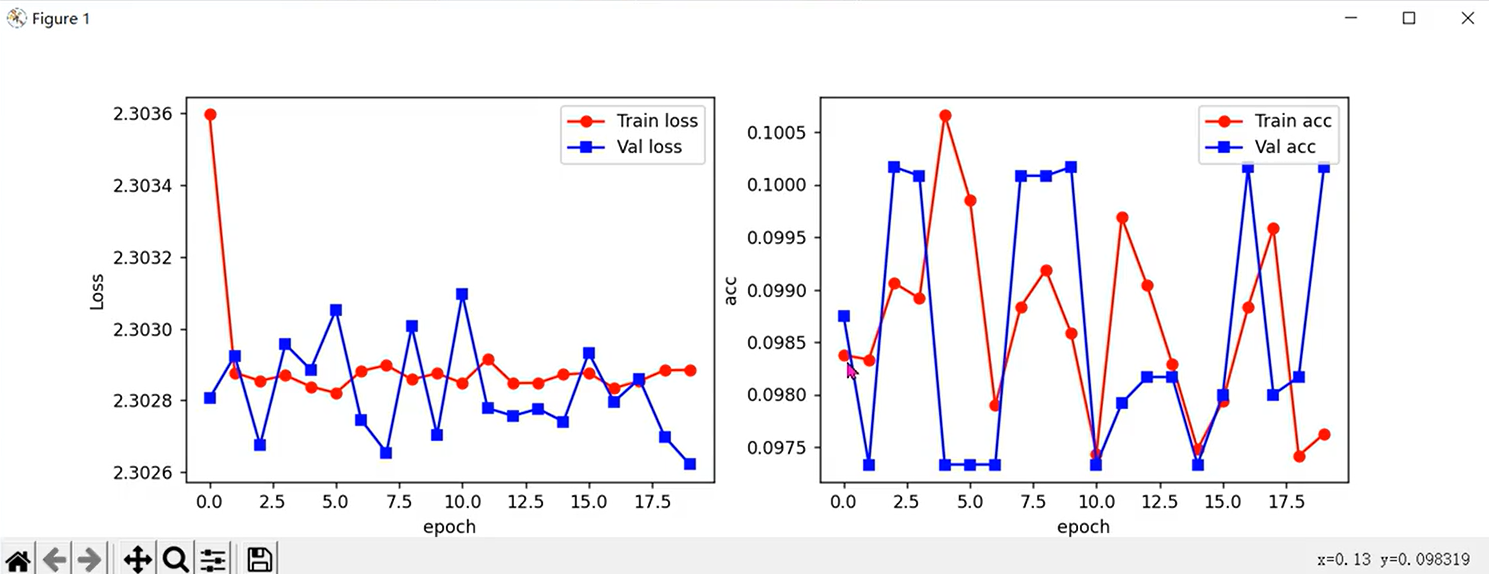
训练结果可能会时好时坏。事实上,VGG16共有16层网络,当进行反向传播从输出层向输入层运算时,可能会出现梯度消失使得参数无法收敛的情况。由于参数初始化是随机的,可能相对于真实值过大或过小,此时梯度消失就可能会使得参数值无法收敛。此时就需要按照一定的方式初始化参数。
3.4模型参数初始化
import torch
from torch import nn
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.block1 = nn.Sequential(
# 本案例中使用FashionMNIST数据集,所以输入通道数为1
nn.Conv2d(in_channels=1, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block3 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block4 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.block5 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 10)
)
# 参数初始化
for m in self.modules():
# 判断是否是具有参数的网络层,无参数就无需初始化
if isinstance(m, nn.Conv2d):
# Kaiming初始化方法常用于初始化卷积层参数w,需指定下一层使用的激活函数
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None: # 偏置项bias有约定俗成的初始化方式(初始化为0)
nn.init.constant_(m.bias, val=0)
elif isinstance(m, nn.Linear):
# 全连接层参数初始化往往使用正态分布的方式
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.zeros_(m.bias)
if m.bias is not None:
nn.init.constant_(m.bias, val=0)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.fc(x)
return x
model = VGG16().to(device)
事实上,批次大小会影响模型学习到的特征和参数更新的方向。较大的批次可以获得更稳定的梯度更新,但可能会丢失一些细节信息;较小的批次则可以捕捉到更细节的模式,但更新的梯度可能会更加不稳定。合理的批次大小选择可以在训练速度和模型性能之间达到平衡。一般的,建议批次大小为64、128左右,而若硬件性能不够,也可通过减少全连接层参数个数以换取较大的批次,因为全连接层参数过多,往往并不全都需要:
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(512 * 7 * 7, 256),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(128, 10)
)